
在今天智能手機(jī)領(lǐng)域中有這樣一個(gè)趨勢(shì),美國Qualcomm公司提倡使用DSP去處理手勢(shì)操作、陀螺儀等傳感器所需的計(jì)算任務(wù)。這可以幫助CPU分擔(dān)部分計(jì)算任務(wù),又節(jié)省了電能的消耗。現(xiàn)在很多SoC廠商也開始意識(shí)到了這一點(diǎn),例如蘋果會(huì)考慮在iPhone 5S中加一顆Cortex-M7處理器,來處理傳感器、計(jì)步器等對(duì)性能要求較低,而對(duì)功耗要求較高的場(chǎng)景下的計(jì)算。那么從桌面計(jì)算架構(gòu),到今天的移動(dòng)設(shè)備的計(jì)算架構(gòu),異構(gòu)計(jì)算是如何演化,又是如何影響我們的技術(shù)革新的?本文將為您詳細(xì)解析。
異構(gòu)計(jì)算:把各種果料壓成一塊切糕
典型的異構(gòu)計(jì)算應(yīng)用,也并不是一個(gè)新話題。早在20世紀(jì)80年代中期,異構(gòu)計(jì)算技術(shù)就誕生了。它主要是指使用不同類型指令集、體系架構(gòu)的計(jì)算單元組成混合系統(tǒng)的一種特殊計(jì)算方式。異構(gòu)計(jì)算(Heterogeneous computing)主要是指使用不同類型指令集和體系架構(gòu)的計(jì)算單元組成系統(tǒng)的計(jì)算方式。常見的計(jì)算單元類別包括:CPU(中央處理器)、GPU(圖形處理器)、CO-Processor(協(xié)處理器)、DSP(信號(hào)處理器)、ASIC(專用集成電路)、FPGA(現(xiàn)場(chǎng)可編程門陣列)等。
異構(gòu)計(jì)算近年來得到更多關(guān)注,主要是因?yàn)橥ㄟ^提升CPU時(shí)鐘頻率和內(nèi)核數(shù)量而提高計(jì)算能力的傳統(tǒng)方式遇到了散熱和能耗瓶頸。而與此同時(shí),GPU等專用計(jì)算單元雖然工作頻率較低,具有更多的內(nèi)核數(shù)和并行計(jì)算能力,總體性能、芯片面積比和性能、功耗比都很高,但芯片的性能卻遠(yuǎn)遠(yuǎn)沒有得到充分利用。
從廣義上講,不同計(jì)算平臺(tái)的各個(gè)層次上都存在異構(gòu)現(xiàn)象。除硬件層的指令集、互聯(lián)方式、內(nèi)存層次之外,軟件層中應(yīng)用二進(jìn)制接口、API、語言特性底層實(shí)現(xiàn)等的不同,對(duì)于上層應(yīng)用和服務(wù)而言,都是異構(gòu)的。
從實(shí)現(xiàn)的角度來說,異構(gòu)計(jì)算就是制定出一系列的軟件與硬件的標(biāo)準(zhǔn),讓不同類型的計(jì)算設(shè)備能夠共享計(jì)算的過程和結(jié)果。同時(shí)不斷優(yōu)化和加速計(jì)算的過程,使其具備更高的計(jì)算效能。本文所講述的異構(gòu),是指的CPU與其他計(jì)算元器件之間的異構(gòu)計(jì)算演進(jìn),從硬件與軟件的角度,講述他們的發(fā)展歷程。

并行計(jì)算:讓處理的速度變得更快
相對(duì)于串行計(jì)算,并行計(jì)算可以劃分成時(shí)間并行和空間并行。時(shí)間并行即流水線技術(shù),空間并行使用多個(gè)處理器執(zhí)行并發(fā)計(jì)算,當(dāng)前研究的主要是空間的并行問題。以程序和算法設(shè)計(jì)人員的角度看,并行計(jì)算又可分為數(shù)據(jù)并行和任務(wù)并行。數(shù)據(jù)并行把大的任務(wù)化解成若干個(gè)相同的子任務(wù),處理起來比任務(wù)并行簡單。
空間上的并行導(dǎo)致兩類并行機(jī)的產(chǎn)生,按照麥克?弗萊因(Michael Flynn)的說法分為單指令流多數(shù)據(jù)流(SIMD)和多指令流多數(shù)據(jù)流(MIMD),而常用的串行機(jī)也稱為單指令流單數(shù)據(jù)流(SISD)。MIMD類的機(jī)器又可分為常見的五類:并行向量處理機(jī)(PVP)、對(duì)稱多處理機(jī)(SMP)、大規(guī)模并行處理機(jī)(MPP)、工作站機(jī)群(COW)、分布式共享存儲(chǔ)處理機(jī)(DSM)。
從自然哲學(xué)層面上來講:任何最為復(fù)雜的事情,都可以被拆分成若干個(gè)小問題去解決。這構(gòu)成了現(xiàn)代并行計(jì)算的哲學(xué)理論依據(jù)。然而在當(dāng)今的雙路、四路、八路甚至多路處理器系統(tǒng)中,并行計(jì)算的概念早已得到廣泛應(yīng)用。曾經(jīng)業(yè)界最為普及的并行計(jì)算規(guī)范就是OpenMP。
OpenMP:同構(gòu)計(jì)算最為普及的標(biāo)準(zhǔn)
OpenMP(Open Multi-Processing)是由OpenMP Architecture Review Board牽頭提出的,并已被廣泛接受的,用于共享內(nèi)存并行系統(tǒng)的多線程程序設(shè)計(jì)的一套指導(dǎo)性注釋(Compiler Directive)。OpenMP支持的編程語言包括C語言、C++和Fortran;而支持OpenMP的編譯器包括Sun Studio和Intel Compiler,以及開放源碼的GCC和Open64編譯器。OpenMP提供了對(duì)并行算法的高層的抽象描述,程序員通過在源代碼中加入專用的pragma來指明自己的意圖,由此編譯器可以自動(dòng)將程序進(jìn)行并行化,并在必要之處加入同步互斥以及通信。當(dāng)選擇忽略這些pragma,或者編譯器不支持OpenMP時(shí),程序又可退化為通常的程序(一般為串行),代碼仍然可以正常運(yùn)作,只是不能利用多線程來加速程序執(zhí)行。

OpenMP的特色
OpenMP提供的這種對(duì)于并行描述的高層抽象降低了并行編程的難度和復(fù)雜度,這樣程序員可以把更多的精力投入到并行算法本身,而非其具體實(shí)現(xiàn)細(xì)節(jié)。對(duì)基于數(shù)據(jù)分集的多線程程序設(shè)計(jì),OpenMP是一個(gè)很好的選擇。同時(shí),使用OpenMP也提供了更強(qiáng)的靈活性,可以較容易的適應(yīng)不同的并行系統(tǒng)配置。線程粒度和負(fù)載平衡等是傳統(tǒng)多線程程序設(shè)計(jì)中的難題,但在OpenMP中,OpenMP類庫從程序員手中接管了部分這兩方面的工作,可以自動(dòng)均衡負(fù)載。
OpenMP的缺點(diǎn)
作為高層抽象,OpenMP并不適合需要復(fù)雜的線程間同步和互斥的場(chǎng)合。OpenMP的另一個(gè)缺點(diǎn)是不能在非共享內(nèi)存系統(tǒng)(如計(jì)算機(jī)集群)上使用。由此如果我們想將不同類型的計(jì)算器、計(jì)算機(jī)聯(lián)和起來,協(xié)同工作。由此,我們就需要使用更為復(fù)雜的異構(gòu)計(jì)算技術(shù)。

蒙昧期:從32bit到64bit
2003年以前,對(duì)于臺(tái)式機(jī)來說還是32bit的時(shí)代。處理器制造廠商,不斷提升制造工藝技術(shù),使用更精細(xì)的制程來制造處理器。同時(shí)也不斷提高處理器的時(shí)脈,如133MHz、166MHz、200MHz、300MHz……最終頻率提升到了3GHz后,就難作寸進(jìn)了。到目前為止我們也未曾見到Intel和AMD發(fā)布高于4GHz主頻的處理器產(chǎn)品。
2003年出現(xiàn)了x86-64,有時(shí)簡稱為“x64”。這是64位微處理器架構(gòu)及其相應(yīng)指令集的一種,也是Intel x86架構(gòu)的延伸產(chǎn)品。“x86-64”最初是1999年由AMD設(shè)計(jì),AMD首次公開64位集以擴(kuò)充給IA-32,稱為x86-64(后來改名為AMD64)。其后也為Intel所采用,Intel稱之為“Intel 64”,在之前還曾使用過Clackamas Technology (CT)、IA-32e及EM64T等稱呼。外界多使用"x86-64"或"x64"去稱呼此64位架構(gòu),從而保持中立,不偏袒任何廠商。
AMD64代表AMD放棄了跟隨Intel標(biāo)準(zhǔn)的一貫作風(fēng),選擇了像把16位的Intel 8086擴(kuò)充成32位的80386般,去把x86架構(gòu)擴(kuò)充成64位版本,且兼容原有標(biāo)準(zhǔn)。
AMD64架構(gòu)在IA-32上新增了64位暫存器,并兼容早期的16位和32位軟件,可使現(xiàn)有以x86為對(duì)象的編譯器容易轉(zhuǎn)為AMD64版本。除此之外,NX bit也是引人注目的特色之一。
不少人認(rèn)為,像DEC Alpha般的64位RISC芯片,最終會(huì)取代現(xiàn)有過時(shí)及多變的x86架構(gòu)。但事實(shí)上,為x86系統(tǒng)而設(shè)的應(yīng)用軟件數(shù)量實(shí)在太龐大,x86的整個(gè)生態(tài)系統(tǒng)基石深厚。這也成為Alpha不能取代x86的主要原因,AMD64的成功在于,能有效地把x86架構(gòu)移至64位的環(huán)境,并且能兼容原有的x86應(yīng)用程序。
CPU中出現(xiàn)多處理核心
2006年出現(xiàn)了雙核心多核心。多核心,也叫多微處理器核心是將兩個(gè)或更多的獨(dú)立處理器封裝在一起的方案,通常在一個(gè)集成電路(IC)中。雙核心設(shè)備只有兩個(gè)獨(dú)立的微處理器。一般說來,多核心微處理器允許一個(gè)計(jì)算設(shè)備在不需要將多核心包括在獨(dú)立物理封裝時(shí)執(zhí)行某些形式的線程級(jí)并發(fā)處理(Thread-Level Parallelism,TLP)這種形式的TLP通常被認(rèn)為是芯片級(jí)多處理。如3D游戲這樣的密集型運(yùn)算場(chǎng)景中,您必須要使用驅(qū)動(dòng)程序來調(diào)用第二顆處理核心的計(jì)算資源。
此后處理器制造廠商發(fā)現(xiàn),利用多核心架構(gòu)可以在不提升處理器頻率的情況下,繼續(xù)不斷提升處理器的效能。這也讓摩爾定律有機(jī)會(huì)一路走下去。
GPGPU:開啟通用計(jì)算大門
隨著CPU性能發(fā)展放緩,人們開始尋求新的性能爆點(diǎn)。2008年出現(xiàn)了通用計(jì)算單元這一概念。通用圖形處理器(General-purpose computing on graphics processing units,簡稱GPGPU),是一種利用處理圖形任務(wù)的圖形處理器來計(jì)算原本由中央處理器處理的通用計(jì)算任務(wù)。這些通用計(jì)算常常與圖形處理沒有任何關(guān)系。由于現(xiàn)代圖形處理器強(qiáng)大的并行處理能力和可編程流水線,令流處理器可以處理非圖形數(shù)據(jù)。特別在面對(duì)單指令流多數(shù)據(jù)流(SIMD),且數(shù)據(jù)處理的運(yùn)算量遠(yuǎn)大于數(shù)據(jù)調(diào)度和傳輸?shù)男枰獣r(shí),通用圖形處理器在性能上大大超越了傳統(tǒng)的中央處理器應(yīng)用程序。
3D顯示卡的性能從NVIDIA的GeForce256時(shí)代就頗受矚目,時(shí)間到了2008年,顯示卡的計(jì)算能力開始被用在實(shí)際的計(jì)算當(dāng)中。并且其處理的速度也遠(yuǎn)遠(yuǎn)超越了傳統(tǒng)的x86處理器。
CPU+GPU:異構(gòu)計(jì)算悄然興起
對(duì)于GPGPU表現(xiàn)出的驚人計(jì)算能力叫人為之折服,但是在顯卡進(jìn)行計(jì)算的同時(shí),處理器處于閑置狀態(tài)。由此處理器廠商也想?yún)⑴c到計(jì)算中來,他們希望CPU和GPU能夠協(xié)同運(yùn)算,完成那些對(duì)計(jì)算量有著苛刻要求的應(yīng)用。同時(shí)也希望將計(jì)算機(jī)的處理能力再推上一個(gè)新的高峰。這里更多的是希望GPU能參與到CPU計(jì)算任務(wù)中來,讓GPU分?jǐn)偞蟛糠謾C(jī)械性的大規(guī)模計(jì)算任務(wù)。一時(shí)間,世界上的超級(jí)計(jì)算機(jī)都開始了大提速。

天河當(dāng)自強(qiáng),異構(gòu)顯神威
說個(gè)老黃歷,國際TOP500組織TOP500.org在網(wǎng)站上每半年會(huì)公布最新的全球超級(jí)計(jì)算機(jī)TOP500強(qiáng)排行榜。2010年11月14日,國際TOP500組織在網(wǎng)站上公布了最新全球超級(jí)計(jì)算機(jī)前500強(qiáng)排行榜,中國首臺(tái)千萬億次超級(jí)計(jì)算機(jī)系統(tǒng)“天河一號(hào)”排名全球第一。實(shí)測(cè)運(yùn)算速度可以達(dá)到2.566 petaFLOPS(每秒萬億次)。
該計(jì)算機(jī)共耗資6億元人民幣,由103臺(tái)機(jī)柜組成,占地面積約1000平方米,裝有3072顆Intel的至強(qiáng)E5540 2.53GHz四核處理器和3072顆至強(qiáng)E5450 3.0GHz四核處理器,共有24,576個(gè)處理器核心。天河一號(hào)還裝備2560塊AMD Radeon HD 4870 X2顯示卡,共有5,120個(gè)圖形處理器用于圖形處理器通用編程。天河一號(hào)擁有98TB內(nèi)存和1PB共用的磁盤容量。全系統(tǒng)功率為1280千瓦。

迥異:不同計(jì)算架構(gòu)的特點(diǎn)
上面提到的采用的異構(gòu)計(jì)算架構(gòu)都屬于大型計(jì)算機(jī)的范疇。對(duì)于個(gè)人計(jì)算機(jī)而言,尤其是x86架構(gòu)的計(jì)算機(jī),異構(gòu)計(jì)算的步伐則要慢許多。這是因?yàn)椋瑹o論是處理器還是顯示卡,又或者其他運(yùn)算部件,都有其自身的架構(gòu)和特性。他們是針對(duì)不同領(lǐng)域,面向不同應(yīng)用所設(shè)計(jì)的芯片。所以他們?cè)诠δ苄苑矫媲Р钊f別。要想將他們都統(tǒng)一起來,除了需要制定共同的規(guī)范和標(biāo)準(zhǔn)之外,還要針對(duì)其計(jì)算的特點(diǎn)設(shè)計(jì)軟件。
舉例來說,CPU和GPU在進(jìn)行計(jì)算時(shí),就有許多不同。對(duì)于處理器來說,它是一顆通用處理器。它要應(yīng)對(duì)各種類型的計(jì)算應(yīng)用。無論是數(shù)學(xué)方面的,還是邏輯方面的運(yùn)算。我們可以看到,一顆比較常規(guī)的處理器其中的ALU計(jì)算單元僅僅占據(jù)整個(gè)核心面積的25%以內(nèi)。在處理器中,超過50%的核心面積用來制作Cache高速緩存,無論是L1、L2還是片上的L3。而另外還有25%的核心面積用來作為控制器。它控制著處理管線的運(yùn)作,控制著各種分支預(yù)測(cè),讓多核心處理器可以更有效率。
而我們?cè)俜从^GPU,其結(jié)構(gòu)要簡單的多。GPU的任務(wù)是加速3D像素的計(jì)算。因此我們?cè)陲@卡中可以看到數(shù)以百計(jì)的流處理器單元或者是CUDA核心。而在整個(gè)計(jì)算過程中,GPU承擔(dān)的邏輯計(jì)算任務(wù)非常小。同時(shí)它有著更寬的顯存帶寬,有著更高速的顯存。所以在GPU芯片中,也就無需更大容量的片上緩存機(jī)制。
通過上文的分析,我們可以看到CPU的在處理時(shí),適合作所有工作,各個(gè)方面都比較平均。邏輯處理能力要比GPU快,但是對(duì)于數(shù)學(xué)計(jì)算方面,其速度不如具有海量處理核心的GPU快。而GPU方面,數(shù)學(xué)計(jì)算性能強(qiáng)大,大規(guī)模并行處理機(jī)制強(qiáng)大,但是邏輯處理能力不足,僅僅能在某些計(jì)算領(lǐng)域應(yīng)用。
FireStream:慢慢淡出我們的視野
Firestream是AMD旗下的品牌系列之一。與Radeon(用于消費(fèi)級(jí)顯卡)和FirePro(用于專業(yè)顯卡)不同,F(xiàn)ireStream主要用于AMD的高性能計(jì)算卡系列。FireStream產(chǎn)品中的GPU不是用來作3D加速用途,而是利用GPU內(nèi)置的流處理器變成一群并行處理器,作為浮點(diǎn)運(yùn)算協(xié)處理器,協(xié)助中央處理器計(jì)算復(fù)雜的浮點(diǎn)運(yùn)算程序,例如復(fù)雜的科學(xué)運(yùn)算。Firestream的競爭對(duì)手是nVIDIA的Tesla系列高性能計(jì)算卡。
早在數(shù)年前,人們就意識(shí)到GPU不但可以處理圖形數(shù)據(jù),還可以處理其他數(shù)據(jù)。BionicFX就試過利用GeForce 6800處理音頻數(shù)據(jù),ATI亦做過同樣的試驗(yàn)。而且史丹佛大學(xué)的Folding@Home研究項(xiàng)目亦可利用Radeon X1900作運(yùn)算加速;通過GPU來模擬蛋白質(zhì)合成,進(jìn)而找尋有關(guān)蛋白質(zhì)的疾病。
第一個(gè)產(chǎn)品,F(xiàn)ireStream 580,是建基于R580圖形芯片。它將是一塊采用R580顯核的特殊顯示卡,R580顯示核心中的48個(gè)獨(dú)立的像素處理器能帶來強(qiáng)大的浮點(diǎn)運(yùn)算性能。該產(chǎn)品采用PCI Express x16作為接口,流處理器的頻率是600 MHz,可以同時(shí)運(yùn)行512線程,并配備了1GB GDDR3存儲(chǔ)器,頻率是1300 MHz。并有可能使用多個(gè)核心并發(fā)處理數(shù)據(jù)。這個(gè)流處理器的功耗為165W。

CUDA:在夾縫中掙扎求存
CUDA(Compute Unified Device Architecture,統(tǒng)一計(jì)算架構(gòu))是由NVIDIA所推出的一種集成技術(shù),是該公司對(duì)于GPGPU的正式名稱。通過這個(gè)技術(shù),用戶可利用NVIDIA的GeForce 8以后的GPU和較新的Quadro GPU進(jìn)行計(jì)算。亦是首次可以利用GPU作為C-編譯器的開發(fā)環(huán)境。
目前為止基于 CUDA 的 GPU 銷量已達(dá)數(shù)以百萬計(jì),軟件開發(fā)商、科學(xué)家以及研究人員正在各個(gè)領(lǐng)域中運(yùn)用 CUDA,其中包括圖像與視頻處理、計(jì)算生物學(xué)和化學(xué)、流體力學(xué)模擬、CT 圖像再現(xiàn)、地震分析以及光線追蹤等等。
它包含了CUDA指令集架構(gòu)(ISA)以及GPU內(nèi)部的并行計(jì)算引擎。開發(fā)人員現(xiàn)在可以使用C語言來為CUDA架構(gòu)編寫程序,C語言是應(yīng)用最廣泛的一種高級(jí)編程語言。所編寫出的程序于是就可以在支持CUDA的處理器上以超高性能運(yùn)行。
CUDA v3.0以后,開始支持C++和FORTRAN。實(shí)際上,CUDA架構(gòu)可以兼容OpenCL或者自家的C-編譯器。無論是CUDA C-語言或是OpenCL,指令最終都會(huì)被驅(qū)動(dòng)程序轉(zhuǎn)換成PTX代碼,交由顯示核心計(jì)算。目前CUDA v6.5 RC已經(jīng)可用,包含了對(duì)ARM 64bit架構(gòu)的支持等一些先進(jìn)的特性。

PhysX:最出色的GPGPU應(yīng)用實(shí)例
PPU(Physics Processing Unit)物理處理單元是一種特別為減輕CPU 計(jì)算,尤其是物理運(yùn)算部分的處理器,您可以把它看做是一顆協(xié)處理器。這概念類似于對(duì)上10年間GPU。在現(xiàn)代計(jì)算機(jī)中,GPU用于處理矢量圖形,并且延伸到3D圖形。但GPU對(duì)物理處理無能為力,故目前大部分物理處理都交給CPU處理,這無疑是加重了CPU本來就不輕的負(fù)擔(dān)。
NVIDIA PhysX是一套由AGEIA 設(shè)計(jì)的執(zhí)行復(fù)雜的物理運(yùn)算的PPU,又可以代表一款物理引擎。AGEIA 聲稱,PhysX 將會(huì)使設(shè)計(jì)師在開發(fā)游戲的過程中,使用復(fù)雜的物理效果,而不需要像以往那樣,耗費(fèi)漫長的時(shí)間開發(fā)一套物理引擎。以往使用了物理引擎,還會(huì)使一些配置較低的電腦,無法流暢運(yùn)行游戲。AGEIA 更宣稱 PhysX 執(zhí)行物理運(yùn)算的效率,比當(dāng)前的 CPU 與物理處理軟件的組合高出 100 倍。游戲設(shè)計(jì)語言Dark Basic Pro將會(huì)支持PhysX,并允許其用戶利用 PhysX 執(zhí)行物理運(yùn)算。在 2005年7月20日,索尼同意在即將發(fā)售的PlayStation 3中使用AGEIA 的PhysX和它的SDK――NovodeX 。現(xiàn)時(shí),AGEIA公司己被NVIDIA收購,相關(guān)的顯卡亦可以加速該物理引擎。
PhysX設(shè)計(jì)用途是利用具備數(shù)百個(gè)內(nèi)核的強(qiáng)大處理器來進(jìn)行硬件加速。加上GPU超強(qiáng)的并行處理能力,PhysX將使物理加速處理能力呈指數(shù)倍增長并將您的游戲體驗(yàn)提升至一個(gè)全新的水平,在游戲中呈現(xiàn)豐富多彩、身臨其境的物理學(xué)游戲環(huán)境。
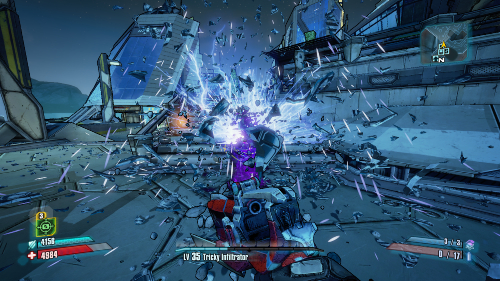
APU:臺(tái)式機(jī)上的異構(gòu)計(jì)算芯片
AMD在并購ATI以后,隨即公布了代號(hào)為“AMD Fusion”(融聚計(jì)劃)。簡要地說,這個(gè)項(xiàng)目的目標(biāo)是在一塊芯片上,集成傳統(tǒng)中央處理器和圖形處理器,并且內(nèi)置最少16通道、可與外部PCI-E設(shè)備鏈接的PCI-E控制器,存儲(chǔ)器控制器等。而這種設(shè)計(jì)會(huì)將北橋芯片從主板上卸載,集成到中央處理器中,CPU核心還可以將原來依賴CPU核心處理的任務(wù)(如浮點(diǎn)運(yùn)算)交給為運(yùn)算進(jìn)行過優(yōu)化的GPU處理(如處理浮點(diǎn)數(shù)運(yùn)算)。AMD認(rèn)為這是加速處理單元(APU)的一類,是為AMD加速處理器(AMD Accelerated Processing Units,AMD APU)。
2011年的CES上,AMD展示了Llano處理器,這是一顆真正意義上的異構(gòu)計(jì)算處理器。從這張這新架構(gòu)圖中,我們可以看到Llano具備四個(gè)處理核心,每一顆核心具有不同類型的L1高速緩存。同時(shí)每一個(gè)處理核心具備512KB X 2的容量為1MB的L2高速緩存。由此在處理器的部分,構(gòu)成了4MB的二級(jí)緩存。
在整個(gè)芯片接近50%的面積上,是GPU的部分。一顆處理芯片同時(shí)包含了CPU和GPU的部分,這可以說是非常典型的異構(gòu)計(jì)算架構(gòu)。同時(shí),在芯片的兩邊我們也可以看到高度集成的4個(gè)PCIe總線控制器,還有一個(gè)128bit位寬的DDR3內(nèi)存控制器。
這樣的異構(gòu)計(jì)算芯片可以充分發(fā)揮不同計(jì)算部件的優(yōu)勢(shì)。當(dāng)需要進(jìn)行較多邏輯計(jì)算時(shí),可以使用CPU部分完成。當(dāng)需要大量的浮點(diǎn)運(yùn)算時(shí),可以借用GPU的浮點(diǎn)運(yùn)算處理管線來完成。同時(shí)如果處理器的某些核心正處于空閑,也可以讓其加入到計(jì)算中來。由此可見異構(gòu)計(jì)算不僅僅是需要統(tǒng)一起不同類型的計(jì)算部件,同時(shí)也需要有針對(duì)性的讓更適合的硬件作適用的計(jì)算工作。
OpenCL:異構(gòu)計(jì)算真正開始閃耀
2008年6月的WWDC大會(huì)上,蘋果提出了OpenCL規(guī)范,旨在提供一個(gè)通用的開放API,在此基礎(chǔ)上開發(fā)GPU通用計(jì)算軟件。隨后,Khronos Group宣布成立GPU通用計(jì)算開放行業(yè)標(biāo)準(zhǔn)工作組,以蘋果的提案為基礎(chǔ)創(chuàng)立OpenCL行業(yè)規(guī)范。
OpenCL (Open Computing Language,開放計(jì)算語言) 是一個(gè)為異構(gòu)平臺(tái)編寫程序的框架,此異構(gòu)平臺(tái)可由CPU,GPU或其他類型的處理器組成。OpenCL由一門用于編寫kernels(在OpenCL設(shè)備上運(yùn)行的函數(shù))的語言(基于C99)和一組用于定義并控制平臺(tái)的API組成。OpenCL提供了基于任務(wù)分區(qū)和數(shù)據(jù)分區(qū)的并行計(jì)算機(jī)制。
OpenCL類似于另外兩個(gè)開放的工業(yè)標(biāo)準(zhǔn)OpenGL和OpenAL,這兩個(gè)標(biāo)準(zhǔn)分別用于三維圖形和計(jì)算機(jī)音頻方面。OpenCL擴(kuò)展了GPU用于圖形生成之外的能力。OpenCL由非盈利性技術(shù)組織Khronos Group掌管。
OpenCL最初蘋果公司開發(fā),擁有其商標(biāo)權(quán),并在與AMD,IBM,英特爾和nVIDIA技術(shù)團(tuán)隊(duì)的合作之下初步完善。隨后,蘋果將這一草案提交至Khronos Group。2010年6月14日,OpenCL 1.1 發(fā)布。

早在2008年,蘋果制定OpenCL大家都以為是桌面端的布局,蘋果希望通過OpenGL來讓自家的Mac電腦可以順利的使用兩個(gè)顯卡巨頭的產(chǎn)品做GPGPU運(yùn)算。蘋果的這一舉措?yún)s為未來的x86平臺(tái)異構(gòu)計(jì)算奠定了堅(jiān)實(shí)的基礎(chǔ)。因?yàn)闊o論是CUDA還是FireStream,無論是CUDA核心還是流處理器,軟件開發(fā)人員都可以通過OpenCL來支持。
但是在2014年的今天看來,蘋果的這步OpenCL秒棋,也深深的影響到了移動(dòng)產(chǎn)業(yè)。先賣個(gè)關(guān)子,且聽下文說到移動(dòng)端再細(xì)細(xì)分解。
DirectCompute:立足DX11,應(yīng)用廣泛
Microsoft DirectCompute是一個(gè)應(yīng)用程序接口(API),允許Windows Vista或Windows 7平臺(tái)上運(yùn)行的GPU進(jìn)行通用計(jì)算,DirectCompute是Microsoft DirectX的一部分。雖然DirectCompute最初在DirectX 11 API中得以實(shí)現(xiàn),但支持DX10的GPU可以利用此API的一個(gè)子集進(jìn)行通用計(jì)算,支持DX11的GPU則可以使用完整的DirectCompute功能。
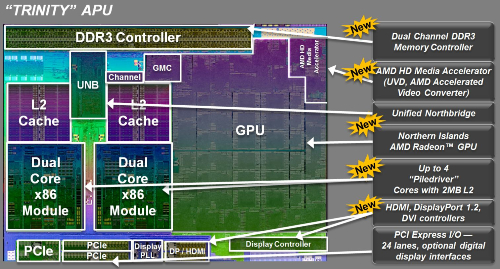
C++ AMP:微軟的異構(gòu)計(jì)算編程語言
相比OpenGL豐富的功能和體系化的SDK來說,DirectCompute僅僅是以一個(gè)簡單的API存于世上,顯然不能贏得更多廠商的關(guān)注。OpenCL作為一種開放的并行加速計(jì)算標(biāo)準(zhǔn),已經(jīng)得到了AMD、Intel、NVIDIA等芯片業(yè)巨頭和大量行業(yè)廠商的支持,但唯獨(dú)缺少了微軟。就在AMD Fusion開發(fā)者峰會(huì)上,微軟終于拿出了自己的反擊武器:“C++ AMP”,其中AMP三個(gè)字母是“accelerated massive parallelism”的縮寫,也就是加速大規(guī)模并行的意思。
C++ AMP是微軟Visual Studio和C++編程語言的新擴(kuò)展包,用于輔助開發(fā)人員充分適應(yīng)現(xiàn)在和未來的高度并行和異構(gòu)計(jì)算環(huán)境。通過使用 C++ AMP,您可以為多維數(shù)據(jù)算法編碼,以便通過使用異類硬件上的并行對(duì)執(zhí)行進(jìn)行加速。 C++ AMP編程模型包括多維數(shù)組、索引,內(nèi)存?zhèn)鬏敗⑵戒伜蛿?shù)學(xué)函數(shù)庫。 您可以使用C++ AMP語言擴(kuò)展控制數(shù)據(jù)在CPU和GPU之間相互移動(dòng)的方式,從而提高性能。C++ AMP現(xiàn)已加入Visual Studio 2013豪華午餐。不過它也有門檻,仍然需要DX11以上的硬件支持,才能運(yùn)行。
為了與OpenCL相抗衡,微軟宣布C++ AMP標(biāo)準(zhǔn)將是一種開放的規(guī)范,允許其它編譯器集成和支持。這無疑是對(duì)OpenCL的最直接挑戰(zhàn)。最近幾年,微軟一直在推C++ AMP,但是作為開放標(biāo)準(zhǔn)的OpenCL,也注定了其生態(tài)會(huì)更加的繁榮。
移動(dòng)GPU:用來一鍵“美白”
以往多數(shù)人對(duì)GPU的印象是其功能僅應(yīng)用于游戲。但事實(shí)上,GPU所能完成的工作不僅僅是運(yùn)行大型的3D游戲,我們可以利用它的計(jì)算特性做很多重要的事情。比如Qualcomm Snapdragon系列的SoC芯片中,包含了三塊具備較大處理能力的單元:Krait CPU、Adreno GPU和Hexagon DSP。如何更好的利用這三個(gè)計(jì)算單元,成為了移動(dòng)應(yīng)用開發(fā)者們必備的新“常識(shí)”。
CPU的整數(shù)運(yùn)算能力很強(qiáng),GPU的浮點(diǎn)計(jì)算能力更強(qiáng)。而DSP的特性和GPU還是有一些差別。DSP更傾向于處理有時(shí)間序列的任務(wù)。比如多媒體編解碼任務(wù),這是DSP最擅長做的。在視頻編解碼過程中的通常算法,是會(huì)根據(jù)前后兩幀之間的差值來進(jìn)行計(jì)算。因此DSP更適合去做一些機(jī)械的、簡單的計(jì)算工作。它最大的特點(diǎn)就是功耗低,使用它做計(jì)算可以更省電。

GPU近年來的應(yīng)用場(chǎng)景一直在不斷的拓展。這是因?yàn)楹芏嘈屡d的應(yīng)用類型,都對(duì)浮點(diǎn)運(yùn)算有著很高的要求。舉例來說,用戶可能會(huì)在拍照之后,用圖片處理應(yīng)用對(duì)照片進(jìn)行“美白”、 “磨皮”、增加曝光度、增加色彩飽和度等一系列復(fù)雜的處理。這些都可以用到GPU強(qiáng)大的并行計(jì)算特性。
龐大的數(shù)據(jù)處理,一直是手機(jī)拍照的技術(shù)難題。未來手機(jī)上的圖片處理軟件,將不得不考慮使用更為高效的方式來處理如此大容量的圖片。現(xiàn)在前置攝像頭的規(guī)格,少則200萬像素,多則500、800萬像素。后置的攝像頭,未來主流1300萬像素起,甚至有些手機(jī)都用上了4千萬像素的CMOS。
攝像頭像素規(guī)格――系統(tǒng)需要實(shí)時(shí)處理的數(shù)據(jù)量
在圖片處理應(yīng)用中,直接調(diào)用GPU的計(jì)算能力,會(huì)比調(diào)用某些所謂的8核心CPU更好、更快、更省電。又例如,很多具備所見所得濾鏡的視頻錄制應(yīng)用,用戶在手機(jī)屏幕上可以實(shí)時(shí)的看到“老照片”、“黑白”、“反色”、“美膚”等視頻濾鏡的效果。這種情況下就需要調(diào)用GPU來對(duì)實(shí)時(shí)濾鏡進(jìn)行渲染處理。
RenderScript:Google的移動(dòng)異構(gòu)方案
直到最近Google開始推RenderScript之后,異構(gòu)計(jì)算的這股熱潮才逐漸襲來。RenderScript是Android平臺(tái)的一種類C的腳本語言(使用C99語法),開發(fā)難度比OpenCL要小一些。之前Google在各個(gè)Android版本的動(dòng)態(tài)壁紙中用該技術(shù)實(shí)現(xiàn)3D圖形特效,直到Android 3.0才集成到SDK中來。
RenderScript的移植性還是不錯(cuò)的。傳統(tǒng)的NDK編寫代碼時(shí),必須事先在開發(fā)機(jī)上為每一個(gè)目標(biāo)原生平臺(tái)來編譯。而RenderScript可以在目標(biāo)設(shè)備上編譯,生成更高效的二進(jìn)制代碼。這也就意味著只要硬件支持RenderScript,不管采用什么架構(gòu),都可以運(yùn)行您的的RenderScript代碼。
但不幸的是,Google對(duì)OpenCL興趣不大,因?yàn)槟鞘翘O果主導(dǎo)的異構(gòu)聯(lián)盟。Google在Android 4.3系統(tǒng)之后,從Android上徹底鏟掉了對(duì)OpenCL的支持。
使用RenderScript,程序員不用關(guān)心設(shè)備底層細(xì)節(jié),不用考慮在不同Android設(shè)備的移植問題。不用考慮特定的CPU、GPU還是DSP,完全有驅(qū)動(dòng)自行優(yōu)化。對(duì)于想做深度優(yōu)化的程序員來說,RenderScript就是一個(gè)看不見的黑盒子。另一邊的OpenCL則展現(xiàn)出了更多硬件細(xì)節(jié),對(duì)于高級(jí)程序員來說,是一個(gè)可以充分榨干硬件性能,充分發(fā)揮異構(gòu)計(jì)算特性的強(qiáng)大法寶。按照Google官方的說法,他們摒棄OpenCL的原因是不想在各種設(shè)備上再看到分裂和不兼容的情況,他們想統(tǒng)一硬件和軟件標(biāo)準(zhǔn),才做出的這個(gè)“艱難的決定”。
Qualcomm:建議開發(fā)者用SDK優(yōu)化APP
幸運(yùn)的是,Qualcomm也正積極參與Khronos Group制定OpenCL標(biāo)準(zhǔn)的工作。同時(shí)它還是異構(gòu)系統(tǒng)架構(gòu)基金會(huì)(HSA Foundation)的創(chuàng)始會(huì)員。Qualcomm從Adreno 330 GPU起,已經(jīng)可以支持OpenCL、RenderScript和OpenGL ES 3.0(甚至還有DX11和曲面細(xì)分)。這會(huì)為移動(dòng)應(yīng)用開發(fā)者帶來極大的方便。
Qualcomm在GPU運(yùn)算、DSP運(yùn)算和異構(gòu)計(jì)算方面給開發(fā)者提供了完備的SDK,包括Adreno SDK(GPU方面)、Hexagon SDK(DSP方面)、FastCV(視覺計(jì)算)MARE SDK(并行計(jì)算)等方面。對(duì)于應(yīng)用開發(fā)者而言,最重要的就是要使用Qualcomm的SDK來優(yōu)化自己的應(yīng)用,無需再被底層的復(fù)雜工作困擾。Snapdragon SoC系統(tǒng)內(nèi)部會(huì)自動(dòng)識(shí)別任務(wù)的復(fù)雜程度,并調(diào)用相應(yīng)的計(jì)算單元來完成執(zhí)行。

asynchronous SMP:多核異步處理器
先說一下,標(biāo)準(zhǔn)的ARM架構(gòu),都是Simultaneous Multi-Processing(SMP多核同步處理器)架構(gòu)。然而asynchronous SMP(aSMP多核異步處理器)是Qualcomm自己提出來的,目前在Snapdragon中的Krait CPU,都是采用的這種多核異步的工作方式。
之前很多不明真相的“磚家”都說這是膠水處理器,只是把處理核心黏在一起。事實(shí)上,異步和同步的差異僅僅是在處理核心的工作頻率上。這稱作異步時(shí)脈架構(gòu)(Asynchronous Clock Architecture,ACA)異步處理中,每個(gè)處理核心的工作電壓和頻率都是不同的。一切設(shè)計(jì)都是為了移動(dòng)設(shè)備要盡可能的節(jié)電為大原則。可以讓一個(gè)時(shí)鐘頻率較高的處理核心,去運(yùn)行繁重的計(jì)算任務(wù)。讓低頻工作的處理核心運(yùn)行不是那么緊急,計(jì)算量相對(duì)較小的任務(wù)。而多核同步處理器則沒有這個(gè)優(yōu)勢(shì),所有處理核心都會(huì)工作在相同的電壓和頻率下。
當(dāng)然,在Krait CPU中的共享L2高速緩存,也可以根據(jù)處理任務(wù)量的不同,工作在不同的電壓和頻率下。從而最大限度的節(jié)省電能。

Qualcomm MARE SDK:移動(dòng)設(shè)備并行運(yùn)算利器
Qualcomm發(fā)布的的MARE(多核異步運(yùn)行環(huán)境)是一種用于并行及異構(gòu)移動(dòng)計(jì)算的編程模型和運(yùn)行時(shí)系統(tǒng)。這種原生C++庫提供了一種簡單而優(yōu)雅的方式在多個(gè)CPU核心上實(shí)現(xiàn)并行計(jì)算,并且可以利用MARE SDK在GPU上實(shí)現(xiàn)異構(gòu)計(jì)算。
MARE SDK作為用戶級(jí)庫實(shí)施,與Android NDK相集成,提供易于使用的并行編程原語言。其應(yīng)用級(jí)摘要幫助開發(fā)者利用任意Andriod設(shè)備上的多進(jìn)程硬件進(jìn)行并行計(jì)算,而不需要深入了解有關(guān)該硬件的知識(shí)。
目前,最新版的MARE SDK已經(jīng)支持并行編程模式,這是一個(gè)包括并行迭代、并行圖、并行前綴掃描和同步數(shù)據(jù)流在內(nèi)的集合。這些模式通過優(yōu)化執(zhí)行通用并行習(xí)語,可進(jìn)一步簡化編程。另外也為諸如矩陣乘法等線性代數(shù)例程增加了對(duì)Snapdragon處理器的特定支持。
采用MARE SDK之后,一般能為需要密集計(jì)算的應(yīng)用,如拍照類應(yīng)用的實(shí)時(shí)濾鏡,帶來性能的大幅優(yōu)化,1個(gè)工程師,2天時(shí)間,圖像處理速度提高60%。線程管理和并行計(jì)算只占用五分之一的Pthread代碼。無論采用何種設(shè)備或處理器,只在Google Play中出現(xiàn)一個(gè)單一.apk文件。

big.LITTLE:助力達(dá)成8核心、64bit
當(dāng)移動(dòng)SoC跨越到64bit世代,移動(dòng)設(shè)備不僅僅要省電,還要高性能。在一些高端機(jī)型上,我們會(huì)經(jīng)常看到這樣的架構(gòu)配置:4 + 4核心,即4顆負(fù)責(zé)高強(qiáng)度運(yùn)算任務(wù)的Cortex-A57核心,還有4顆在“閑暇”時(shí)負(fù)責(zé)計(jì)算任務(wù)的Cortex-A53。然而實(shí)現(xiàn)這樣豐富的異構(gòu)計(jì)算核心技術(shù),就是ARM所提供的big.LITTLE。
運(yùn)算能力強(qiáng)的處理器核心,與低耗電、運(yùn)算能力弱的處理器核心,結(jié)合在一起。運(yùn)用在移動(dòng)計(jì)算上,多核心處理器能具備較高性能的同時(shí),其平均功耗也能維持在較低的水平。
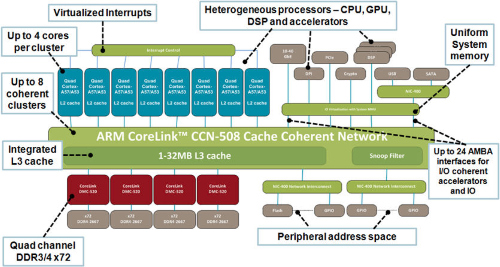
基于ARMv8體系架構(gòu)的Cortex-A53和Cortex-A57處理器在采用big.LITTLE技術(shù)協(xié)作運(yùn)行時(shí),處理器將通過 CoreLink CCN-504 一致性互連來連接,以實(shí)現(xiàn)具有完全一致性的高性能眾核解決方案。該解決方案支持在一塊硅晶片上容納多達(dá)16個(gè)內(nèi)核。
經(jīng)測(cè)量,對(duì)于中等強(qiáng)度的工作負(fù)載(例如 Web 瀏覽),節(jié)能達(dá)到 50%。而對(duì)于后臺(tái)工作負(fù)載(例如 mp3 音頻播放),節(jié)能高達(dá) 70%。
AMD在下一盤大旗:ARM + X86
2014年5月,在互聯(lián)網(wǎng)上瘋狂轉(zhuǎn)發(fā)著一張PPT,一個(gè)全新的x86與ARM共融核心。AMD對(duì)此并未過多提及,只是在介紹自主設(shè)計(jì)K12 ARM架構(gòu)的同時(shí),有一個(gè)小小的注腳寫著“開發(fā)64位ARM核心,以及新的64位x86核心”。
這兩種新架構(gòu)都會(huì)由AMD的首席架構(gòu)設(shè)計(jì)師Jim Keller統(tǒng)領(lǐng)負(fù)責(zé)。他強(qiáng)調(diào)說:“AMD的特長是打造高頻率核心,并且會(huì)將AMD大核心的高性能、ARM小核心的低功耗完美融合在一起。”
我們大致可以明白,AMD引入ARM的技術(shù),是為處理器進(jìn)一步降低功耗,以應(yīng)對(duì)未來的移動(dòng)計(jì)算大趨勢(shì)。然而另我們好奇的是,這兩種架構(gòu)如何在一起協(xié)同工作?統(tǒng)一的架構(gòu)接口和指令集是必要的。

總結(jié):異構(gòu)計(jì)算未來必將豐富多彩
異構(gòu)計(jì)算的未來會(huì)相當(dāng)豐富。在桌面端,將繼續(xù)依靠GPU的大規(guī)模并行計(jì)算能力,不斷突破人類計(jì)算的極限。而在手機(jī)端big.LITTLE將聯(lián)合不同類型的CPU,展現(xiàn)出強(qiáng)大的性能。
未來的移動(dòng)計(jì)算,需要閑時(shí)更加省電,這需要借助DSP、低功耗處理器的幫忙。同時(shí)也需要在瞬時(shí)展現(xiàn)出更強(qiáng)大的性能,而這更需要借助移動(dòng)GPU進(jìn)行異構(gòu)計(jì)算。
作為移動(dòng)應(yīng)用的開發(fā)者,可以借助RenderScript開發(fā)出強(qiáng)大的Android應(yīng)用。更可以使用如Adreno SDK、MARE SDK等第一方芯片廠商的方案,輕松為應(yīng)用做更深層的優(yōu)化。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


