
【編者按】前段時間,Cloudera對比了Spark與Hadoop,取代MapReduce,宣布該公司將加大Spark的投入。實際上,Cloudera已經(jīng)開始了向Spark的遷移,其中包括了所有Hive SQL-on-Hadoop的部分。同時,Cloudera稱并不會使用Spark替換Impala,他們堅信Impala將是交互式SQL on Hadoop查詢的未來,處理Hive的速度遠超現(xiàn)有的所有軟件。

免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
CSDN作為國內(nèi)最專業(yè)的云計算服務(wù)平臺,提供云計算、大數(shù)據(jù)、虛擬化、數(shù)據(jù)中心、OpenStack、CloudStack、Hadoop、Spark、機器學習、智能算法等相關(guān)云計算觀點,云計算技術(shù),云計算平臺,云計算實踐,云計算產(chǎn)業(yè)資訊等服務(wù)。
以下為譯文:
這周的大數(shù)據(jù)排行榜上有很多關(guān)于Spark的新聞,同時還有一些猜測。來自Cloudera的Mike Olson說,他們公司正在廣泛擁抱Spark――包括運行Hive――但是不存在替換Impala行為。
對于計劃將Hive SQL-on-Hadoop引擎設(shè)置在Spark上引來的非議,Cloudera的聯(lián)合創(chuàng)始人兼首席戰(zhàn)略官Mike Olson的回應(yīng)是“并沒有什么改變”。也就是說,Cloudera的Impala的產(chǎn)品沒有發(fā)生任何變動。然而在Hadoop與Spark生態(tài)圈中,巨大的變化正在發(fā)生。
Olson表示,正如Cloudera所關(guān)注的那樣,Impala就是交互式SQL on Hadoop查詢的未來,Impala速度高于任何Hive相關(guān)產(chǎn)品,即使是Hortonworks出品。
Cloudera聯(lián)合IBM、MapR和Databricks(Spark發(fā)布公司)一起致力將Hive設(shè)置在Spark上。Hive的功能是企業(yè)迫切需要的,但運行在MapReduce上的Hive卻并不能滿足用戶需求。關(guān)于這一點,幾家公司已經(jīng)達成了共識。Olson堅持,Hive本質(zhì)就是一個運行在MapReduce上的批處理架構(gòu),雖然它在Spark或Hortonworks驅(qū)動的Apache Tez框架上運行的更快,但仍然是一個批處理作業(yè)。
他補充說,實際上,Cloudera等公司正致力于將幾乎現(xiàn)存的每一個MapReduce負載都轉(zhuǎn)移到Spark上,像Sqoop和Pig等,Spark具有美好的應(yīng)用前景,大家相信它將會在不遠的未來超過MapReduce。
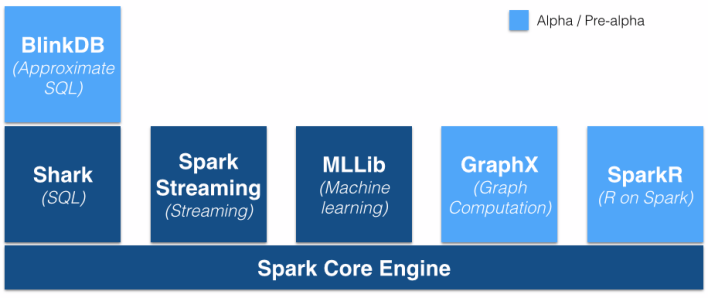
The Spark stack
有人可能會問Shark應(yīng)用在哪里。Olson承認Databricks將會把Shark推遲到下一次Spark發(fā)布會,這次峰會集中精力在一個公司四月份發(fā)布的叫做Spark SQL的項目上。
這段時間,Databricks 的CEO Ion Stoica對數(shù)據(jù)庫行業(yè)分析師Curt Monash同樣提到了繼續(xù)開發(fā)一個被稱為BlinkDB的交互引擎的項目,Ion Stoica說: “如果我要重繪Spark棧圖,SparkSQL將會取代Shark,而Shark則會介于SparkSQL和BlinkDB層面中間。”
Olson沒有提到BlinkDB,但是他說對于Spark SQL的想法他并不感到興奮。他承認,Databricks是一個有智慧的公司,也可能會用Spark SQL做一項很成功的任務(wù),但是他補充說,將Hive轉(zhuǎn)移到Spark上并不是一個快速的過程,因為SparkSQL仍是一個進展中的作品。
“我希望看到那些家伙能將他們的努力放在其他事情上”,他說“……我認為Spark框架中的Hive將會做的相當不錯”。
原文鏈接: Cloudera: Impala’s it for interactive SQL on Hadoop; everything else will move to Spark (編譯/史臣敏 責編/仲浩)

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


