
【編者按】傳感器已經大量部署于實際生產中,涉及航空、電力、醫(yī)療、教育各個行業(yè)的傳感器形成大規(guī)模的工業(yè)物聯(lián)網,各式各樣的傳感器產生了大量的數據,如何去分析這些數據,作者用Raspberry Pi和四個Tinkerforge傳感器DIY了一個辦公室“物聯(lián)網”,模擬了現實生產中傳感器應用,為我們帶來了一些有益的借鑒,下面是作者的精彩分析。
以下為譯文:
當前的一個客戶項目和一般工業(yè)大數據項目的有趣性質(數據產生于傳感器)給了我啟發(fā),我決定自己動手處理傳感器數據,我想通過這個小實驗,了解具體如何處理、存儲和分析這些數據,以及在這一過程中會遇到哪些挑戰(zhàn)?
為了獲取傳感器數據,我們決定把傳感器安裝到我們的辦公室里,生成我們自己的傳感器數據,我們發(fā)現Tinkerforge的bricks和bricklets系統(tǒng)非常友好,易于上手,于是我們選擇采用Tinkerforge系統(tǒng)。
我們得到了以下四個傳感器bricklet:
四個bricklet都連接到主bricklet上,然后將主bricklet連接到Raspberry Pi。
我們把溫度傳感器放在辦公室的中央,將運動探測器安裝在廚房和浴室之間的走廊里,把聲音強度傳感器放在廚房門邊,而觸摸傳感器則放在咖啡機、冰箱門和廁所的門把上。
雖然這樣的設備很難跟實際生產中的情形相比(而且為了獲取足夠多的數據,你需要等很長時間),在這次小小的實驗中,我們還是很快遇到了那些現實傳感器應用過程中的一些關鍵問題。
我們選擇了MongoDB作為存儲解決方案,主要是因為我們的那個客戶項目也使用了MongoDB。
四個傳感器產生的數據可以分為兩類:溫度和聲音強度傳感器輸出連續(xù)的數據流,運動探測器和多點觸摸傳感器往往是由非固定頻率的事件觸發(fā)。
這就形成了MongoDB中兩種不同的文檔模式。對于第一類(流),我們使用MongoDB推薦的模式,實際上也是這種情況下的最佳實踐,即“時間序列模式”(見 http://blog.mongodb.org/post/65517193370/schema-design-for-time-series-data-in-mongodb),由一個內部的嵌套文檔集合組成。嵌套的層數和每個級別子文檔的數量取決于數據的時間粒度。在我們的實驗中,Tinkerforge傳感器的最高時間分辨率為100ms,產生了下面的文檔結構:

MongoDB中文檔是預先分配的,預先對所有的字段進行初始化,保證初始值大于傳感器的數據范圍,這樣做是為了避免由于MongoDB數據庫中文檔持續(xù)增多造成的麻煩。
第二個類型的數據(事件驅動/觸發(fā))以類“bucket”文檔模式存儲。針對每個傳感器的類型,需要預先為值分配固定數量的條目(一bucket分配100個)。當事件發(fā)生時,將其寫入這些文件中,每個事件對應100個條目組的一個子文檔,子文檔貫穿著事件的始終。當記錄/事件第一次被寫入到文檔中時,全部文件獲取與開始日期對應的時間戳。每次寫入到數據庫時,應用程序都會檢查當前記錄是否已經寫入到當前文檔,如果寫入已經完成,它會設置文檔的結束日期/時間并啟動引導到下一文檔的寫入。

這兩個文檔模式表示權衡的邊界情況,在傳感器數據中比較常見。
MongoDB推薦的“時間序列”模式很適合高效寫入,而且兼具良好、一致性架構的優(yōu)勢:每個文檔都對應著一個時間單位(在我們的實驗中,時間單位為一個小時),這使得管理和檢索數據非常方便。此外,還可以很容易從當前的時間推斷出要寫入的“當前”文檔,所以應用程序不需要一直對文檔進行追蹤。
嵌套結構實現了對不同粒度級數據的整合――雖然應用中這些整合不得不手動執(zhí)行。由于這樣一個事實,在該文檔模式中,“分鐘”、“秒”和“毫秒”不再有單一的鍵,相反,每一分鐘、 每一秒、每一毫秒都有各自的鍵。
一旦數據變得稀疏、不連續(xù),這個模式就會出現問題。實驗中,這些數據顯然是由運動探測器和多點觸摸傳感器產生:由于事件是隨機發(fā)生的,所以數據也沒有固定的頻率。對于時間序列文檔模式,這就意味著文檔的某些字段永遠用不到,這顯然是對磁盤空間的一種浪費。
如果傳感器數據開始時不是通過事件驅動的話,也會產生稀疏數據。換句話說,許多傳感器,雖然它們以一個固定的頻率測量數據,但是只會自動輸出相對于上一次測量改變的值,這個問題已經被解決了,如果你想要堅持時間序列文檔模式,就需要經常檢查是否有值被傳感器省去,以傳感器發(fā)出的最新值更新數據庫。當然,這有可能會在數據庫中引入大量的冗余。
Bucket模式中用實際已記錄的數據填充文檔,避免了這一問題,但它也有自身的缺點:
Tinkerforge傳感器帶有多語言版本的API,我們決定使用Python,在連接傳感器的Raspberry Pi上運行腳本,數據則寫入到MongoSoup托管的MongoDB實例中,MongoSoup是我們的MongoDB即服務解決方案。通過API注冊例如聲音強度和溫度bricklet,你需要執(zhí)行下列操作:
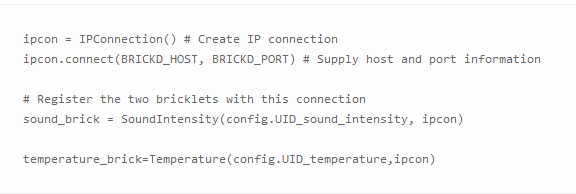
Tinkerforge API支持通過回調函數從傳感器中自動地讀取數據。若要使用此功能,你需要注冊你想要通過bricklet觸發(fā)的功能:
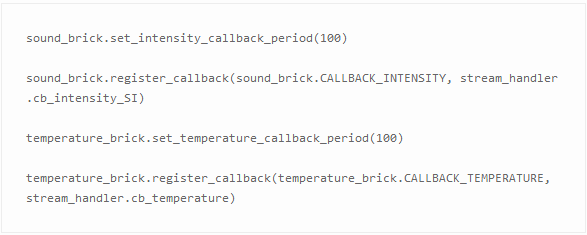
它將以每100ms的速度自動查詢傳感器的新數據并分別調用stream_handler.cb_intensity_SI和stream_handler.cb_temperature函數。
為了節(jié)省網絡帶寬,只在上一次傳感器的測量值發(fā)生改變時,你提供的功能才會被觸發(fā)――也產生了上文討論的稀疏數據。
可以通過直接自定義代碼的方式,以一個固定的頻率查詢傳感器來避免這種現象。但是,就如上文所說的那樣,這會導致數據庫中充滿了冗余數據。此外,它增加了從傳感器到應用程序的網絡開銷。
最后,其中一個將必須決定哪種模式更適合用例。關于數據模式,MongoDB提供了大量元數據模式,你的選擇應完全由用例(比如你最有可能遇到的讀/寫模式)來決定。
一個好方法是在決定一個文檔模型之前,問以下幾個問題:
在我們的實驗中,最初的假設是溫度數據和聲音強度數據會有很大變化,我們需要將它們存儲在“時間序列”數據模式中,而運動探測器和觸摸傳感器數據適合用bucket模式,實際上我們也是這么做的。
在完成安裝并執(zhí)行處理傳感器數據的Python腳本后,我們開始收集數據。
我們使用matplotlib和Flask web服務器框架,搭建起一個小型的web服務,直觀顯示最近收集的數據以用于檢查,并將該web服務部署到Heroku。
我們生成三個plot,第一個隨著時間變化分別顯示觸摸傳感器和運動探測器的事件,其他兩個顯示隨著時間的推移聲音強度和溫度水平,plot中的每個數據點平均一秒鐘計算一次。
一眼就能看出辦公室中人員活動產生的不同傳感器數據之間存在明顯相關性。
你可以確定選擇使用bucket模型是正確的,因為經常會有在長達20 分鐘的時間里,傳感器沒有記錄下任何東西。
看一下溫度數據,雖然它會有波動,但很明顯這種波動保持在1攝氏度的范圍內。如果用例是監(jiān)測全球白天溫度的變化,那很可能需要在時間上采用粗粒度數據寫入或者切換到bucket模式。
聲音強度數據表現為:長時間的安靜(測量值很小)之后大聲事件突然、短時間爆發(fā)。這樣短時間的數據肯定不容許被遺漏,所以上述的粗粒度辦法行不通,不過可以考慮切換到bucket模型,僅向數據庫中寫入變化的數據測量值。
原文鏈接:Processing and analysing sensor data
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創(chuàng),少部分收集于互聯(lián)網供大家一起學習,原版權很多不明,如有侵權請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


