
Jay Kreps是Linkedln的一名在線數(shù)據(jù)架構(gòu)技術(shù)高管,其負(fù)責(zé)Linkedln開源項(xiàng)目,包括Apache Kafka、Apache Samza、Voldemort以及Azkaban等項(xiàng)目。在日常工作中,Jay Kreps經(jīng)常被問及有關(guān)Lambda架構(gòu)的問題,為此他結(jié)合實(shí)際經(jīng)驗(yàn)和個(gè)人體會(huì),把使用Lambda架構(gòu)的心得總結(jié)為以下幾點(diǎn),我們一起來看下:
Lambda架構(gòu)的組成
該架構(gòu)的組成是這樣的:
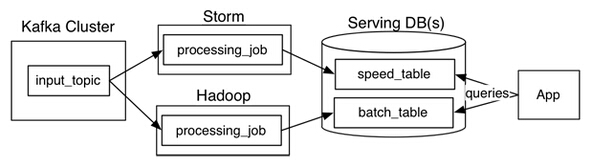
在該架構(gòu)中,被讀取的數(shù)據(jù)是不可變的,在并行處理過程中數(shù)據(jù)會(huì)依次進(jìn)入批處理系統(tǒng)(batch system)與流處理系統(tǒng)。從邏輯上看,傳輸過程發(fā)生了兩次,一次是在批處理中,一次是在流處理中。在查詢時(shí),當(dāng)這兩者都返回結(jié)果后,才算是完成一次完整的查詢。
這個(gè)架構(gòu)可以有很多的組合變化,我的想法是希望它變得更簡潔。例如可以把里面的Kafka、Storm、Hadoop等換成其它類似的系統(tǒng);慣常的做法是使用兩個(gè)數(shù)據(jù)庫來存儲(chǔ)數(shù)據(jù)輸出表,一個(gè)用于實(shí)時(shí)優(yōu)化查詢,另外一個(gè)用于批量優(yōu)化處理。
Lambda架構(gòu)的目的是為應(yīng)用程序提供一個(gè)低延遲的復(fù)合異步數(shù)據(jù)傳輸環(huán)境,例如新聞?lì)悜?yīng)用,經(jīng)常需要進(jìn)行大規(guī)模信息處理,包括輸入,歸類,索引,存儲(chǔ)等操作。
我的體會(huì)是:架構(gòu)的引入不能照本宣科,要根據(jù)實(shí)際情況進(jìn)行調(diào)整優(yōu)化。
優(yōu)缺點(diǎn)分析
優(yōu)點(diǎn):
此外,外界對(duì)于Lambda的評(píng)論還有其它觀點(diǎn),例如說實(shí)時(shí)數(shù)據(jù)處理是固有的,較批處理是高損耗低效率,我對(duì)此并不贊同。誠然流處理目的框架前沒有MapReduce那樣成熟,但是我們應(yīng)該用發(fā)展的觀點(diǎn)來看待而不是就此蓋棺定論。
缺點(diǎn):
完成的試驗(yàn)
在Linkedln中,我們做了不少的試驗(yàn)。嘗試建立不同類型的分布式計(jì)算框架,甚至是開發(fā)出使代碼能在實(shí)時(shí)或Hadoop中無縫運(yùn)行的專用API。不過,目前來看還不沒做到完美無缺。因?yàn)槎嘞到y(tǒng)的編程任務(wù)實(shí)在是太艱巨了。此外,API的使用會(huì)讓系統(tǒng)的漏洞不易被發(fā)現(xiàn),同時(shí)對(duì)開發(fā)者有更嚴(yán)格的技術(shù)要求――對(duì)API的運(yùn)用要足夠的熟練,從而能在調(diào)試或效率檢視時(shí)能夠?qū)λ杏绊懙囊蛩刈龅搅巳挥谛亍?/span>
我的建議是:如果你不太看重延遲問題,可以嘗試使用類似MapReduce的批處理框架或者是流處理框架,但是最好不要同時(shí)使用,除非真的有必要。
那么,Lambda架構(gòu)的優(yōu)勢是什么呢?我想是它能夠很好地指導(dǎo)如何搭建一個(gè)復(fù)雜的低延遲處理系統(tǒng)。例如搭建一個(gè)處理歷史數(shù)據(jù)的高延遲大數(shù)據(jù)處理系統(tǒng)和一個(gè)低延遲的流處理系統(tǒng)來減少重新計(jì)算的問題。但是這應(yīng)該是暫時(shí)性的,未來還會(huì)存在更好的替代解決方案。
一個(gè)替代方案
很多時(shí)候,慣性思維會(huì)讓人覺得流處理系統(tǒng)在處理歷史數(shù)據(jù)等大數(shù)據(jù)場合不太適合,但是我覺得這可能與他們使用的系統(tǒng)自身限制有關(guān)。流處理其實(shí)是在數(shù)據(jù)輸出的中間階段進(jìn)行的,完成后再把結(jié)果返回給用戶,所以是具備大數(shù)據(jù)處理能力的。
例如,請(qǐng)看下我們的一個(gè)替代方案:
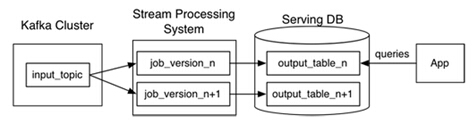
1. 使用Kafka或其它系統(tǒng)來對(duì)需要重新計(jì)算的數(shù)據(jù)進(jìn)行日志記錄,以及提供給多個(gè)訂閱者使用。例如需要重新計(jì)算30天內(nèi)的數(shù)據(jù),我們可以在Kafka中設(shè)置30天的數(shù)據(jù)保留值。
2. 當(dāng)需要進(jìn)行重新計(jì)算時(shí),啟動(dòng)流處理作業(yè)的第二個(gè)實(shí)例對(duì)之前獲得的數(shù)據(jù)進(jìn)行處理,之后直接把結(jié)果數(shù)據(jù)放入新的數(shù)據(jù)輸出表中。
3. 當(dāng)作業(yè)完成時(shí),讓應(yīng)用程序直接讀取新的數(shù)據(jù)記錄表。
4. 停止歷史作業(yè),刪除舊的數(shù)據(jù)輸出表。
有別于Lambda架構(gòu),上述方法是在代碼改動(dòng)時(shí)才進(jìn)行數(shù)據(jù)重新計(jì)算。如果想加快處理速度,計(jì)算作業(yè)的并行處理能力是個(gè)突破口。或許我們可以把這個(gè)架構(gòu)稱呼為Kappa架構(gòu),雖然它真的很簡易。
這個(gè)方案還能繼續(xù)優(yōu)化改進(jìn)。很多情況下,我們可以把兩個(gè)數(shù)據(jù)輸出表整合在一起。這樣一來,我們可以很快地在程序中讀取歷史記錄和進(jìn)行其它重要的針對(duì)新老版本的測調(diào)試工作。
請(qǐng)注意,這個(gè)方法不是說讓我們遠(yuǎn)離HDFS,而是說我們不在HDFS中進(jìn)行重新計(jì)算。詳細(xì)的說明文檔,請(qǐng)點(diǎn)擊這里進(jìn)行查閱。
背景知識(shí)
對(duì)Kafka不太熟悉的讀者,可能理解上會(huì)有點(diǎn)困難。我們這里給出一些背景介紹,希望對(duì)初學(xué)者有所幫助。
Kafka中是這樣按序來進(jìn)行日志記錄的:
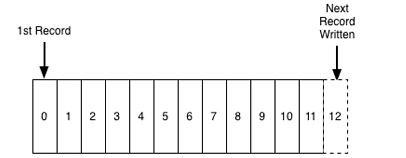
一個(gè)Kafka“主題”包含了以下的記錄集:
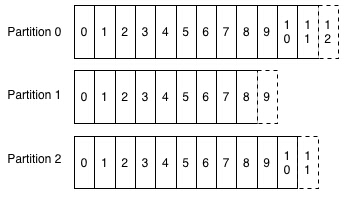
一個(gè)流處理在使用這些數(shù)據(jù)時(shí)進(jìn)行的是“偏移”量維護(hù),就是把每個(gè)分區(qū)最新加入數(shù)據(jù)的編號(hào)進(jìn)行記錄。所以,只需使用不同的偏移量來重新執(zhí)行作業(yè)就可以實(shí)現(xiàn)重新計(jì)算的目的。對(duì)統(tǒng)一數(shù)據(jù)添加第二個(gè)消息消費(fèi)者其實(shí)就相當(dāng)于使另外一個(gè)讀者指向不同的日志位置。
Kafka提供了復(fù)制和高容錯(cuò)的能力,使得能在便宜的商業(yè)硬件中使用,特別是在TB級(jí)別的存儲(chǔ)場合中。
寫在最后
雖然在Linkedln中,配合該方法的是Samza流處理系統(tǒng),但并不代表不能在其他系統(tǒng)中運(yùn)用。有心的讀者可以進(jìn)行嘗試,我很樂意看到有新的方案產(chǎn)生。
英文出自:radar.oreilly

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


