
關(guān)于進程和線程,大家總是說的1句話是“進程是操作系統(tǒng)分配資源的最小單元,線程是操作系統(tǒng)調(diào)度的最小單元”。這句話理論上沒問題,我們來看看甚么是所謂的“資源”呢。
甚么是計算機資源
經(jīng)典的馮諾依曼結(jié)構(gòu)把計算機系統(tǒng)抽象成 CPU + 存儲器 + IO,那末計算機資源不過就兩種:
1. 計算資源
2. 存儲資源
CPU是計算單元,單純從CPU的角度來講它是1個黑盒,它只對輸入的指令和數(shù)據(jù)進行計算,然后輸出結(jié)果,它不負責管理計算哪些”指令和數(shù)據(jù)“。 換句話說CPU只提供了計算能力,但是不負責分配計算資源。
計算資源是操作系統(tǒng)來分配的,也就是常說的操作系統(tǒng)的調(diào)度模塊,由操作系統(tǒng)依照1定的規(guī)則來分配甚么時候由誰來取得CPU的計算資源,比如分時間片
存儲資源就是內(nèi)存,磁盤這些存儲裝備的資源。在這篇計算機底層知識拾遺(1)理解虛擬內(nèi)存機制 我們說了操作系統(tǒng)使用了虛擬內(nèi)存機制來管理存儲器,從緩存原理的角度來講,把內(nèi)存作為磁盤的緩存。進程是面向磁盤的,為何這么說呢,進程表示1個運行的程序,程序的代碼段,數(shù)據(jù)段這些都是寄存在磁盤中的,在運行時加載到內(nèi)存中。所以虛擬內(nèi)存面向的是磁盤,虛擬頁是對磁盤文件的分配,然后被緩存到物理內(nèi)存的物理頁中。
所以存儲資源是操作系統(tǒng)由虛擬內(nèi)存機制來管理和分配的。進程應(yīng)當是操作系統(tǒng)分配存儲資源的最小單元。
再來看看線程,理論上說Linux內(nèi)核是沒有線程這個概念的,只有內(nèi)核調(diào)度實體(Kernal Scheduling Entry, KSE)這個概念。Linux的線程本質(zhì)上是1種輕量級的進程,是通過clone系統(tǒng)調(diào)用來創(chuàng)建的。何謂“輕量級”會在后面細說。進程是1種KSE,線程也是1種KSE。所以“線程是操作系統(tǒng)調(diào)度的最小單元”這句話沒問題。
甚么是進程
進程是對計算機的1種抽象,
1. 進程表示1個邏輯控制流,就是1種計算進程,它造成1個假象,好像這個進程1直在獨占CPU資源
2. 進程具有1個獨立的虛擬內(nèi)存地址空間,它造成1個假象,好像這個進程1致在獨占存儲器資源
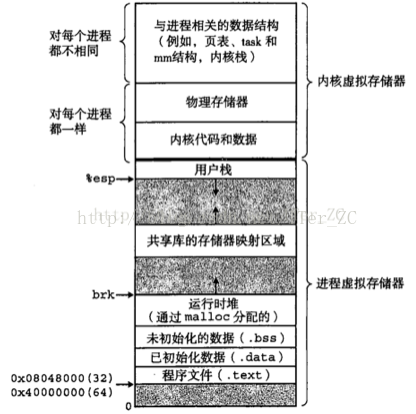
這張圖是進程的虛擬內(nèi)存地址空間的分配模型圖,可以看到進程的虛擬內(nèi)存地址空間分為用戶空間和內(nèi)核空間。用戶空間從低端地址往高端地址發(fā)展,內(nèi)核空間從高端地址往低端地址發(fā)展。用戶空間寄存著這個進程的代碼段和數(shù)據(jù)段,和運行時的堆和用戶棧。堆是從低端地址往高端地址發(fā)展,棧是從高端地址往低端地址發(fā)展。
內(nèi)核空間寄存著內(nèi)核的代碼和數(shù)據(jù),和內(nèi)核為這個進程創(chuàng)建的相干數(shù)據(jù)結(jié)構(gòu),比如頁表數(shù)據(jù)結(jié)構(gòu),task數(shù)據(jù)結(jié)構(gòu),area區(qū)域數(shù)據(jù)結(jié)構(gòu)等等。
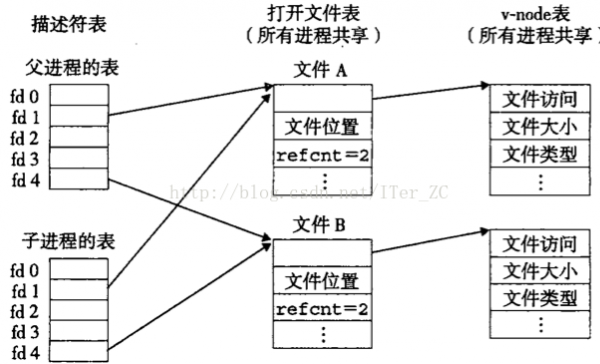
從文件IO的角度來講,Linux把1切IO都抽象成了文件,比如普通文件IO,網(wǎng)絡(luò)IO,統(tǒng)統(tǒng)都是文件,利用open系統(tǒng)調(diào)用返回1個整數(shù)作為文件描寫符file descriptor,進程可以利用file descriptor作為參數(shù)在任何系統(tǒng)調(diào)用中表示那個打開的文件。內(nèi)核為進程保護了1個文件描寫符表來保持進程所有取得的file descriptor。
每調(diào)用1次open系統(tǒng)調(diào)用內(nèi)核會創(chuàng)建1個打開文件open file的數(shù)據(jù)結(jié)構(gòu)來表示這個打開的文件,記錄了該文件目前讀取的位置等信息。打開文件又唯1了1個指針指向文件系統(tǒng)中該文件的inode結(jié)構(gòu)。inode記錄了該文件的文件名,路徑,訪問權(quán)限等元數(shù)據(jù)。
操作操作系統(tǒng)用了3個數(shù)據(jù)結(jié)構(gòu)來為每一個進程管理它打開的文件資源
fork系統(tǒng)調(diào)用
操作系統(tǒng)利用fork系統(tǒng)調(diào)用來創(chuàng)建1個子進程。fork所創(chuàng)建的子進程會復(fù)制父進程的虛擬地址空間。
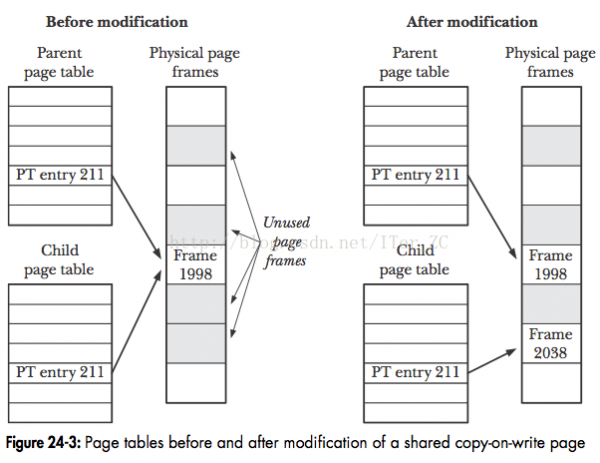
要理解“復(fù)制”和“同享”的區(qū)分,復(fù)制的意思是會真正在物理內(nèi)存復(fù)制1分內(nèi)容,會真正消耗新的物理內(nèi)存。同享的意思是使用指針指向同1個地址,不會真實的消耗物理內(nèi)存。理解這兩個概念的區(qū)分很重要,這是進程和線程的根本區(qū)分之1。
那末有人問了如果我父進程占了1G的物理內(nèi)存,那末fork會再使用1G的物理內(nèi)存來復(fù)制嗎,相當于1下用了2G的物理內(nèi)存?
答案是初期的操作系統(tǒng)的確是這么干的,但是這樣性能也太差了,所以現(xiàn)代操作系統(tǒng)使用了 寫時復(fù)制Copy on write的方式來優(yōu)化fork的性能,fork剛創(chuàng)建的子進程采取了同享的方式,只用指針指向了父進程的物理資源。當子進程真正要對某些物理資源寫操作時,才會真實的復(fù)制1塊物理資源來供子進程使用。這樣就極大的優(yōu)化了fork的性能,并且從邏輯來講子進程的確是具有了獨立的虛擬內(nèi)存空間。
fork不只是復(fù)制了頁表結(jié)構(gòu),還復(fù)制了父進程的文件描寫符表,信號控制表,進程信息,寄存器資源等等。它是1個較為深入的復(fù)制。
從邏輯控制流的角度來講,fork創(chuàng)建的子進程開始履行的位置是fork函數(shù)返回的位置。這點和線程是不1樣的,我們知道Java中的Thread需要寫run方法,線程開始后會從run方法開始履行。
既然我們知道了內(nèi)核為進程保護了這么多資源,那末當內(nèi)存進行進程調(diào)度時進行的進程上下文切換就容易理解了,1個進程運行要依賴這么些資源,那末進程上下文切換就要把這些資源都保存起來寫回到內(nèi)存中,等下次這個進程被調(diào)度時再把這些資源再加載到寄存器和高速緩存硬件。
進程上下文切換保存的內(nèi)容有:
頁表 -- 對應(yīng)虛擬內(nèi)存資源
文件描寫符表/打開文件表 -- 對應(yīng)打開的文件資源
寄存器 -- 對應(yīng)運行時數(shù)據(jù)
信號控制信息/進程運行信息
進程間通訊
虛擬內(nèi)存機制為進程管理存儲資源帶來了種種好處,但是它也給進程帶來了1些小麻煩,我們知道每一個進程具有獨立的虛擬內(nèi)存地址空間,看到1樣的虛擬內(nèi)地址空間視圖,所以對不同的進程來講,1個相同的虛擬地址意味著不同的物理地址。我們知道CPU履行指令時采取了虛擬地址,對應(yīng)1個特定的變量來講,它對應(yīng)著1個特定的虛擬地址。這樣帶來的問題就是兩個進程不能通過簡單的同享變量的方式來進行進程間通訊,也就是說進程不能通過直接同享內(nèi)存的方式來進行進程間通訊,只能采取信號,管道等方式來進行進程間通訊。這樣的效力肯定比直接同享內(nèi)存的方式差
甚么是線程
上面說了1堆內(nèi)核為進程分配了哪些資源,我們知道進程管理了1堆資源,并且每一個進程還具有獨立的虛擬內(nèi)存地址空間,會真正地具有獨立與父進程以外的物理內(nèi)存。并且由于進程具有獨立的內(nèi)存地址空間,致使了進程之間沒法利用直接的內(nèi)存映照進行進程間通訊。
并發(fā)的本質(zhì)是在時間上堆疊的多個邏輯流,也就是說同時運行的多個邏輯流。并發(fā)編程要解決的1個很重要的問題就是對資源的并發(fā)訪問的問題,也就是同享資源的問題。而兩個進程恰恰很難在邏輯上表示同享資源。
線程解決的最大問題就是它可以很簡單地表示同享資源的問題,這里說的資源指的是存儲器資源,資源最后都會加載到物理內(nèi)存,1個進程的所有線程都是同享這個進程的同1個虛擬地址空間的,也就是說從線程的角度來講,它們看到的物理資源都是1樣的,這樣就能夠通過同享變量的方式來表示同享資源,也就是直接同享內(nèi)存的方式解決了線程通訊的問題。而線程也表示1個獨立的邏輯流,這樣就完善解決了進程的1個大困難。
從存儲資源的角度理解了線程以后,就不難理解計算資源的分配了。從計算資源的角度來講,對內(nèi)核而言,進程和線程沒有甚么區(qū)分,所之內(nèi)核用內(nèi)核調(diào)度實體(KSE)來表示1個調(diào)度的單元。
clone系統(tǒng)調(diào)用
在Linux系統(tǒng)中,線程是使用clone系統(tǒng)調(diào)用,clone是1個輕量級的fork,它提供了1系列的參數(shù)來表示線程可以同享父類的哪些資源,比如頁表,打開文件表等等。我們上面說過了同享和復(fù)制的區(qū)分,同享只是簡單地用指針指向同1個物理地址,不會在父進程以外開辟新的物理內(nèi)存。
clone系統(tǒng)調(diào)用可以指定創(chuàng)建的線程開始履行代碼位置,也就是Java中的Thread類的run方法。
Linux內(nèi)核只提供了clone這個系統(tǒng)調(diào)用來創(chuàng)建類似線程的輕量級進程的概念。C語言利用了Pthreads庫來真正創(chuàng)建了線程這個數(shù)據(jù)結(jié)構(gòu)。Linux采取了1:1的模型,即C語言的Pthreads庫創(chuàng)建的線程實體1:1對應(yīng)著內(nèi)核創(chuàng)建的1個KSE。Pthreads運行在用戶空間,KSE運行在內(nèi)核空間。
既然線程同享了進程的資源,那末線程的上下文切換就好理解了。對操作系統(tǒng)來講,它看到要被調(diào)度進來的線程和剛運行的線程是同1個進程的,那末線程的上下文切換只需要保存線程的1些運行時的數(shù)據(jù),比如
線程的id
寄存器中的值
棧數(shù)據(jù)
而不需要像進程上下文切換那樣要保存頁表,文件描寫符表,信號控制數(shù)據(jù)和進程信息等數(shù)據(jù)。頁表是1個很重的資源,我們之前說過,如果采取1級頁表的結(jié)構(gòu),那末32位機器的頁表要到達4MB的物理空間。 所以線程上下文切換是很輕量級的。
進程采取父子結(jié)構(gòu),init進程是最頂真?zhèn)€父進程,其他進程都是從init進程派生出來的。這樣就很容易理解進程是如何同享內(nèi)核的代碼和數(shù)據(jù)的了。
而線程采取對等結(jié)構(gòu),即線程沒有父子的概念,所有線程都屬于同1個線程組,線程組的組號等于第1個線程的線程號。
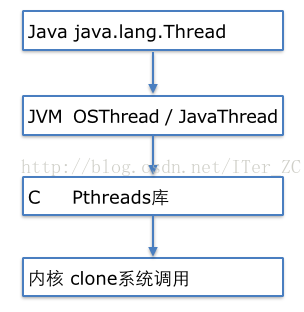
我們來看看Java的線程究竟是如何實現(xiàn)的。Java語言層面提供了java.lang.Thread這個類來表示Java語言層面的線程,并提供了run方法表示線程運行的邏輯控制流。
我們知道JVM是C++/C寫的,JVM本身利用了Pthreads庫來創(chuàng)建操作系統(tǒng)的線程。JVM還要支持Java語言創(chuàng)建的線程的概念。
聊聊JVM(5)從JVM角度理解線程 這篇已說了從JVM的角度如何理解線程。 JVM提供了JavaThread類來對應(yīng)Java語言的Thread,即Java語言中創(chuàng)建1個java.lang.Thread對象,JVM會相應(yīng)的在JVM中創(chuàng)建1個JavaThread對象。同時JVM還創(chuàng)建了1個OSThread類來對利用Pthreads創(chuàng)建的底層操作系統(tǒng)的線程對象。
構(gòu)建并發(fā)程序可以基于進程也能夠線程,
比如Nginx就是基于進程構(gòu)建并發(fā)程序的。而Java天生只支持基于線程的方式來構(gòu)建并發(fā)程序。
最后再總結(jié)1下 進程VS 線程
參考資料
《深入理解計算機系統(tǒng)》
《Linux系統(tǒng)編程手冊》

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


