
《緩沖區溢出分析》這1系列的內容是我為“i年齡”所錄制的同名視頻課程的講稿匯總。每次我都是在寫完課程的文檔后,再根據文檔內容進行課程的講授。而本系列的內容也是從零開始,來給大家由淺入深地進行緩沖區溢出漏洞的講授。全部課程是理論與實踐相結合,每講完幾個基礎理論后,都會配以實際的軟件中的漏洞進行分析,以幫助大家更好地理解漏洞的原理。
漏洞指的是在硬件、軟件、協議的具體實現或系統安全策略上存在的缺點,通常是由程序的編寫者在編寫時的忽視釀成的。漏洞的存在使攻擊者能夠在未經允許的情況下訪問或破壞目標系統,這在無形中給用戶系統的安全帶來了很大的要挾。
1般來講,軟件漏洞其實不影響程序的正常功能,但是如果被攻擊者成功利用,就有可能使得軟件去履行額外的歹意代碼。漏洞發掘和利用是1門非常精深的技術,乃至是1門藝術,這些都是頂級黑客才華得了的活兒。
大多數程序漏洞發掘與內存破壞有關,比如最為常見的緩沖區溢出那樣的漏洞發掘技術。使用這類技術的終究目標是控制目標程序的履行流程,以欺騙程序使其運行1段偷偷植入內存的歹意代碼,這樣黑客就能夠使程序做他想要做的幾近任何事情。
說到溢出,可能在我們的頭腦中首先顯現出來的是水的溢出:
圖1 水的溢出
水杯的大小是固定的,如果杯子沒有裝滿,那末就不會有甚么問題。可是1旦裝滿了,還繼續裝的話,那末這個時候,水就會不斷地溢出。
在計算機內部,輸入數據通常被寄存在1個臨時空間內,這個臨時寄存的空間就被稱為緩沖區,緩沖區的長度事前已被程序或操作系統定義好了。向緩沖區內填充數據,如果數據的長度很長,超過了緩沖區本身的容量,那末數據就會溢出存儲空間,而這些溢出的數據還會覆蓋在合法的數據上,這就是緩沖區和緩沖區溢出的道理。
固然在理想的情況下,程序會檢查每一個數據的長度,并且不允許超過緩沖區的長度大小,但有些程序會假定數據長度總是與所分配的存儲空間相匹配,而不做檢查,從而為緩沖區溢出埋下隱患。
那末我們應當如何利用緩沖區溢出呢?1般情況下,溢出的數據會覆蓋掉相鄰區域的內容。我們可以利用溢出的數據,使計算機履行我們想要的命令。這就是很多漏洞公告上說的:“黑客可以用精心構造的數據……”道理就是這樣。
作為初學者,如果還不熟習這個概念,可先把緩沖區溢出利用理解為允許攻擊者往某個程序變量中放1個比預期長度要長的值,由此以當前運行該程序的用戶的特權履行任意命令。
第1個緩沖區溢出攻擊――Morris蠕蟲,產生在1988年,由羅伯特莫里斯(Robert Morris)制造,它曾造玉成世界6000多臺網絡服務器癱瘓。時至本日,溢出攻擊照舊是安全領域的熱門話題,比如烏云網(WooYun.org)總會有關于緩沖區溢出類漏洞的報告: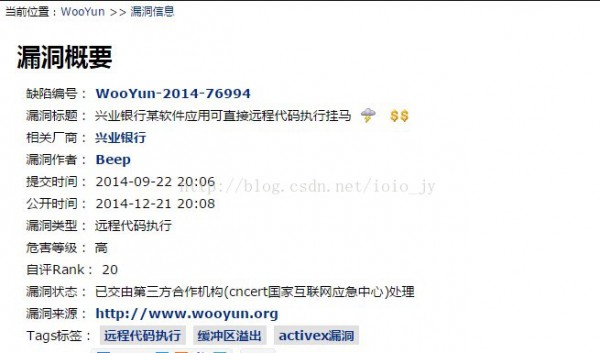
圖2 某軟件的緩沖區漏洞概要
這是關于興業銀行的,提交于2014年9月22日的,關于“緩沖區溢出”的漏洞報告。下面是宜信平臺的溢出報告:
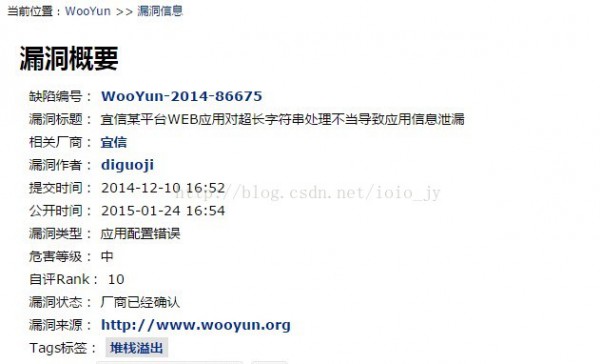
圖3 某平臺的堆棧溢出漏洞概要
可見緩沖區溢出漏洞確切是普遍存在的。
最后再講1下我們這個系列的課程安排,首先會給大家分析基礎的緩沖區溢出漏洞的原理和利用方法,和基礎 ShellCode的編寫方法,隨著課程的不斷深入,我會不斷地完善我們的 ShellCode,并且結合真實的漏洞案例進行分析。以后還會給大家介紹更多種類的緩沖區溢出方法,還有緩沖區溢出漏洞的高級防范措施等。我希望本系列的課程能夠培養大家的安全意識,擴大大家的思惟,使得大家在學習完這1系列的課程以后,都能打下堅實的基礎,令每位朋友都能夠成為安全領域的專家。
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


