
阿里巴巴作為國內(nèi)使用Hadoop最早的公司之一,已開啟了Apache Hadoop 2.0時代。阿里巴巴的Hadoop集群,即云梯集群,分為存儲與計算兩個模塊,計算模塊既有MRv1,也有YARN集群,它們共享一個存儲HDFS集群。云梯YARN集群上既支持MapReduce,也支持Spark、MPI、RHive、RHadoop等計算模型。本文將詳細介紹云梯YARN集群的 技術實現(xiàn)與發(fā)展狀況。
MRv1與YARN集群共享HDFS存儲的技術實現(xiàn)
以服務化為起點,云梯集群已將Hadoop分為存儲(HDFS)服務與計算(MRv1和YARN)服務。兩個計算集群共享著這個HDFS存儲集群,這是怎么做到的呢?
在引入YARN之前,云梯的Hadoop是一個基于Apache Hadoop 0.19.1-dc版本,并增加許多新功能的版本。另外還兼容了Apache Hadoop 0.19、0.20、CDH3版本的客戶端。為了保持對客戶端友好,云梯服務端升級總會保持對原有客戶端的兼容性。另外,為了訪問數(shù)據(jù)的便捷性,阿里的存儲集群是一個單一的大集群,引入YARN不應迫使HDFS集群拆分,但YARN是基于社區(qū)0.23系列版本,它無法直接訪問云梯HDFS集群。因此實現(xiàn) YARN集群訪問云梯的HDFS集群是引入YARN后第一個需要解決的技術問題。
Hadoop代碼主要分為Common、HDFS、Mapred三個包。
為了盡量減少對云梯HDFS的修改,開發(fā)人員主要做了以下工作。
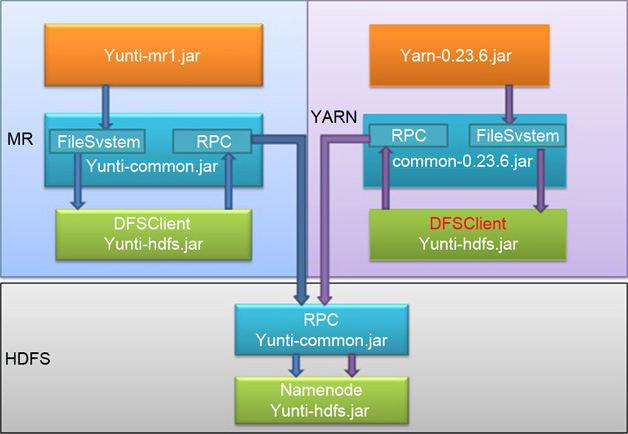
圖1 云梯Hadoop代碼架構
新的云梯代碼結(jié)構如圖1所示,相應闡述如下。
服務端
客戶端
云梯MR服務切換為YARN要經(jīng)過三個階段
通過上述修改,云梯開發(fā)人員以較小的修改實現(xiàn)了YARN對云梯HDFS的訪問。
Spark on YARN的實現(xiàn)
云梯版YARN集群已實現(xiàn)對MRv2、Hive、Spark、MPI、RHive、RHadoop等應用的支持。云梯集群當前結(jié)構如圖2所示。
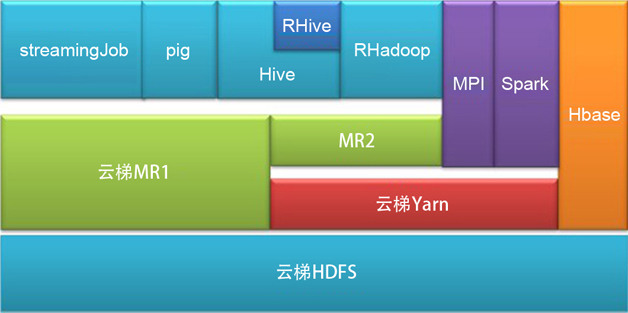
圖2 云梯架構圖
其中,Spark已成為YARN集群上除MapReduce應用外另一個重要的應用。
Spark是一個分布式數(shù)據(jù)快速分析項目。它的核心技術是彈性分布式數(shù)據(jù)集(Resilient Distributed Datasets),提供了比MapReduce豐富的模型,可以快速在內(nèi)存中對數(shù)據(jù)集進行多次迭代,來支持復雜的數(shù)據(jù)挖掘算法和圖形計算算法。
Spark的計算調(diào)度方式,從Mesos到Standalone,即自建Spark計算集群。雖然Standalone方式性能與穩(wěn)定性都得到了提升,但自建集群畢竟資源較少,并需要從云梯集群復制數(shù)據(jù),不能滿足數(shù)據(jù)挖掘與計算團隊業(yè)務需求。而Spark on YARN能讓Spark計算模型在云梯YARN集群上運行,直接讀取云梯上的數(shù)據(jù),并充分享受云梯YARN集群豐富的計算資源。
Spark on YARN功能理論上從Spark 0.6.0版本開始支持,但實際上還遠未成熟,經(jīng)過數(shù)據(jù)挖掘與計算團隊長時間的壓力測試,修復了一些相對關鍵的Bug,保證Spark on YARN的穩(wěn)定性和正確性。
圖3展示了Spark on YARN的作業(yè)執(zhí)行機制。
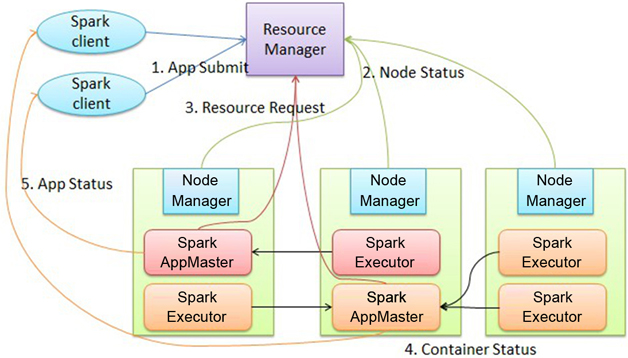
圖3 Spark on YARN框架
基于YARN的Spark作業(yè)首先由客戶端生成作業(yè)信息,提交給ResourceManager,ResourceManager在某一 NodeManager匯報時把AppMaster分配給NodeManager,NodeManager啟動 SparkAppMaster,SparkAppMaster啟動后初始化作業(yè),然后向ResourceManager申請資源,申請到相應資源后 SparkAppMaster通過RPC讓NodeManager啟動相應的SparkExecutor,SparkExecutor向 SparkAppMaster匯報并完成相應的任務。此外,SparkClient會通過AppMaster獲取作業(yè)運行狀態(tài)。
目前,數(shù)據(jù)挖掘與計算團隊通過Spark on YARN已實現(xiàn)MLR、PageRank和JMeans算法,其中MLR已作為生產(chǎn)作業(yè)運行。
云梯YARN集群維護經(jīng)驗分享
云梯YARN的維護過程中遇到許多問題,這些問題在維護YARN集群中很有可能會遇到,這里分享兩個較典型的問題與其解決方法。
問題描述:社區(qū)的CPU隔離與調(diào)度功能,需要在每個NodeManager所在的機器創(chuàng)建用戶賬戶對應的Linux賬戶。但阿里云梯集群有5000多個帳戶,是否需要在每個NodeManager機器創(chuàng)建這么多Linux賬戶;另外,每次創(chuàng)建或刪除一個Hadoop用戶,也應該在每臺NodeManager 機器上創(chuàng)建或刪除相應的Linux賬戶,這將大大增加運維的負擔。
問題分析:我們發(fā)現(xiàn),CPU的隔離是不依賴于Linux賬戶的,意味著即使同一個帳戶創(chuàng)建兩個進程,也可通過Cgroup進行CPU隔離,但為什么社區(qū)要在每臺NodeManager機器上創(chuàng)建帳戶呢?原來這是為了讓每個Container都以提交Application的賬戶執(zhí)行,防止Container所屬的Linux賬戶權限過大,保證安全。但云梯集群很早前就已分 賬戶,啟動Container的Linux賬戶統(tǒng)一為一個普通賬戶,此賬戶權限較小,并且用戶都為公司內(nèi)部員工,安全性已能滿足需求。
解決方案:通過修改container-executor.c文件,防止其修改Container的啟動賬戶,并使用一個統(tǒng)一的普通Linux賬戶(無sudo權限)運行Container。這既能保證安全,又能減少運維的工作量。
問題描述:MRApplicationMaster初始化慢,某些作業(yè)的MRApplicationMaster啟動耗時超過一分鐘。
問題分析:通過檢查MRApplication-Master的日志,發(fā)現(xiàn)一分鐘的初始化時間都消耗在解析Rack上。從代碼上分析,MRApplicationMaster啟動時需要初始化TaskAttempt,這時需要解析split信息中的Host,生成對應的Rack信息。云梯當前解析Host的方法是通過調(diào)用外部一個Python腳本解析,每次調(diào)用需要20ms左右,而由于云梯HDFS集群非常大,有4500多臺機器,假如輸入數(shù)據(jù)分布在每個Datanode上,則解析Host需要花費4500×20ms=90s;如果一個作業(yè)的輸入數(shù)據(jù)較大,且文件的備份數(shù)為3, 那么輸入數(shù)據(jù)將很有可能分布在集群的大多Datanode上。
解決方案:開發(fā)人員通過在Node-Manager上增加一個配置文件,包含所有Datanode的Rack信息,MRApp-licationMaster啟動后加載此文件,防止頻繁調(diào)用外部腳本解析。這大大加快了MRApplicationMaster的初始化速度。
此外,云梯開發(fā)人員還解決了一些會使ResourceManager不工作的Bug,并貢獻給Apache Hadoop社區(qū)。
在搭建與維護云梯YARN集群期間,云梯開發(fā)人員遇到并解決了許多問題,分析和解決這些問題首先需要熟悉代碼,但代碼量巨大,我們?nèi)绾文芸焖偈煜に鼈兡兀窟@ 需要團隊的配合,團隊中每個人負責不同模塊,閱讀后輪流分享,這能加快代碼熟悉速度。另外,Hadoop的優(yōu)勢在于可以利用社區(qū)的力量,當遇到一個問題時,首先可以到社區(qū)尋找答案,因為很多問題在社區(qū)已得到了解決,充分利用社區(qū),可以大大提高工作效率。
云梯YARN集群的優(yōu)勢與未來之路
當前云梯YARN集群已經(jīng)試運行,并有MRv2、Hive、Spark、RHive和RHadoop等應用。云梯YARN集群的優(yōu)勢在于:
未來,云梯將會把大多業(yè)務遷移到云梯YARN集群。針對YARN版本,云梯將增加資源隔離與調(diào)度,增加對Storm、Tez等計算模型的支持,并優(yōu)化YARN的性能。
作者沈洪,花名俞靈,就職于阿里巴巴集團數(shù)據(jù)平臺事業(yè)部海量數(shù)據(jù)部門,目前從事YARN、MapReduce的研究、開發(fā)與集群的維護。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權很多不明,如有侵權請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


