
【編者按】DDoS攻擊的模式改變了傳統的點對點的攻擊模式,使攻擊方式出現了沒有規律的情況,而且在進行攻擊的時候,通常使用的也是常見的協議和服務,這樣只是從協議和服務的類型上是很難對攻擊進行區分。在進行攻擊的時候,攻擊數據包都是經過偽裝的,在源IP 地址上也是進行偽造的,這樣就很難對攻擊進行地址的確定,在查找方面也是很難的。本文將針對應用層的DDoS攻擊的實現、防范,以及一個防火墻內核模塊的實現做了詳細解讀,本文來作者個人博客。
 免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
CSDN作為國內最專業的云計算服務平臺,提供云計算、大數據、虛擬化、數據中心、OpenStack、CloudStack、Hadoop、Spark、機器學習、智能算法等相關云計算觀點,云計算技術,云計算平臺,云計算實踐,云計算產業資訊等服務。
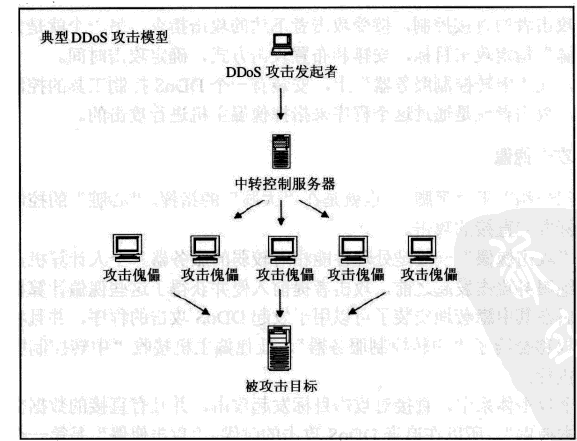
DDoS,即 Distributed Denial of Service ,可譯為分散式阻斷服務攻擊。
上圖與DDoS的字面已經清楚的表述出了此類攻擊的原理,勿需多言。這類攻擊泛濫存在的主要原因之一是網絡服務的開放性,這一特點導致了DDoS攻擊無法根本杜絕,目前主要應對策略是積極防御與消極防御。
典型DDoS的攻擊方式:
死亡之Ping
icmp封裝于IP報文之中,而IP對于很大的數據載荷采用分片傳輸的策略,而接收方需要對這些IP分片進行重組,如果接收方的重組算法不能很好地處理意外情況,后果會很嚴重,典型的意外情況包括:
1.連續分片的偏移量之間不符合它們應該的邏輯關系,攻擊者偽造出這樣的一系列分包是很容易的;
2.重組完成后的IP頭與數據載荷,總長度竟超過了IP報文總長2^16字節(64kB)的限制,一個實現的例子是,前面各分片一律正常,唯有最后一個IP分片的數據載荷盡量填充到最大,如達到以太網最大傳輸單元MTU 1500字節上限,這樣重組后的報文總長度就達到了約(64kB+1500B-20B-8B=65.44kB)的大小。
這種攻擊方式附加了對目標系統協議棧算法的漏洞利用。
淚滴TearDrop
淚滴攻擊指的是向目標機器發送損壞的IP包,諸如重疊的包或過大的包載荷。借由這些手段,該攻擊可以通過TCP/IP協議棧中分片重組代碼中的bug來癱瘓各種不同的操作系統。(此段摘自維基百科中文,實現方式可參考上死亡之Ping)
UDP洪水
UDP是一種無連接協議,當數據包通過 UDP 發送時,所有的數據包在發送和接收時不需要進行握手驗證。當大量 UDP 數據包發送給受害系統時,可能會導致帶寬飽和從而使得合法服務無法請求訪問受害系統。遭受 DDoS UDP 洪泛攻擊時,UDP 數據包的目的端口可能是隨機或指定的端口,受害系統將嘗試處理接收到的數據包以確定本地運行的服務。如果沒有應用程序在目標端口運行,受害系統將對源IP發出 ICMP 數據包,表明“目標端口不可達”。某些情況下,攻擊者會偽造源IP地址以隱藏自己,這樣從受害系統返回的數據包不會直接回到僵尸主機,而是被發送到被偽造地址的主機。有時 UDP 洪泛攻擊也可能影響受害系統周圍的網絡連接,這可能導致受害系統附近的正常系統遇到問題。然而,這取決于網絡體系結構和線速。(此段摘自維基百科中文)
TCP RST 攻擊
TCP協議存在安全漏洞,正常的TCP連接可以被非法的第三方復位,這是因為TCP連接通訊不包含認證的功能。如,在已知連接的五元組的情況下,攻擊者可以偽造帶有RST/SYN標志的TCP報文或普通數據報文,當其sequence number落在TCP連接的滑動窗口范圍內,可能導致會話終止或者虛假數據插入。(這里僅僅提一下,詳細可參考文章《 從TCP協議的原理來談談rst復位攻擊》、《 憶龍2009:TCP非法復位漏洞及解決方法》)
TCP 全連接攻擊
龐大的攻擊群同時地、不斷地與目標服務器建立正常的TCP連接,從而嚴重影響正常用戶的連接服務。
Syn Flood
攻擊者向目標服務器發送大量(偽造源IP地址、偽造源端口、正確目標IP地址、正確目標端口)tcp syn數據包,目標服務器為了維持這么大量的虛假連接,大量的tcp狀態機維持在了SYN_RCVD狀態,嚴重地影響了處理速度與消耗了系統資源,而反觀攻擊者,偽造并發送這些小數據包,各項資源消耗都極低,對于網絡傳輸速度為3Mb/s的一個攻擊者來說,攻擊包的速率大約可達每秒(3Mb/8/40=9830)個,如果網絡傳輸速度達到30Mb/s,單個攻擊者的攻擊包速率可為98300/s,如果再考慮到分布式攻擊,情況將變得極為惡劣。
CC攻擊
CC,即 Chanllenge Collapsar ,可直譯為 黑洞挑戰,CC攻擊是 DDoS 攻擊的一種類型,使用代理服務器向受害服務器發送大量貌似合法的請求,巧妙之處在于,網絡上有許多免費代理服務器,甚至很多都支持匿名代理,所以其優點為:
1.攻擊者事先不需要抓取攻擊傀儡,但仍需得到可用的、符合要求的代理 ip:port 列表;
2.匿名代理,使得追蹤變得非常困難,但并非不可能!
四層及以下的DDoS防御:
新型攻擊方式的產生、流行,必然導致對應防御策略的出現。
而針對四層及四層以下的DDoS攻擊,現在的硬件防火墻大多都能對死亡之Ping、icmp洪水、淚滴等做到很好的防御效果,所以,這里重點介紹SynFlood的若干防御策略:
SynCookie:等到系統資源到達某一臨界點,內核協議棧啟用SynCookie機制,進行Syn包源IP:PORT驗證,它本身是一種非常巧妙的實現,具體可參考文章《 SYN Cookie的原理和實現》;
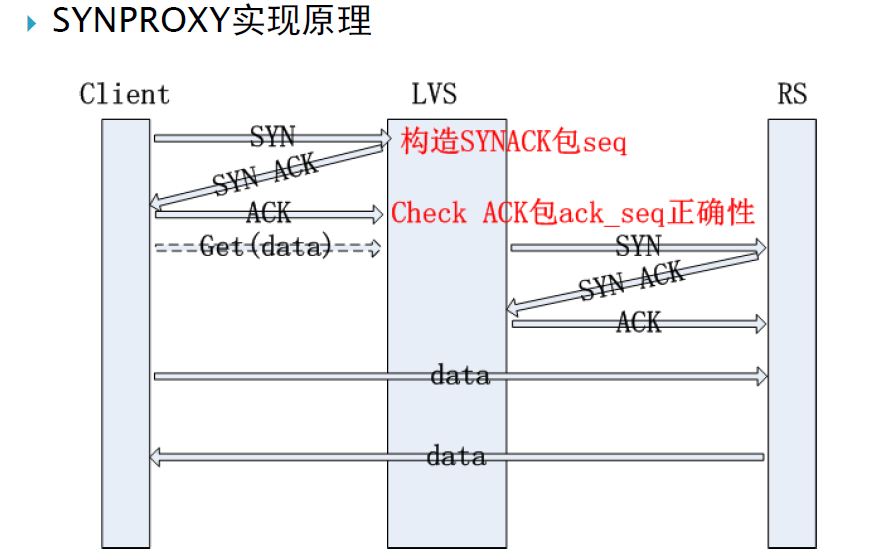
SynProxy:即Syn代理,一般可在前端防火墻上實現,不過,淘寶開源項目ipvs維護者吳佳明先生已經在內核層實現了這一功能,可理解為SynCookie+Proxy,請訪問 https://github.com/alibaba/LVS/獲得最新源碼與項目文檔;
SynCheck:對Syn包依據一定的規則進行檢驗,以過濾掉一部分不規則的包;
SynFirstDrop:Syn首包丟棄策略,但如果攻擊者將偽造的Syn報文發送兩次,這種方法就失去了效果。
以上的這些常見防御方法都可以分別通過硬件和軟件來實現,一般來講,硬件防火墻處理能力要比軟件方法強,但價格也更加昂貴,盡管軟件實現性能會有下降,但也沒有太差,例如,ipvs工作于內核層,淘寶在大部分網站使用其作為Director,下面是一些官方數據:

如果在上面這些數據的基礎之上,前端Director實現集群以分擔系統負載,性能將會更佳,可見軟件防火墻在使用的得當的情況之下,能極大降低系統成本,而且性能理想,這是經過淘寶的系統實際驗證了的。
我們將要實現一個進行應用層DDoS攻擊的工具,綜合考慮,CC攻擊方式是最佳選擇,并用bash shell腳本來快速實現并驗證這一工具,并在最后,討論如何防御來自應用層的DDoS攻擊。
第一步:獲取大量可用代理ip:port列表
網上所處可見免費代理,我們使用http的GET方法抓取html文檔,接著使用正則過濾出我們需要的ip port對,然后逐一驗證各代理的可用性,最終得到可用的代理ip port對。
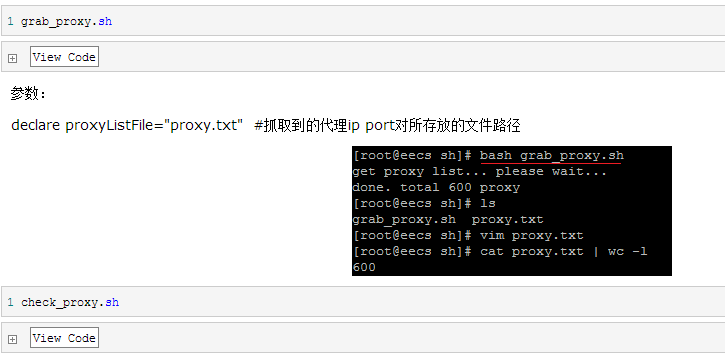
參數:
declare check_threads=10 #驗證代理可用性時的并發數,看一下代碼就會發現,我們使用的是GET http://baidu.com方法,所以,并發數請不要也太高,除非你的目標就是......
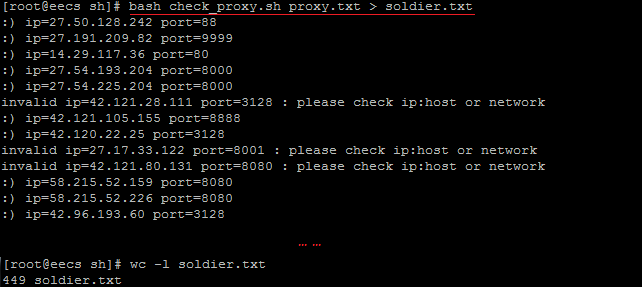
總結:應征入伍的士兵共計600人,經過考核的共計449人,如果你還想招募更多的士兵,奉勸一句,苦海無邊,回頭是岸。
第二步:吹響戰爭號角
筆者在一臺VPS上建立了一個薄弱的靶機,各位讀者請不要太暴力,測試一下就可以了,地址 http://eecs.cc:8080/
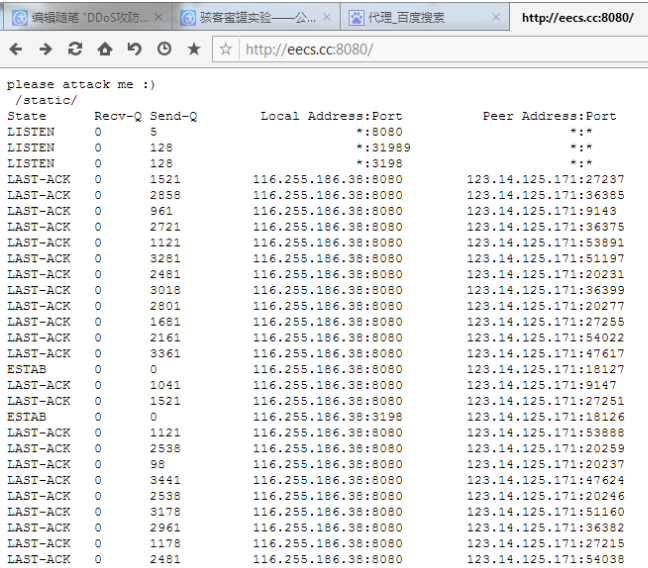
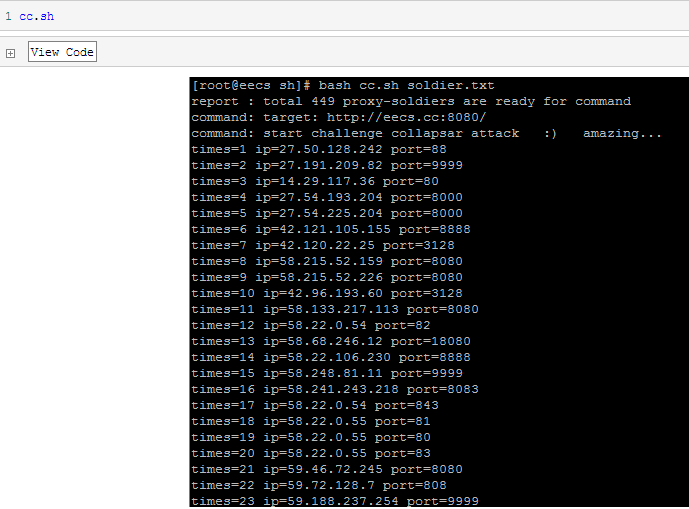
讀者可自行嘗試攻擊這個站點,然后使用瀏覽器訪問查看服務器網絡狀況,此時大量連接處于TIME_WAIT狀態,參考TCP狀態機,這一狀態為主動關閉一方的最終等待狀態。(編者注:請不要惡意攻擊別人的網站)
應用層DDoS的防御理論:
問題模型描述:
每一個頁面,都有其資源消耗權重,靜態資源,權重較低,動態資源,權重較高。對于用戶訪問,有如下:
用戶資源使用頻率=使用的服務器總資源量/s
命題一:對于正常訪問的用戶,資源使用頻率必定位于一個合理的范圍,當然會存在大量正常用戶共享ip的情況,這就需要日常用戶訪問統計,以得到忠實用戶ip白名單。
命題二:資源使用頻率持續異常的,可斷定為訪問異常的用戶。
防御體系狀態機:
1.在系統各項資源非常寬裕時,向所有ip提供服務,每隔一段時間釋放一部分臨時黑名單中的ip成員;
2.在系統資源消耗達到某一閾值時,降低Syn包接受速率,循環:分析最近時間的日志,并將訪問異常的ip加入臨時黑名單;
3.若系統資源消耗慢慢回降至正常水平,則恢復Syn包接受速率,轉到狀態1;若目前策略并未有效地控制住系統資源消耗的增長,情況繼續惡劣至一極限閾值,轉到狀態4;
4.最終防御方案,使用忠實用戶ip白名單、異常訪問ip黑名單策略,其他訪問可慢慢放入,直到系統資源消耗回降至正常水平,轉到狀態1。
上述的防御狀態機,對于單個攻擊IP高并發的DDOS,變化到狀態3時,效果就完全體現出來了,但如果防御狀態機進行到4狀態,則有如下兩種可能:
1.站點遭到了攻擊群龐大的、單個IP低并發的DDOS攻擊;
2.站點突然間有了很多訪問正常的新用戶。
建議后續工作:
保守:站點應盡快進行服務能力升級。
積極:盡所能,追溯攻擊者。
追溯攻擊者:
CC:proxy-forward-from-ip
單個IP高并發的DDOS:找到訪問異常的、高度可疑的ip列表,exploit,搜集、分析數據,因為一個傀儡主機可被二次攻占的概率很大(但不建議這種方法)
單個IP低并發的DDOS:以前極少訪問被攻擊站點,但是在攻擊發生時,卻頻繁訪問我們的站點,分析日志得到這一部分ip列表
追溯攻擊者的過程中,snat與web proxy增加了追蹤的難度,如果攻擊者采用多個中繼服務器的方法,追溯將變得極為困難。
防御者:
1.應對當前系統了如指掌,如系統最高負載、最高數據處理能力,以及系統防御體系的強項與弱點
2.歷史日志的保存、分析
3.對當前系統進行嚴格安全審計
4.上報公安相關部分,努力追溯攻擊者
5.網站,能靜態,就一定不要動態,可采取定時從主數據庫生成靜態頁面的方式,對需要訪問主數據庫的服務使用驗證機制
6.防御者應能從全局的角度,迅速及時地發現系統正在處于什么程度的攻擊、何種攻擊,在平時,應該建立起攻擊應急策略,規范化操作,免得在急中犯下低級錯誤
對歷史日志的分析這時將會非常重要,數據可視化與統計學的方法將會很有益處:
1.分析每個頁面的平均訪問頻率
2.對訪問頻率異常的頁面進行詳細分析 分析得到ip-頁面訪問頻率
3.得到對訪問異常頁面的訪問異常ip列表
4.對日志分析得到忠實用戶IP白名單
5.一般一個頁面會關聯多個資源,一次對于這樣的頁面訪問往往會同時增加多個資源的訪問數,而攻擊程序一般不會加載這些它不感興趣的資源,所以,這也是一個非常好的分析突破點
實現方案選擇:
硬件實現或者軟件實現?
在面對諸如大量畸形包這樣的攻擊時,硬件實現將會是非常好的選擇,這是因為在進行此類型的封包過濾時,系統需要記憶的狀態很少(對于FPGA、ASIC諸多硬件實現方案來講,記憶元件的成本決不可忽視,寄存器與靜態RAM都非常昂貴,所以當需要記憶的信息很少時,純硬件方案的速度優勢使得其完勝軟件方案)。
但是,當狀態機需要處理龐大的記憶信息時,我們就需要選擇廉價的存儲器――動態隨機存儲器(如SDRAM中的DDR3)來作為系統狀態機的存儲介質,以降低系統的成本和復雜度。這時,軟件實現更勝一籌。盡管純硬件實現的速度會比軟件的方式高出很多,但我們也從第一篇文章《 DDoS攻防戰 (一) : 概述》中lvs性能的測試結果中看到,軟件實現的、作為服務器前端均衡調度器的lvs,性能理想并且能勝任實際生產環境中的、龐大的用戶請求處理,可見,如果設計合理,軟件實現的性能無需過多擔憂。
最終,我們決定采用軟件的方法來實現所需的ip黑白名單模塊。
最終系統鳥瞰:
筆者花費大約二十天的時間,使用C語言實現了這一模塊,其中,內核空間的核心代碼約2300行,用戶空間管理工具的代碼總行數約為700行。下為系統的鳥瞰:
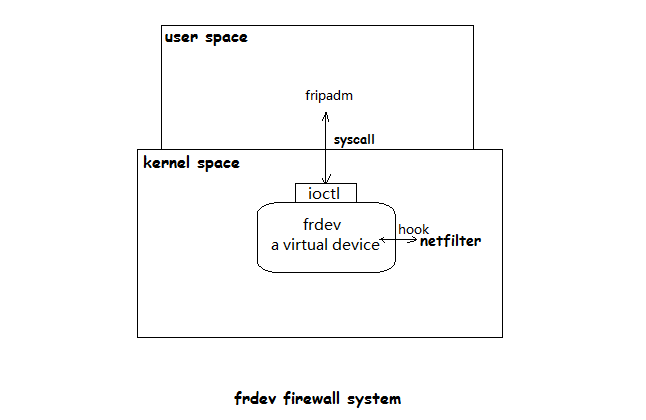
下面是內核態的主要數據結構與其對應的操作函數:


為什么使用雙哈希表緩沖?
請考慮如下場景:
情況1:來自應用層的DDoS攻擊常常是瞬間涌入大量非法ip請求,例如數萬個非法ip,所以,對于防火墻黑白名單功能的要求至少有如下:能在很短的時間內更新大量數據項,且不能造成系統服務停頓。
分析:如果只使用一個全局的哈希表,當在短時間內進行大量的數據項增刪時,例如,成千上萬個,此時,即使采用多把讀寫鎖分割哈希表的策略,對共享資源的競爭也依然將嚴重影響系統響應速度,嚴重時系統可能會停頓或者更糟,對于生產環境中的高負載服務器,這是無法容忍的。
解決:以空間換時間
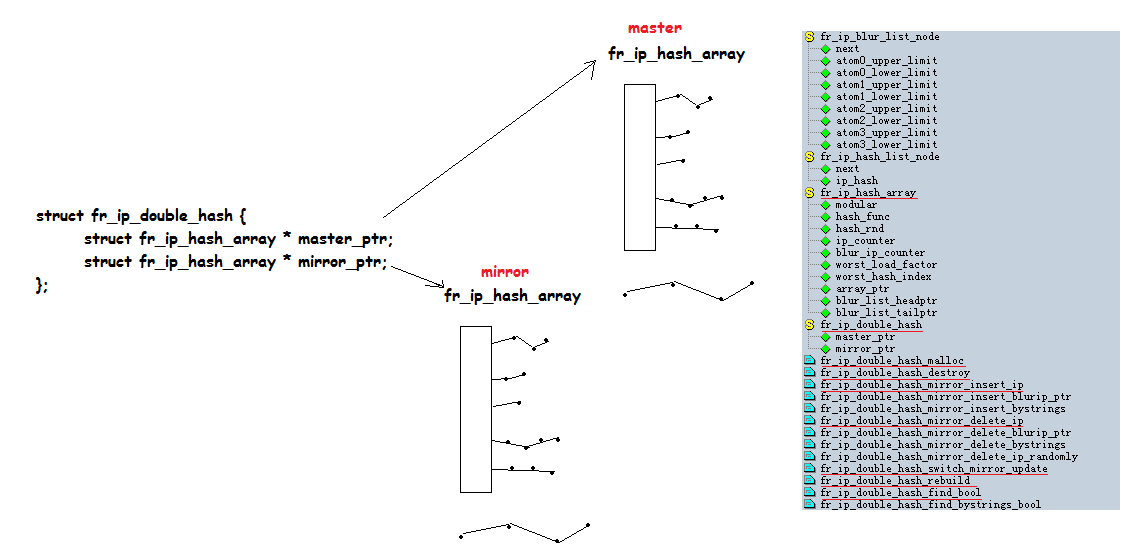
采用雙哈希表緩沖的策略,將系統共享資源的競爭熱點壓縮至兩個hash表指針主備切換的極短時間內,此方法能顯著降低系統在大量數據項更新時共享資源的競爭。
系統查詢將會直接訪問master指向的fr_ip_hash_array,而用戶的更新操作將直接針對mirror所指向的另一個fr_ip_hash_array實例,直到switch_mirror_update操作的執行,master將被瞬間“更新”。這是其主要的工作特點。
對于SMP與多隊列網卡的系統,可采用如下策略:多數cpu核心專門負責處理內核的softirq任務,剩下的少數cpu負責進行雙哈希表的更新、切換與重建等操作。這樣可提高系統對攻擊的快速防御響應。
但此方案將使得系統需要維護兩個互為鏡像的哈希表,這將加重系統內存的讀寫負擔。
具體實現細節如下:

掛到協議棧上的鉤子函數:
在模塊初始化函數fr_ip_dev_init的最后,即當兩個雙哈希表實例(分別用作黑名單與白名單)初始化成功、fedev設備注冊成功之后,其將會執行nf_register_hook,將指定的鉤子函數fr_nf_hook_sample掛到NF_INET_PRE_ROUTING之上。
fr_nf_hook_sample的主要處理代碼如下:
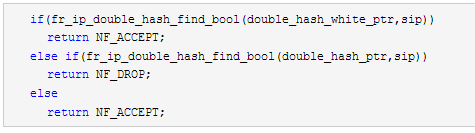
其中,double_hash_white_ptr指向白名單fr_ip_double_hash實例,double_hash_ptr則指向黑名單fr_ip_double_hash實例,由于支持模糊ip匹配,故,上述代碼使得對源ip過濾的“通”、“堵”策略皆可使用。
內核空間frdev的ioctl處理函數:
目前,ioctl支持來自用戶空間的如下操作:

上述各功能的具體實現請閱讀frdev源碼中的fr_ip_dev_ioctl_routine函數。
用戶空間管理工具:fripadm
第一步,實現fripadm_black_in_exe與fripadm_white_in_exe,是分別管理黑白名單的工具,不過,較為簡陋,第二步,使用shell腳本對其進行二次封裝得到fripadm_black_in.sh與fripadm_white_in.sh這兩個較用戶友好的工具。
fripadm為用戶空間的C語言開發者們提供了如下API:
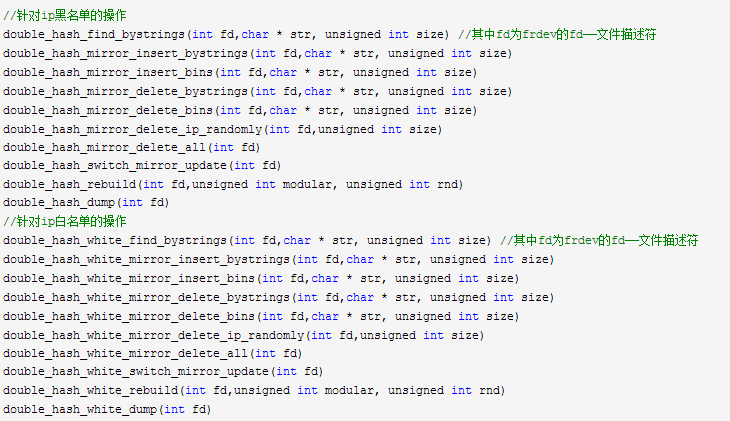
fripadm_black_in_exe、fripadm_white_in_exe、fripadm_black_in.sh與 fripadm_white_in.sh的具體實現請參看frdev源碼。
按照README所述的過程,編譯、安裝完畢frdev設備后,便可進行如下測試:
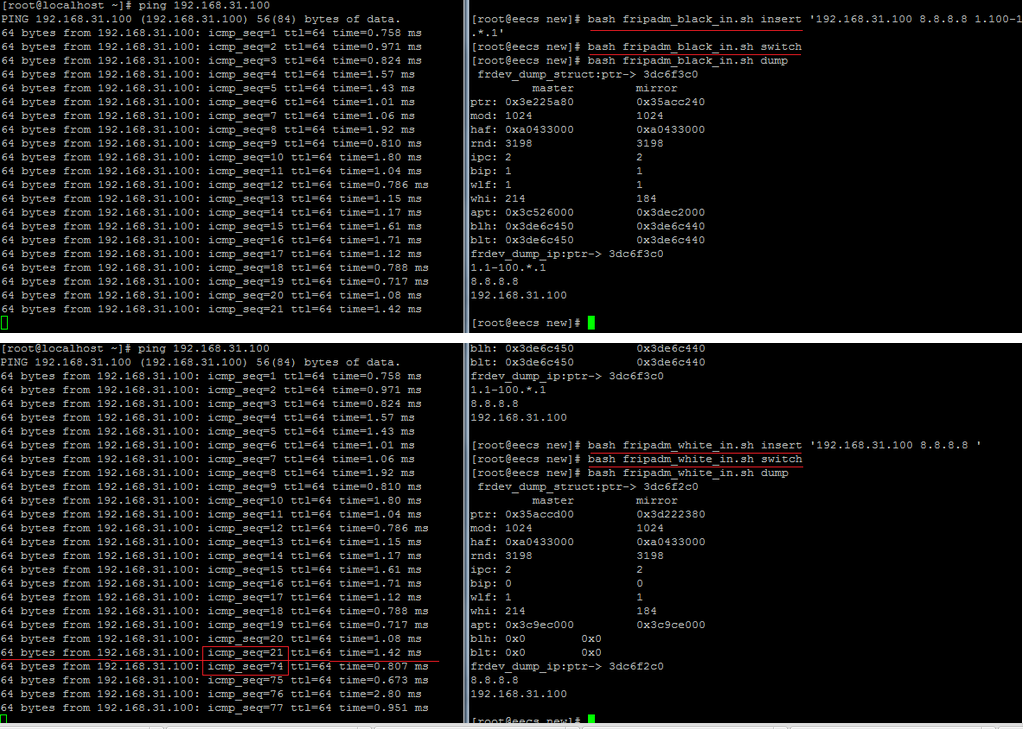
原本被black所DROP的數據包,在更新了white的ip條目后,被white所ACCEPT,上圖紅線標出了數據包被截斷的icmp_seq的區間。
關于frdev的陳述到此為止。
最近筆者在閱讀《白帽子講Web安全》這本書時,發現了雅虎公司用于防護應用層DDoS攻擊的系統Yahoo Detecting System Abuse,yahoo為此系統申請了專利保護。下面是關于這個系統的描述:
A system continually monitors service requests and detects service abuses.
First, a screening list is created to identify potential abuse events. A screening list includes event IDs and associated count values. A pointer cyclically selects entries in the table,advancing as events are received.
An incoming event ID is compared with the event IDs in the table. If the incoming event ID matches an event ID in the Screening list,the associated count is incremented. Otherwise, the count of a selected table entry is decremented. If the count value of the selected entry falls to Zero, it is replaced With the incoming event.
Event IDs can be based on properties of service users,such as user identifications, or of service request contents,such as a search term or message content. The screening list is analyzed to determine whether actual abuse is occurring.
大概思路如下:
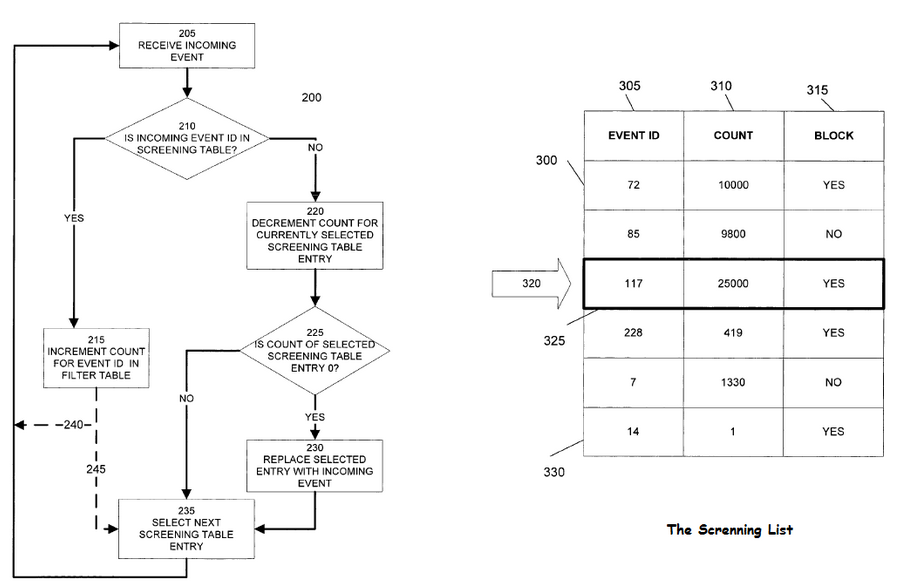
此系統通過維護一個篩選表來得到用戶的請求頻率,以判斷其是否存在service abuse,然采取相關措施,例如BLOCK。
這種防御思想,與我們之前所提出的防御狀態機有著異曲同工之妙。筆者認為這是必然的。
前面的文章已經提過,DDoS攻擊存在的主要原因之一是網絡服務的開放性,我們不可能從下層來解決這樣的問題(因為服務的可用性是第一要求),只能從上層分析解決.
而應用層已經處于協議棧的最高層,所以,要防御應用層DDoS攻擊,只能從應用層以上來尋找解法,故,在這種情況下,除了借助數據統計分析,難道還會有更好的方法么?
原文鏈接:DDoS攻防戰 (一) : 概述
DDoS攻防戰 (二) :CC攻擊工具實現與防御理論
DDoS攻防戰(三):ip黑白名單防火墻frdev的原理與實現

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


