
【編者按】Pivotal公司由EMC和Vmware部分業務分拆合并而成,Pivotal通過不斷吸收新技術并將新技術融合到自己的產品中而成長壯大,現在Pivotal還很好地利用開源力量完善自身的產品,Pivotal HD 2.0新版本整合了內存數據庫和眾多的分析功能,該版本的發布將會給Pivotal帶來更大的影響力,GigaOM的Barb Darrow將在下文為我們帶來了詳細的分析。
以下為譯文:
Pivotal努力整合并改進其母公司買來的大數據技術,以應對大數據企業級應用所面臨的挑戰。
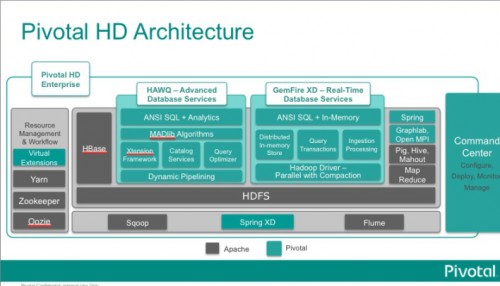
Pivotal是由VMware的Cloud Foundry和EMC的Greenplum等業務分拆并重組而成新公司,其目的是為企業帶來重新構建、嚴格測試過的Hadoop,該公司已將Apache Hadoop 2.2技術融入其新的Pivotal HD 2.0版本中,同時還在該版本中集成了內存數據庫GemFire XD。
GemFire通過云計算平臺虛擬化技術,將若干X86服務器的內存集中起來,組成最高可達數十TB的內存資源池,將全部數據加載到內存中,進行內存計算。計算過程本身不需要讀寫磁盤,只是定期將數據同步或異步方式寫到磁盤。GemFire在分布式集群中保存了多份數據,任何一臺機器故障,其它機器上還有備份數據,不用擔心數據丟失,而且有磁盤數據作為備份。
Pivotal希望利用穩定的技術為大公司提供一種數據解決方案,為大公司每分鐘產生的數據建立周期性良性反饋機制,比如手機運營商可以利用Pivotal HD和GemFire HD的大數據和分析能力來確定最快的呼叫路由,如果呼叫降級或失敗就將這些信息反饋回來進行處理,這樣可以及時解決問題。在一個完美的大數據環境下,及時向用戶道歉也能給客戶留下很好的影響。
受益于Apache Hadoop 2.2的更新,Pivotal HD 2.0現在將支持NFS和快照處理,這意味著企業客戶在出現問題時可以回滾。
Pivotal HD 2.0在數據庫性能方面也有了較大的改進,加強了HAWQ SQL查詢性能,其數據庫引擎其實是基于Greenplum數據庫并做了一些改進。HAWQ現在可以應用MADlib機器學習型庫中的50多種數據庫內算法,而且該數據庫引擎現在支持基于R、Python以及Java語言查詢和應用的自動翻譯,所以HAWQ可以用SQL很好的處理業務邏輯并對過程進行很好的控制。
Pivotal也許不是第一個從Apache更新獲益的商業公司,但它是第一個聲稱要對開源代碼做最嚴格測試的公司。Pivotal產品營銷部門的高級主管Michael Cucchi告訴我們:“我們采用Apache發行版并對其進行強化,為其進行我們自己的QA和回歸測試,也嘗試在1000個節點的集群上實現回滾操作,我們的測試是在大規模集群上完成的。”
Pivotal HD 2.0新版本為應對實時分析的需求集成了GemFire HD,而且還加入了GraphLab圖分析技術,為應對巨大的工作負載,新版本中也添加了改進后的HAWQ SQL查詢引擎。
這些都算不了什么――Pivotal只是將EMC和Vmware一系列收購中得到的技術整合到一起,使企業客戶可以方便地大規模部署Hadoop并從中獲得真正價值。比如HAWQ SQL查詢工具來自于EMC 2010年對Green Plum的收購;Gemfire來自于同年Vmware對GemStone的收購。
Cucchi告訴我們:“最初Pivotal HD軟件支持在裸機上運行,也可以在VMware環境中運行,還可以和硬件綁定在一起作為一種設備,但將來如果用戶想要在AWS或其他公有云上運行Pivotal HD也同樣可以。”
這的確是一個極好的機會,這使Pivotal甚至可以抗衡IBM這樣的IT巨頭以及Cloudera和HortonWorks這樣的新生Hadoop力量,換句話說,未來這些企業也將面臨Pivotal這樣強勁的對手。
原文鏈接:Pivotal spiffs up Hadoop and GemFire to meet enterprise big data challenges(編譯/毛夢琪 審校/魏偉)

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


