
轉載:http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html
1致性哈希算法在1997年由麻省理工學院的Karger等人在解決散布式Cache中提出的,設計目標是為了解決因特網中的熱門(Hot spot)問題,初衷和CARP10分類似。1致性哈希修正了CARP使用的簡單哈希算法帶來的問題,使得DHT可以在P2P環境中真正得到利用。
但現在1致性hash算法在散布式系統中也得到了廣泛利用,研究過memcached緩存數據庫的人都知道,memcached服務器端本身不提供散布式cache的1致性,而是由客戶端來提供,具體在計算1致性hash時采取以下步驟:
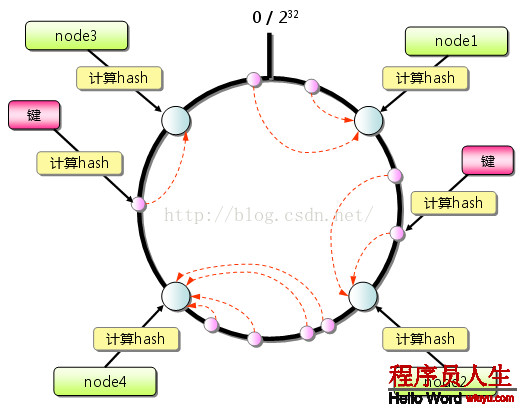
從上圖的狀態中添加1臺memcached服務器。余數散布式算法由于保存鍵的服務器會產生巨大變化而影響緩存的命中率,但Consistent Hashing中,只有在園(continuum)上增加服務器的地點逆時針方向的第1臺服務器上的鍵會遭到影響,以下圖所示:
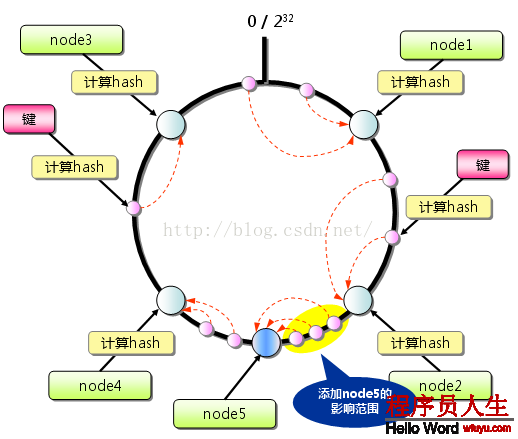
斟酌到散布式系統每一個節點都有可能失效,并且新的節點極可能動態的增加進來,如何保證當系統的節點數目產生變化時依然能夠對外提供良好的服務,這是值得斟酌的,特別實在設計散布式緩存系統時,如果某臺服務器失效,對全部系統來講如果不采取適合的算法來保證1致性,那末緩存于系統中的所有數據都可能會失效(即由于系統節點數目變少,客戶端在要求某1對象時需要重新計算其hash值(通常與系統中的節點數目有關),由于hash值已改變,所以極可能找不到保存該對象的服務器節點),因此1致性hash就顯得相當重要,良好的散布式cahce系統中的1致性hash算法應當滿足以下幾個方面:
平衡性是指哈希的結果能夠盡量散布到所有的緩沖中去,這樣可使得所有的緩沖空間都得到利用。很多哈希算法都能夠滿足這1條件。
單調性是指如果已有1些內容通過哈希分派到了相應的緩沖中,又有新的緩沖區加入到系統中,那末哈希的結果應能夠保證原有已分配的內容可以被映照到新的緩沖區中去,而不會被映照到舊的緩沖集合中的其他緩沖區。簡單的哈希算法常常不能滿足單調性的要求,如最簡單的線性哈希:x = (ax + b) mod (P),在上式中,P表示全部緩沖的大小。不難看出,當緩沖大小產生變化時(從P1到P2),原來所有的哈希結果均會產生變化,從而不滿足單調性的要求。哈希結果的變化意味著當緩沖空間產生變化時,所有的映照關系需要在系統內全部更新。而在P2P系統內,緩沖的變化等價于Peer加入或退出系統,這1情況在P2P系統中會頻繁產生,因此會帶來極大計算和傳輸負荷。單調性就是要求哈希算法能夠應對這類情況。
在散布式環境中,終端有可能看不到所有的緩沖,而是只能看到其中的1部份。當終端希望通過哈希進程將內容映照到緩沖上時,由于不同終端所見的緩沖范圍有可能不同,從而致使哈希的結果不1致,終究的結果是相同的內容被不同的終端映照到不同的緩沖區中。這類情況明顯是應當避免的,由于它致使相同內容被存儲到不同緩沖中去,下降了系統存儲的效力。分散性的定義就是上述情況產生的嚴重程度。好的哈希算法應能夠盡可能避免不1致的情況產生,也就是盡可能下降分散性。
負載問題實際上是從另外一個角度看待分散性問題。既然不同的終端可能將相同的內容映照到不同的緩沖區中,那末對1個特定的緩沖區而言,也可能被不同的用戶映照為不同的內容。與分散性1樣,這類情況也是應當避免的,因此好的哈希算法應能夠盡可能下降緩沖的負荷。
平滑性是指緩存服務器的數目平滑改變和緩存對象的平滑改變是1致的。
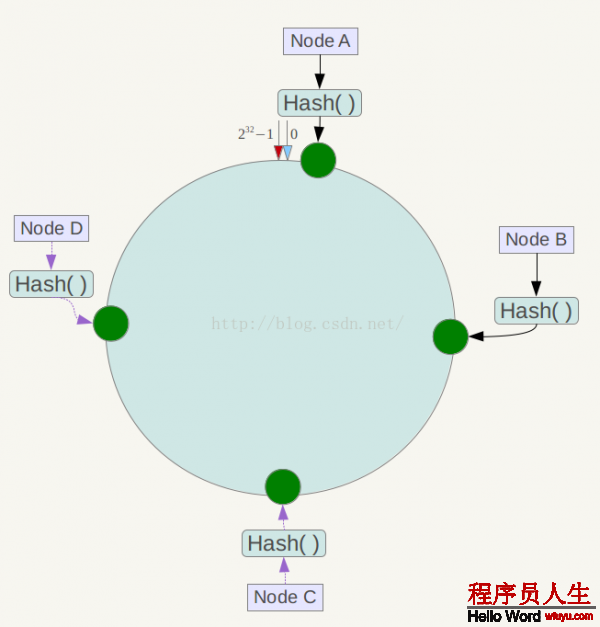
1致性哈希算法(Consistent Hashing)最早在論文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。簡單來講,1致性哈希將全部哈希值空間組織成1個虛擬的圓環,如假定某哈希函數H的值空間為0⑵^32⑴(即哈希值是1個32位無符號整形),全部哈希空間環以下:

全部空間按順時針方向組織。0和232⑴在零點中方向重合。
下1步將各個服務器使用Hash進行1個哈希,具體可以選擇服務器的ip或主機名作為關鍵字進行哈希,這樣每臺機器就可以肯定其在哈希環上的位置,這里假定將上文中4臺服務器使用ip地址哈希后在環空間的位置以下:
接下來使用以下算法定位數據訪問到相應服務器:將數據key使用相同的函數Hash計算出哈希值,并肯定此數據在環上的位置,從此位置沿環順時針“行走”,第1臺遇到的服務器就是其應當定位到的服務器。
例如我們有Object A、Object B、Object C、Object D4個數據對象,經過哈希計算后,在環空間上的位置以下:
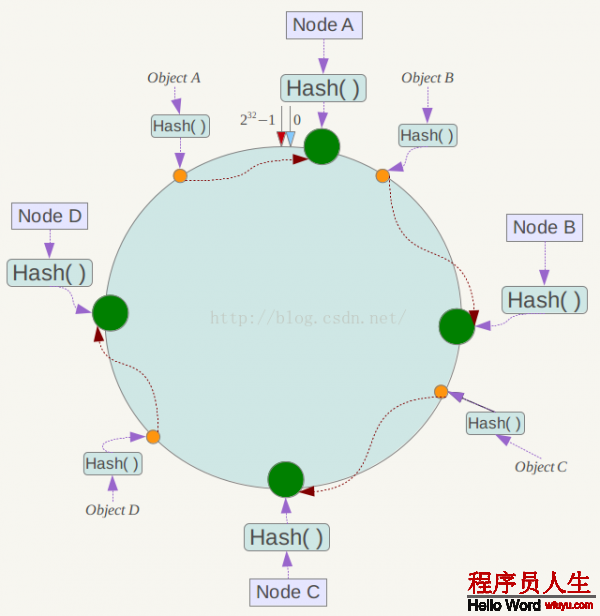
根據1致性哈希算法,數據A會被定為到Node A上,B被定為到Node B上,C被定為到Node C上,D被定為到Node D上。
下面分析1致性哈希算法的容錯性和可擴大性。現假定Node C不幸宕機,可以看到此時對象A、B、D不會遭到影響,只有C對象被重定位到Node D。1般的,在1致性哈希算法中,如果1臺服務器不可用,則受影響的數據僅僅是此服務器到其環空間中前1臺服務器(即沿著逆時針方向行走遇到的第1臺服務器)之間數據,其它不會遭到影響。
下面斟酌另外1種情況,如果在系統中增加1臺服務器Node X,以下圖所示:
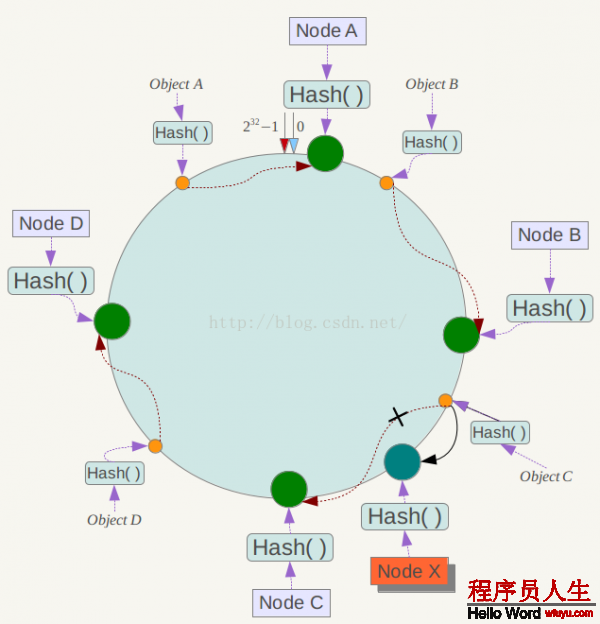
此時對象Object A、B、D不受影響,只有對象C需要重定位到新的Node X 。1般的,在1致性哈希算法中,如果增加1臺服務器,則受影響的數據僅僅是新服務器到其環空間中前1臺服務器(即沿著逆時針方向行走遇到的第1臺服務器)之間數據,其它數據也不會遭到影響。
綜上所述,1致性哈希算法對節點的增減都只需重定位環空間中的1小部份數據,具有較好的容錯性和可擴大性。
另外,1致性哈希算法在服務節點太少時,容易由于節點分部不均勻而造成數據傾斜問題。例如系統中只有兩臺服務器,其環散布以下,
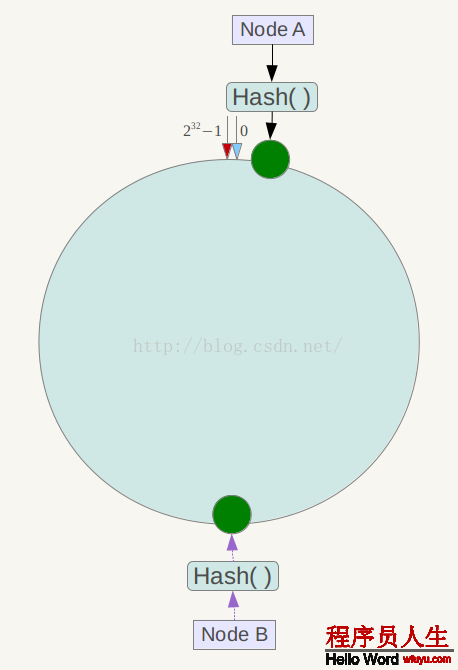
此時必定造成大量數據集中到Node A上,而只有極少許會定位到Node B上。為了解決這類數據傾斜問題,1致性哈希算法引入了虛擬節點機制,即對每個服務節點計算多個哈希,每一個計算結果位置都放置1個此服務節點,稱為虛擬節點。具體做法可以在服務器ip或主機名的后面增加編號來實現。例如上面的情況,可以為每臺服務器計算3個虛擬節點,因而可以分別計算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,因而構成6個虛擬節點:
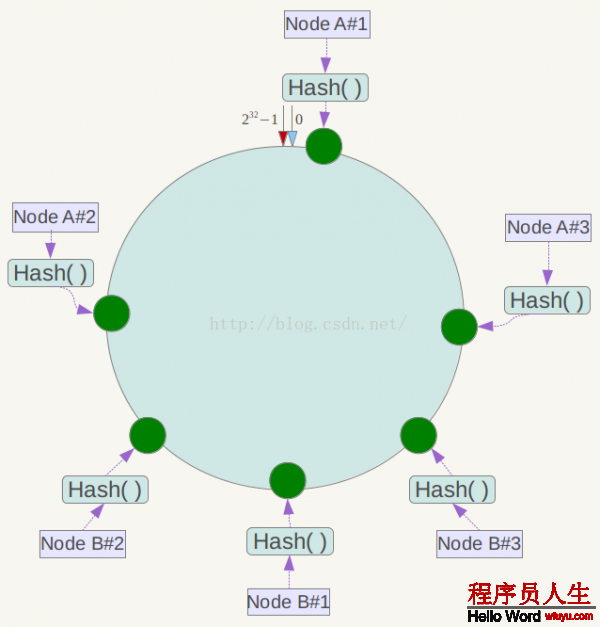
同時數據定位算法不變,只是多了1步虛擬節點到實際節點的映照,例如定位到“Node A#1”、“Node A#2”、“Node A#3”3個虛擬節點的數據均定位到Node A上。這樣就解決了服務節點少時數據傾斜的問題。在實際利用中,通常將虛擬節點數設置為32乃至更大,因此即便很少的服務節點也能做到相對均勻的數據散布。
[1]. D. Darger, E. Lehman, T. Leighton, M. Levine, D. Lewin and R. Panigrahy. Consistent Hashing and Random Trees:Distributed Caching Protocols for Relieving Hot Spots On the World Wide Web. ACM Symposium on Theory of Computing, 1997. 1997:654⑹63.
[2]. 1致性哈希. http://baike.baidu.com/view/1588037.htm
[3]. memcached全面剖析–4. memcached的散布式算法. http://tech.idv2.com/2008/07/24/memcached-004/
[4]. 1致性哈希算法及其在散布式系統中的利用. http://www.codinglabs.org/html/consistent-hashing.html
[5]. Consistent hashing. http://en.wikipedia.org/wiki/Consistent_hashing
[6]. http://www.lexemetech.com/2007/11/consistent-hashing.html

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


