Hadoop導航:版本、生態圈及MapReduce模型
來源:程序員人生 發布時間:2014-09-26 13:38:46 閱讀次數:3243次
【編者按】經過數年的發展,Hadoop已成為通用的海量數據處理平臺。然而打開Hadoop版本發布頁,不同方法計算的版本號讓人眼花繚亂。那么對于初學者或者已經使用了Hadoop的機構究竟該如何進行選擇?MapReduce的工作模型究竟是什么樣的?這里我們一起看@萬境絕塵近日發表的博客。
CSDN推薦:歡迎免費訂閱《Hadoop與大數據周刊》獲取更多Hadoop技術文獻、大數據技術分析、企業實戰經驗,生態圈發展趨勢。
以下為原文:
Hadoop版本和生態圈
1. Hadoop版本
(1) Apache Hadoop版本介紹
Apache的開源項目開發流程:
- 主干分支:新功能都是在主干分支(trunk)上開發。
- 特性獨有分支:很多新特性穩定性很差,或者不完善,在這些分支的獨有特定很完善之后,該分支就會并入主干分支。
- 候選分支:定期從主干分支剝離,一般候選分支發布,該分支就會停止更新新功能,如果候選分支有BUG修復,就會重新針對該候選分支發布一個新版本,候選分支就是發布的穩定版本。
造成Hadoop版本混亂的原因:
- 主要功能在分支版本開發:0.20分支發布之后,主要功能一直在該分支上進行開發,主干分支并沒有合并這個分支,0.20分支成為了主流。
- 低版本的后發布:0.22版本發布要晚于0.23版本。
- 版本重命名:0.20分支的0.20.205版本重命名為1.0版本,這兩個版本是一樣的,只是名字改變了。
Apache Hadoop版本示意圖:
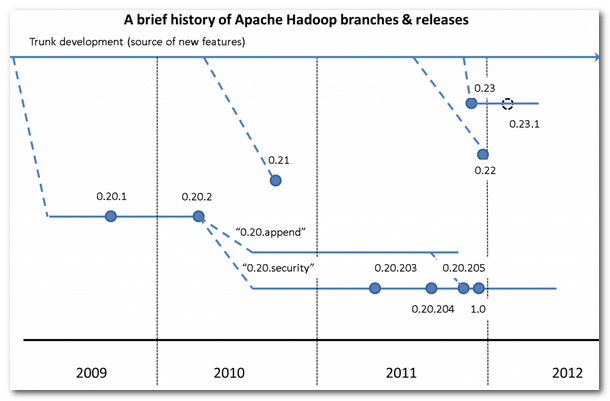
(2) Apache Hadoop版本功能介紹
第一代Hadoop特性:
- append:支持文件追加功能,讓用戶使用HBase的時候避免數據丟失,也是使用HBase的前提。
- raid:保證數據可靠,引入校驗碼校驗數據塊數目。
- symlink:支持HDFS文件鏈接。
- security:hadoop安全機制。
- namenode HA:為了避免namenode單點故障情況,HA集群有兩臺namenode。
第二代Hadoop特性:
- HDFS Federation:NameNode制約HDFS擴展,該功能讓多個NameNode分管不同目錄,實現訪問隔離和橫向擴展。
- yarn:MapReduce擴展性和多框架方面支持不足,yarn是全新的資源管理框架,將JobTracker資源管理和作業控制功能分開,ResourceManager負責資源管理,ApplicationMaster負責作業控制。
0.20版本分支:只有這個分支是穩定版本,其它分支都是不穩定版本。
- 0.20.2版本(穩定版):包含所有特性,經典版。
- 0.20.203版本(穩定版):包含append,不包含symlink raid namenodeHA功能。
- 0.20.205版本/1.0版本(穩定版):包含append security,不包含symlink raid namenodeHA功能。
- 1.0.1~1.0.4版本(穩定版):修復1.0.0的bug和進行一些性能上的改進。
0.21版本分支(不穩定版):包含append raid symlink namenodeHA,不包含security。
0.22版本分支(不穩定版):包含 append raid symlink那么弄得HA,不包含mapreduce security。
0.23版本分支:
- 0.23.0版本(不穩定版):第二代的hadoop,增加了HDFS Federation和yarn。
- 0.23.1~0.23.5(不穩定版):修復0.23.0的一些BUG,以及進行一些優化。
- 2.0.0-alpha~2.0.2-alpha(不穩定版):增加了namenodeHA 和 Wire-compatiblity功能。
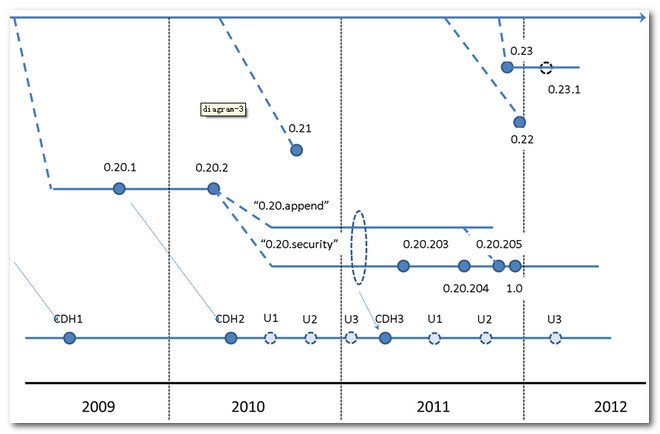
(3) Cloudera Hadoop對應Apache Hadoop版本
2. Hadoop生態圈
Apache支持:Hadoop的核心項目都受Apache支持的,除了Hadoop之外,還有下面幾個項目,也是Hadoop不可或缺的一部分。
- HDFS:分布式文件系統,用于可靠的存儲海量數據。
- MapReduce:分布式處理數據模型,可以運行于大型的商業云計算集群中。
- Pig:數據流語言和運行環境,用來檢索海量數據集。
- HBase:分布式數據庫,按列存儲,HBase使用HDFS作為底層存儲,同時支持MapReduce模型的海量計算和隨機讀取。
- Zookeeper:提供Hadoop集群的分布式的協調服務,用于構建分布式應用,避免應用執行失敗帶來的不確定性損失。
- Sqoop:該工具可以用于HBase 和 HDFS之間的數據傳輸,提高數據傳輸效率。
- Common:分布式文件系統,通用IO組件與接口,包括序列化、Java RPC和持久化數據結構。
- Avro:支持高效跨語言的RPC及永久存儲數據的序列化系統。
MapReduce模型簡介
MapReduce簡介:MapReduce是一種數據處理編程模型。
- 多語言支持:MapReduce可以使用各種語言編寫,例如Java、Ruby、Python、C++。
- 并行本質 :MapReduce 本質上可以并行運行的。
1. MapReduce數據模型解析
MapReduce數據模型:
- 兩個階段:MapReduce的任務可以分為兩個階段,Map階段和Reduce階段。
- 輸入輸出:每個階段都使用鍵值對作為輸入和輸出,IO類型可以由程序員進行選擇。
- 兩個函數:map函數和reduce函數。
MapReduce作業組成:一個MapReduce工作單元,包括輸入數據,MapReduce程序和配置信息。
作業控制:作業控制由JobTracker(一個)和TaskTracker(多個)進行控制的。
- JobTracker作用:JobTracker控制TaskTracke上任務的運行,進行統一調度。
- TaskTracker作用:執行具體的MapReduce程序。
- 統一調度方式:TaskTracker運行的同時將運行進度發送給JobTracker,JobTracker記錄所有的TaskTracker。
- 任務失敗處理:如果一個TaskTracker任務失敗,JobTracker會調度其它TaskTracker上重新執行該MapReduce作業。
2. Map數據流
輸入分片:MapReduce程序執行的時候,輸入的數據會被分成等長的數據塊,這些數據塊就是分片。
- 分片對應任務:每個分片都對應著一個Map任務,即MapReduce中的map函數。
- 并行處理:每個分片執行Map任務要比一次性處理所有數據時間要短。
- 負載均衡:集群中的計算機有的性能好有的性能差,按照性能合理的分配分片大小,比平均分配效率要高,充分發揮出集群的效率。
- 合理分片:分片越小負載均衡效率越高,但是管理分片和管理map任務總時間會增加,需要確定一個合理的分片大小,一般默認為64M,與塊大小相同。
數據本地優化:map任務運行在本地存儲數據的節點上,才能獲得最好的效率。
- 分片=數據塊:一個分片只在單個節點上存儲,效率最佳。
- 分片>數據塊:分片大于數據塊,那么一個分片的數據就存儲在了多個節點上,map任務所需的數據需要從多個節點傳輸,會降低效率。
Map任務輸出:Map任務執行結束后,將計算結果寫入到本地硬盤,不是寫入到HDFS中。
- 中間過渡:Map的結果只是用于中間過渡,這個中間結果要傳給Reduce任務執行,reduce任務的結果才是最終結果,map中間值最后會被刪除。
- map任務失敗:如果map任務失敗,會在另一個節點重新運行這個map任務,再次計算出中間結果。
3. Reduce數據流
Reduce任務:map任務的數量要遠遠多于Reduce任務。
- 無本地化優勢:Reduce的任務的輸入是Map任務的輸出,reduce任務的絕大多數數據本地是沒有的。
- 數據合并:map任務輸出的結果,會通過網絡傳到reduce任務節點上,先進行數據的合并,然后在輸入到reduce任務中進行處理。
- 結果輸出:reduce的輸出直接輸出到HDFS中。
- reduce數量:reduce數量是特別指定的,在配置文件中指定。
MapReduce數據流框圖解析:
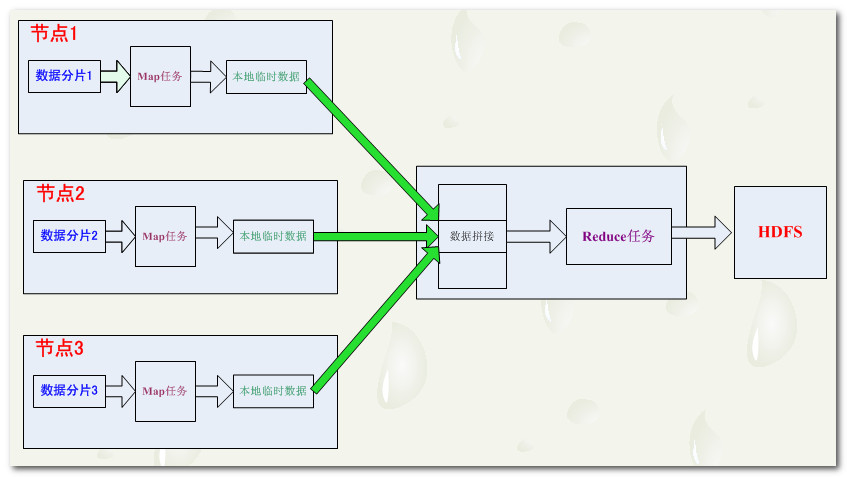
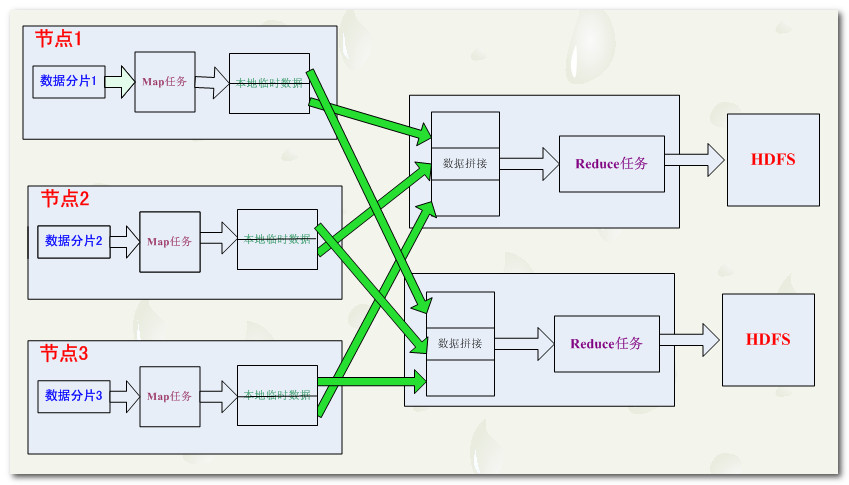

Map輸出分區:多個reduce任務,每個reduce任務都對應著一些map任務,我們將這些map任務根據其輸入reduce任務進行分區,為每個reduce建立一個分區。
- 分區標識:map結果有許多種類鍵,相同的鍵對應的數據傳給一個reduce,一個map可能會給多個reduce輸出數據。
- 分區函數:分區函數可以由用戶定義,一般情況下使用系統默認的分區函數partitioner,該函數通過哈希函數進行分區。
混洗:map任務和reduce任務之間的數據流成為混。
- reduce數據來源:每個reduce任務的輸入數據來自多個map
- map數據去向:每個map任務的結果都輸出到多個reduce中
沒有Reduce:當數據可以完全并行處理的時候,就可以不適用reduce,只進行map任務。
4. Combiner 引入
MapReduce瓶頸:帶寬限制了MapReduce執行任務的數量,Map和Reduce執行過程中需要進行大量的數據傳輸。
解決方案:合并函數Combiner,將多個Map任務輸出的結果合并,將合并后的結果發送給Reduce作業。
5. HadoopStreaming
Hadoop多語言支持:Java、Python、Ruby、C++
- 多語言:Hadoop允許使用其它語言寫MapReduce函數。
- 標準流:因為Hadoop可以使用UNIX標準流作為Hadoop和應用程序之間的接口,因此只要使用標準流,就可以進行MapReduce編程。
Streaming處理文本:Streaming在文本處理模式下,有一個數據行視圖,非常適合處理文本。
- Map函數的輸入輸出:標準流一行一行的將數據輸入到Map函數,Map函數的計算結果寫到標準輸出流中。
- Map輸出格式:輸出的鍵值對是以制表符分隔的行,以這種形式寫出的標準輸出流中。
- Reduce函數的輸入輸出:輸入數據是標準輸入流中的通過制表符分隔的鍵值對行,該輸入經過了Hadoop框架排序,計算結果輸出到標準輸出流中。
6. Hadoop Pipes
Pipes概念:Pipes是MapReduce的C++接口
- 理解誤區:Pipes不是使用標準輸入輸出流作為Map和Reduce之間的Streaming,也沒有使用JNI編程。
- 工作原理:Pipes使用套接字作為map和reduce函數進程之間的通信。
原文鏈接:
Hadoop 版本 生態圈 MapReduce模型(責編/仲浩)
以“云計算大數據 推動智慧中國 ”為主題的
第六屆中國云計算大會 將于5月20-23日在北京國家會議中心隆重舉辦。產業觀察、技術培訓、主題論壇、行業研討,內容豐富,干貨十足。票價優惠,馬上
報名 !
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈




