
【編者按】盤點AWS生態圈,Netflix無疑是其最有價值用戶之一――在公布了大量基于AWS開源工具及調優的同時,還發表了多個AWS環境下高價值的基準測試。近日,Netflix在更貼近現在生產環境下重測了Cassandra性能。

免費訂閱“CSDN大數據”微信公眾號,實時了解最新的大數據進展!
CSDN大數據,專注大數據資訊、技術和經驗的分享和討論,提供Hadoop、Spark、Imapala、Storm、HBase、MongoDB、Solr、機器學習、智能算法等相關大數據觀點,大數據技術,大數據平臺,大數據實踐,大數據產業資訊等服務。
以下為譯文:
在2011年11月發表的文章“ NetFlix測試Cassandra――每秒百萬次寫入”中我們展示了Cassandra (C*)如何在集群節點增加時實現性能線性增長。隨著新型EC2實例類型的產生,我們決定重做一次性能測試,與之前帖子不同,這次的重心不是C*可擴展性,而是量化這些新實例的性能指標。下面是此次測試的詳細信息及結果。
此次測試的C*集群運行于Datastax 3.2.5企業版,C*版本為1.2.15.1,共有285個節點。實例類型為i2.xlarge器,運行于Heap為12GB的JVM 1.7.40_b43之上。使用的OS為Ubuntu 12.04 LTS。數據與日志使用相同的EXT3格式掛載文件。
盡管上次測試使用了較高規格的m1.xlarge服務器,此次測試的吞吐量結果依然與上次持平,而且選擇(支持SSD)i2.xlarge規格服務器更加貼近現實用例,能更好的展示其吞吐量與延遲。
完整的schema如下:
create keyspace Keyspace1
with placement_strategy = ‘NetworkTopologyStrategy’
and strategy_options = {us-east : 3
and durable_writes = true;
use Keyspace1;
create column family Standard1
with column_type = ‘Standard’
and comparator = ‘AsciiType’
and default_validation_class = ‘BytesType’
and key_validation_class = ‘BytesType’
and read_repair_chance = 0.1
and dclocal_read_repair_chance = 0.0
and populate_io_cache_on_flush = false
and gc_grace = 864000
and min_compaction_threshold = 999999
and max_compaction_threshold = 999999
and replicate_on_write = true
and compaction_strategy = ‘org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy’
and caching = ‘KEYS_ONLY’
and column_metadata = [
{column_name : 'C4',
validation_class : BytesType},
{column_name : 'C3',
validation_class : BytesType},
{column_name : 'C2',
validation_class : BytesType},
{column_name : 'C0',
validation_class : BytesType},
{column_name : 'C1',
validation_class : BytesType}]
and compression_options = {‘sstable_compression’ : ”};
請注意到這里的min_compaction_threshold和max_compaction_threshold值很高,盡管在實際產品中不可能使用完全一致的數據,但也能實際反映我們所想掌握的數據。
客戶端
客戶端應用程序使用Cassandra Stress,有60個客戶端節點,實例類型為r3.xlarge,為之前m2.4xlarge規格實例數量的一半,價格也是之前的一半,但依然能夠推動所需負載(使用線程低于40%)并達到與之前相同的吞吐量。客戶端運行在基于Ubuntu 12.04 LTS系統的JVM 1.7.40_b43之上。
網絡拓撲
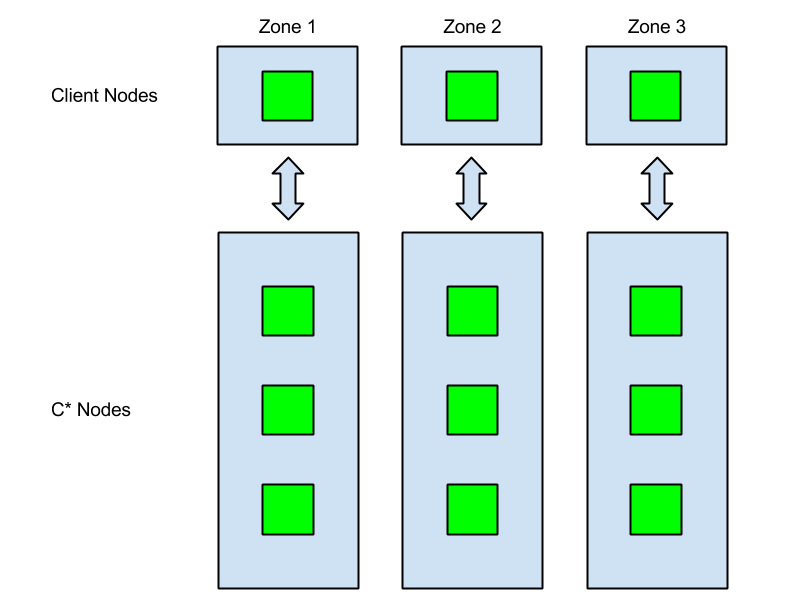
Netflix的Cassandra集群有3個副本,部署在3個不同的可用區域(Availability Zones,即AZ)。這樣,如果其中一個AZ斷電,余下的2個副本依然可以繼續工作。
之前帖子里所有的客戶端都部署同一個AZ中,這次的改變遵從實際產品都部署在三個不同AZ的真實應用場景。客戶端請求一般交于相同AZ的C*節點,我們稱之為zone-aware連接,這一特征被構建到Netflix C* Java客戶端Astyanax中。Astyanax客戶端通過查詢記錄信息向相應實例服務端發送讀寫請求。盡管C*協調器能夠實現所有請求,但當實例不在副本集中的情況發生時,則需要一個額外的網絡躍點,即token-aware請求。
此次測試使用Cassandra Stress,因此不需要token-aware請求。而通過一些簡單的grep和awk-fu,我們可以得知此次測試屬于zone-aware連接范疇,是網絡拓撲結構里比較典型的實際產品案例。
延遲及吞吐量測量
我們已經文檔化了使用Priam完成令牌任務、備份和存儲的方法。Priam內部版本添加了一些額外功能,我們使用Priam協助收集C* JMX自動測量結果并發送到分析平臺Atlas, 此功能將在未來幾周添加至Priam 開源版本中。
以下是用于測量延遲與吞吐量的JMX屬性:
延遲
吞吐量
測試
我執行了以下4組測試:
100%寫入
與原帖測試不同,此次測試展示了持久性大于每秒100萬次寫入的用例。現實中只寫入的應用程序很少,這種類型的應用要么是遙測系統要么是物聯網應用,其相關測試數據被輸入BI系統進行分析。
CL One
與原帖測試相似,此次測試運行在CL One上。其平均延遲略高于5毫秒,第95百分位為10毫秒
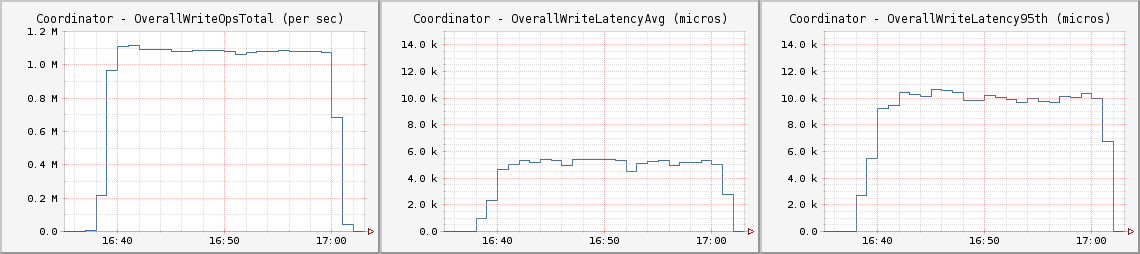
每個客戶節點都運行如下Cassandra Stress命令:
cassandra-stress -d [list of C* IPs] -t 120 -r -p 7102 -n 1000000000 -k -f [path to log] -o INSERT
CL LOCAL_QUORUM
為了保證用例讀入的高一致性,這次我們測試了運行于LOCAL_QUORUM CL上吞吐量大于每秒百萬次寫入的用例。每秒100萬次寫入吞吐量平均延遲低于6毫秒,第95百分位為17毫秒
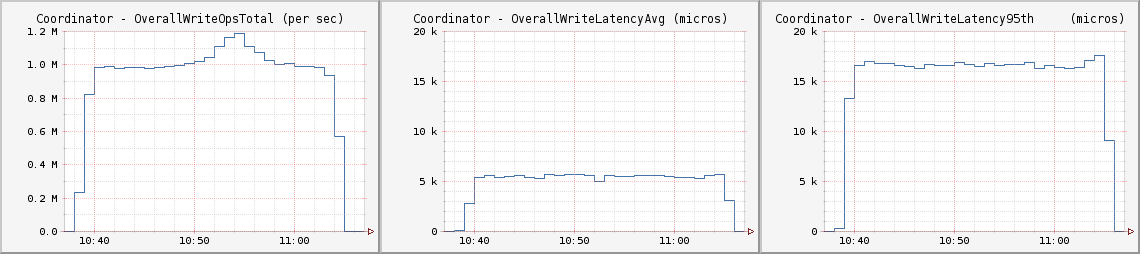
每個客戶節點都運行如下Cassandra Stress命令:
cassandra-stress -d [list of C* IPs] -t 120 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f [path to log] -o INSERT
綜合測試――10%寫入90%讀入
每秒100萬次寫入只是一個醒目的標題,大多數應用程序都是讀寫混合的。在對Netflix主要應用程序調研之后,我決定做一個10%寫入90%讀入的綜合測試,這一混合測試占用總線程的10%用于寫入90%用于讀取。這雖然不是實際應用程序的真實復現,但也能很好的測量數據擁塞時集群吞吐量及延遲
CL One
使用CL One配備時,C*實現了最高的吞吐量及可用性,開發人員需要接受其結果的一致性,并模仿這一范例設計他們的應用程序。
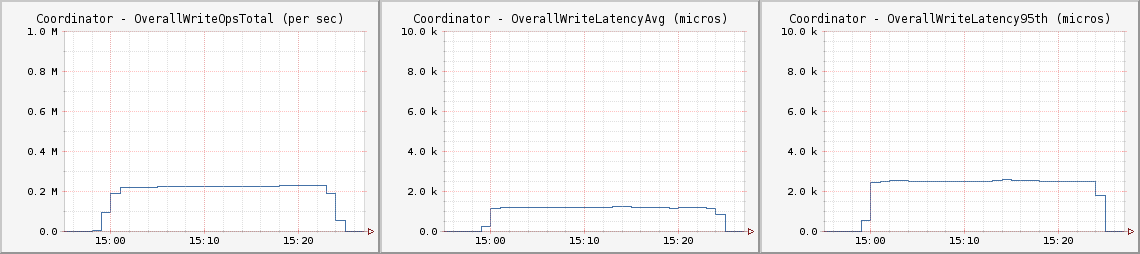
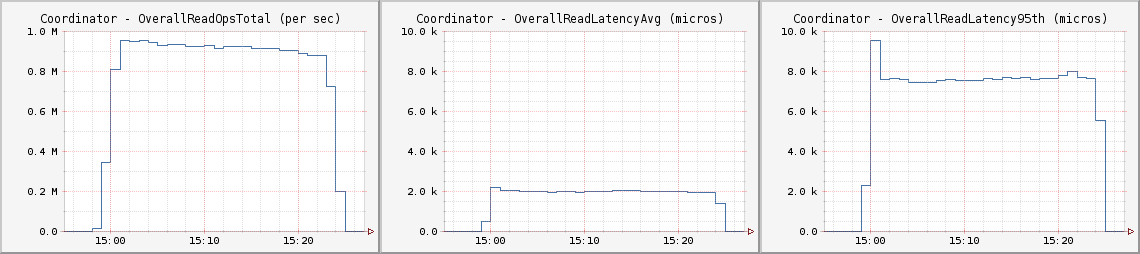
每個客戶節點都運行如下Cassandra Stress命令:
cassandra-stress -d $cCassList -t 30 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f /data/stressor/stressor.log -o INSERT<br>cassandra-stress -d $cCassList -t 270 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f /data/stressor/stressor.log -o READ
CL LOCAL_QUORUM
大多數用C*開發的應用程序都將默認為CL Quorum讀寫,這為其相關開發人員進入分布式數據庫系統提供了機會,也避免了解決應用程序最終一致性的難題。
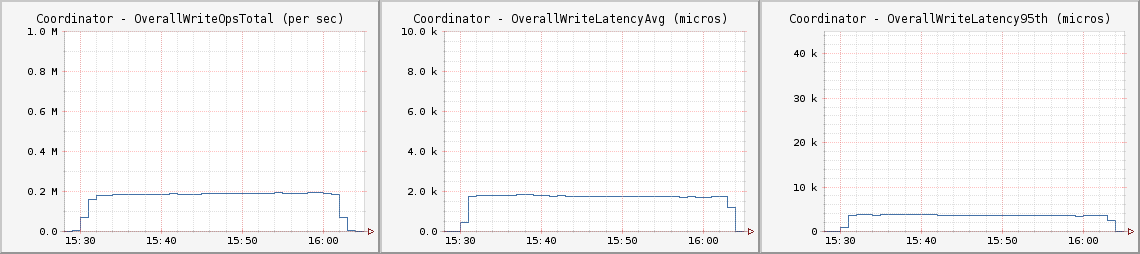
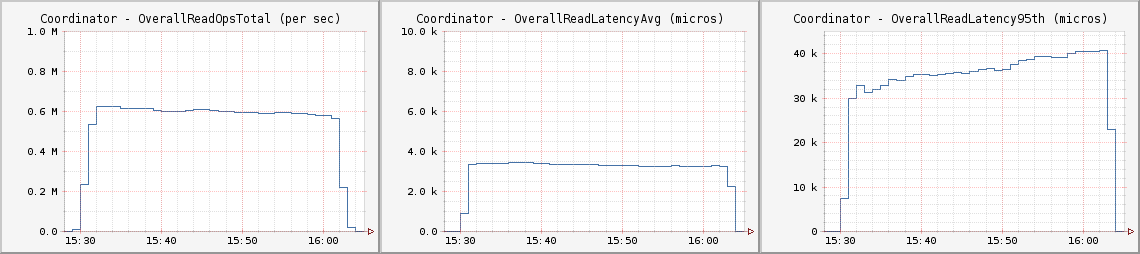
每個客戶節點都運行如下Cassandra Stress命令:
cassandra-stress -d $cCassList -t 30 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f [path to log] -o INSERT<br>cassandra-stress -d $cCassList -t 270 -r -p 7102 -e LOCAL_QUORUM -n 1000000000 -k -f [path to log] -o READ
費用
這次測試的總開銷包括EC2實例費用和inter-zone網絡流量費用,我使用Boundary監控C*網絡使用情況。
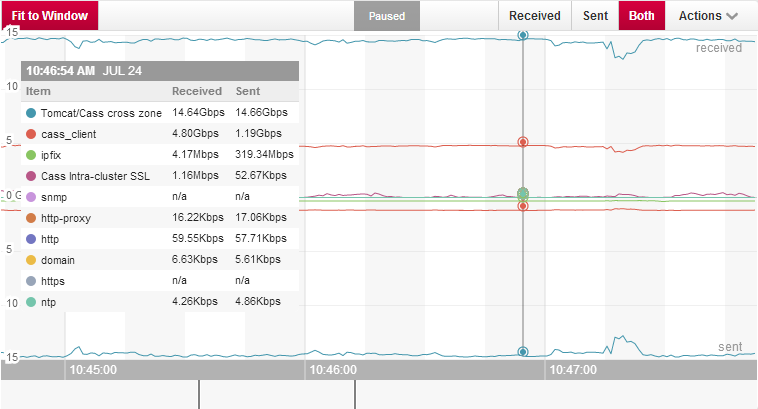
上圖顯示了可用服務區域間30Gbps的傳輸速度。
這里是執行每秒100萬次寫入測試的費用:
|
Instance Type / Item |
Cost per Minute |
Count |
Total Price per Minute |
|
|
i2.xlarge |
$0.0142 |
285 |
$4.047 |
|
|
r3.xlarge |
$0.0058 |
60 |
$0.348 |
|
|
Inter-zone traffic |
$0.01 per GB |
3.75 GBps * 60 = 225GB per minute |
$2.25 |
|
|
Total Cost per minute |
$6.645 |
|||
|
Total Cost per half Hour |
$199.35 |
|||
|
Total Cost per Hour |
$398.7 |
結語
大多數企業可能不需要處理這么多數據,這項測試很好的展示了新型AWS i2和r3實例類型的花費、延遲及吞吐量。每一個應用程序都是不一樣的,你的情況也會不盡相同。
這次測試耗費了我一周的空閑時間,并不是一個詳盡的性能研究,我也沒有對C*系統或JVM作深入調研,你有可能會比我做的更好。如果你有興趣研究大規模分布式數據庫及性能提升,歡迎加入Netflix CDE組。
原文鏈接:Revisiting 1 Million Writes per second(翻譯/應玲 責編/仲浩)

上一篇 深圳綜合交通設計研究院張
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


