
隨著Facebook用戶數的增加,Facebook希望能夠測量基本的統計信息和高效地計算出用戶之間的關聯性,比如用戶位置、興趣愛好之間的關聯性以及他們之間的親和力、共同好友、查找潛在好友等信息。為了實現這些功能,他們采用一款開源的圖論工具――Apache Giraph。該工具最早出自雅虎,后來將其捐贈給 了Apache軟件基金會。

Giraph是一個高擴展性的交互圖形處理系統,Facebook對Giraph進行了改進和提升,實現對不同實體間的萬億個連接進行了分析。Facebook將Giraph規模化并作為其Open Graph工具的核心。Giraph的整體計算模型被運用在Facebook服務器內并行巨大的網絡圖計算。
Giraph是如何工作的?
Giraph是基于批量同步并行模型,由哈佛大學計算機教授Leslie Valiantz在20世紀80年代開發的一類并行計算算法。BSP算法通過 一系列步驟跨多臺計算機計算,在每一小步上,每臺計算機都執行一點計算,再把結果傳遞到其它系統里,這些系統再繼續執行下 一個步驟。
Giraph計算的輸入是由點和直連的邊組成的圖。例如,點可以表示人,邊可以表示朋友請求。每個頂點保存一個值,每個邊也保存一個值。輸入不僅取決于圖的拓撲邏輯,也包括定點和邊的初始值。 作為一個例子,考慮這樣一個計算,查找從一個預設的初始人到社交圖譜中的任何一個人的距離。在這個計算中,邊的值是一個浮 點數表示相鄰的人之間的距離,頂點V也是一個浮點數,表示從預設的頂點s到v的最短距離的上限值。預設的源頂點的初始值是0, 其它頂點的初始值是無窮大。
來自:Facebook
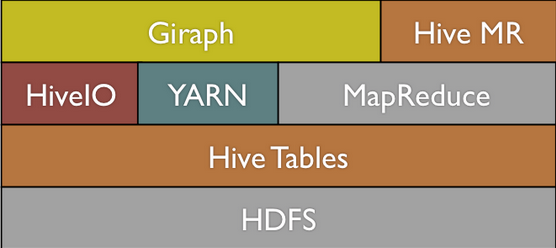
此外,Giraph引起大家關注的另一原因是基于Hadoop建立的,目前,很多企業都是Hadoop來部署大數據平臺,Facebook便是其中之一。
在Facebook使用Giraph之前,對于大規模圖形計算,人們曾使用諸如Hive和MapReduce等框架,它們可以實現大規模計算,但對比現在的計算速度,它們要慢50到100倍這樣。
發現人與人之間的關聯
舉一個最簡單的例子,Giraph使用手冊上例舉了一個實現單源最短路徑算法,一個計算方法是從所有收到的消息中計算最小的值,如果那個值節點的當前值小,那最小的那個就被接受作為頂點的值,而且值和邊的值就會沿著每一個外出的邊發送。
從邏輯上來講,任何節點之間的最短路徑一般只有該節點到其鄰居節點之間的距離。所以,基于Giraph模型,每個節點開始的第一步都是計算其最短路徑,然后通知其鄰居,如果其鄰居節點找到更短路徑,也會通知給開始節點,這樣,就很容易找到最短路徑。
在本月初,Facebook的一篇博客文章介紹了 Giraph是如何分配Facebook用戶數據到特定的數據庫服務器。當用戶朋友信息被存儲在同一個服務器上時,Facebook運行將會更高效,因為對于同樣的操作,跨服務查找的次數也會明顯減少。
Giraph為每個節點分配一個特定的設置,代表一個服務器,然后告訴其鄰居節點所在地。在每個步驟中,它隨機決定是否需要移動到另一組,與其鄰居移動的數量成正比。
Facebook在Giraph上取得的成效
作為一個迭代的圖形處理庫,Giraph具有容錯和動態調節的功能。
在可擴展方面,Facebook可以在擁有上萬億連接的真實的社交圖譜上運行一個迭代的頁面排名,這一社交圖譜由各類用戶在4分鐘之內交互產生,伴隨適當的碎片收集和性能調節。除此之外,還可以聚集Facebook每月的活躍用戶數據集,在幾分鐘內即可完成對如此大規模數據和變量的處理。
除圖譜搜索外,Facebook還計劃將Apache Giraph軟件用在其他任務中,例如精準廣告和數據排名。Facebook在社交領域的成功離不開其在技術領域的探索與創新,圖形技術的應用更是推動了Facebook的發展。
文章翻譯自:fastcolabs、gigaom

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


