
標簽(空格分隔): kafka
Kafka中的Message是以topic為基本單位組織的,不同的topic之間是相互獨立的。每一個topic又可以分成幾個不同的partition(每一個topic有幾個partition是在創建topic時指定的),每一個partition存儲1部份Message。借用官方的1張圖,可以直觀地看到topic和partition的關系。
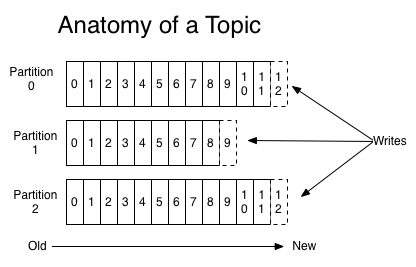
partition是以文件的情勢存儲在文件系統中,比如,創建了1個名為page_visits的topic,其有5個partition,那末在Kafka的數據目錄中(由配置文件中的log.dirs指定的)中就有這樣5個目錄: page_visits-0, page_visits⑴,page_visits⑵,page_visits⑶,page_visits⑷,其命名規則為<topic_name>-<partition_id>,里面存儲的分別就是這5個partition的數據。
接下來,本文將分析partition目錄中的文件的存儲格式和相干的代碼所在的位置。
Partition中的每條Message由offset來表示它在這個partition中的偏移量,這個offset不是該Message在partition數據文件中的實際存儲位置,而是邏輯上1個值,它唯1肯定了partition中的1條Message。因此,可以認為offset是partition中Message的id。partition中的每條Message包括了以下3個屬性:
其中offset為long型,MessageSize為int32,表示data有多大,data為message的具體內容。它的格式和Kafka通訊協議中介紹的MessageSet格式是1致。
Partition的數據文件則包括了若干條上述格式的Message,按offset由小到大排列在1起。它的實現類為FileMessageSet,類圖以下:
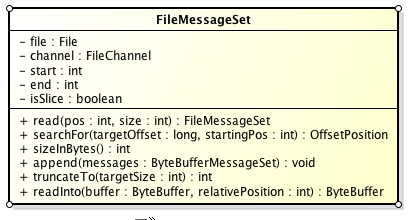
它的主要方法以下:
我們來思考1下,如果1個partition只有1個數據文件會怎樣樣?
那Kafka是如何解決查找效力的的問題呢?有兩大寶貝:1) 分段 2) 索引。
Kafka解決查詢效力的手段之1是將數據文件分段,比如有100條Message,它們的offset是從0到99。假定將數據文件分成5段,第1段為0⑴9,第2段為20⑶9,以此類推,每段放在1個單獨的數據文件里面,數據文件以該段中最小的offset命名。這樣在查找指定offset的Message的時候,用2分查找就能夠定位到該Message在哪一個段中。
數據文件分段使得可以在1個較小的數據文件中查找對應offset的Message了,但是這仍然需要順序掃描才能找到對應offset的Message。為了進1步提高查找的效力,Kafka為每一個分段后的數據文件建立了索引文件,文件名與數據文件的名字是1樣的,只是文件擴大名為.index。
索引文件中包括若干個索引條目,每一個條目表示數據文件中1條Message的索引。索引包括兩個部份(均為4個字節的數字),分別為相對offset和position。
index文件中并沒有為數據文件中的每條Message建立索引,而是采取了稀疏存儲的方式,每隔1定字節的數據建立1條索引。這樣避免了索引文件占用過量的空間,從而可以將索引文件保存在內存中。但缺點是沒有建立索引的Message也不能1次定位到其在數據文件的位置,從而需要做1次順序掃描,但是這次順序掃描的范圍就很小了。
在Kafka中,索引文件的實現類為OffsetIndex,它的類圖以下:

主要的方法有:
我們以幾張圖來總結1下Message是如何在Kafka中存儲的,和如何查找指定offset的Message的。
Message是依照topic來組織,每一個topic可以分成多個的partition,比如:有5個partition的名為為page_visits的topic的目錄結構為:

partition是分段的,每一個段叫LogSegment,包括了1個數據文件和1個索引文件,下圖是某個partition目錄下的文件:

可以看到,這個partition有4個LogSegment。
借用博主@lizhitao博客上的1張圖來展現是如何查找Message的。
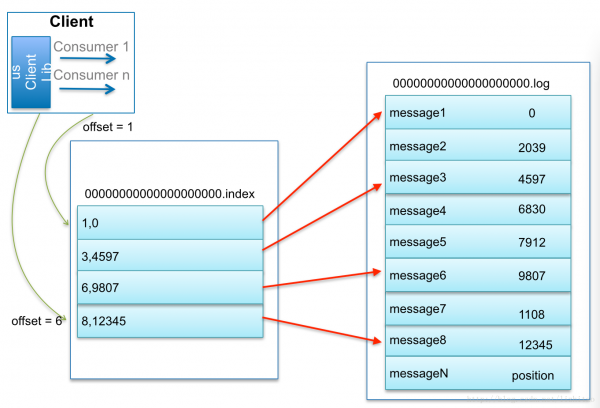
比如:要查找絕對offset為7的Message:
這套機制是建立在offset是有序的。索引文件被映照到內存中,所以查找的速度還是很快的。
1句話,Kafka的Message存儲采取了分區(partition),分段(LogSegment)和稀疏索引這幾個手段來到達了高效性。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


