
毫無疑問,一個大規模生產、分享和應用數據的時代逐漸朝我們走來。互聯網時代將我們帶入了一個以“PB”為單位的結構與非結構化數據信息時代。大數據之于企業、個人等是什么樣的存在不需要再贅述。
 訂閱“AWS中文技術社區”微信公眾號,實時掌握AWS技術及產品消息!
訂閱“AWS中文技術社區”微信公眾號,實時掌握AWS技術及產品消息!
AWS中文技術社區為廣大開發者提供了一個Amazon Web Service技術交流平臺,推送AWS最新資訊、技術視頻、技術文檔、精彩技術博文等相關精彩內容,更有AWS社區專家與您直接溝通交流!快加入AWS中文技術社區,更快更好的了解AWS云計算技術。
但是事實上我們還沒有完全準備好迎接如此量大、并且不規則的“非結構數據”,大數據時代下我們要如何更好的將這些大量、高速、多變的終端數據存儲下來,并隨時進行分享、分析、挖掘與計算?這是我們探索海量數據背后的真正價值所在的關鍵。本期活動我們邀請到了亞馬遜AWS中國解決方案架構師王毅和上海高欣-數據中心部技術總監周誠,與我們一起探索解決數據分析、數據挖掘及機器學習等問題。

分享會上,AWS中國解決方案架構師王毅帶來了主題為“大數據時代下的非結構化數據的管理與分析”的演講。演講中,他談到了數據的產生、收集和存儲,以及數據處理,同時分享了相關的客戶案例。

圖:AWS中國解決方案架構師王毅
在數字世界產生的1.2 ZB的數據中,95% 的數據都是非結構化的,大約70% 的內容都是用戶產生的(UGC),而且非結構化的數據以平均每年62%的速度爆發性增長,這就需要對這些數據加以分析,提取出對我們有用的數據。通過分析這些數據,可以了解客戶的需求、對財務建模及預測、欺詐檢測等方面。當然,這些數據可以從智能手機、平板電腦或者第三方數據(RSS)來獲取。而且獲取的數據格式不盡相同,除了結構化的數據和非結構化的數據外,可能還包括比如文本、二進制、準實時類型的數據。最后再對這些數據加以分析來獲取有價值的信息。
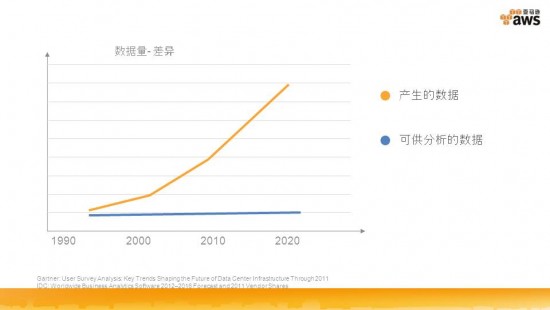
王毅談到了產生的數據和可供分析的數據之間的差異。他表示在獲取的大量數據面前,可以有效的加以利用的數據往往是微乎其微,而且在數據的收集和存儲的過程中,往往依賴于硬件的性能,性能越好,效率越高。
關于大數據與云計算之間的關系,王毅發表了自己的看法。“簡而言之,它們是天生一對的關系。”他說道,“由于大數據經常不是一個穩定的負載,它有高峰和低谷,因此需要彈性的計算來滿足大數據不斷變化的需求,剛好AWS非常適合負載變化大的應用場景,并且讓大數據更加的平民化。”
最后,王毅介紹了利用EMR分析數據具有容易使用、節約成本、彈性計算等優勢,對S3的基本工作原理進行了簡要的介。
王毅講義PPT下載:
http://download.csdn.net/detail/wangyp1230/7694823
來自于上海高欣數據中心部技術總監的周誠帶來了主題為“大數據時代下的機器學習”的演講,主要分享了數據分類問題和一個經典案例。
分享會上,周誠談到了兩種數據分類的方法――K-Mean聚類和信息熵。K-Mean聚類簡單地說就是把相似的東西分到一組,同分類不同是聚類通常需要你告訴它“這個東西被分為某某類”這樣一些例子。信息熵則是一個數學上的抽象概念,在這里可以把信息熵理解成某種特定信息的出現的概率。這兩方法對數據的聚類非常重要。
通過對信息的聚類,我們可以得到更加精簡的數據,這大大的提升了分析數據的效率,因此先給數據進行聚類后再進行分析是處理海量數據的重要手段。
接著,周誠介紹了語言模型。他認為語言模型的目的是建立一個能夠描述給定詞序列在語言中的出現的概率的分布,語言模型最開始誕生在語音識別領域,識別給定的語音信號對應的詞序列。但是隨著歷史信取值的不同衍生出:一元模型(Unigram)、二元模型(Bigram)、三元模型(Trigram)。
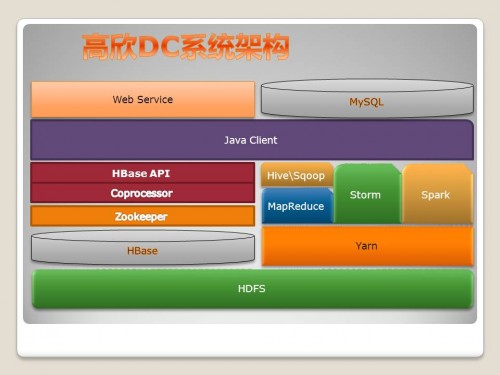
最后,周誠對DC系統構架做了簡單介紹。
周誠講義PPT下載:
http://download.csdn.net/detail/u013424982/7685481
如您需要了解AWS最新資訊或是技術文檔可訪問AWS中文技術社區;如您有更多的疑問請在AWS技術論壇提出,稍后會有專家進行答疑。

下一篇 一些常被你忽略的CSS小知識
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


