
SQL優化有很多方法,今天來講1說數據庫索引。
舉例說明:
假定有1個圖書Book表,里面有字段id,name, isbn等。如果圖書數量巨大的話,我們通過isbn查詢通常是比較慢的。
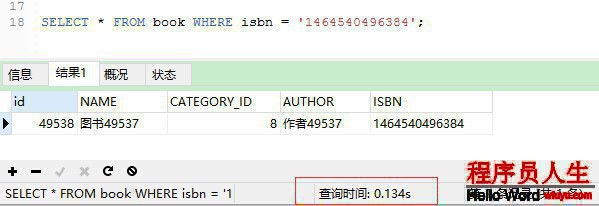
添加索引:
create index index_isbn ON book (isbn);
再次履行查詢:
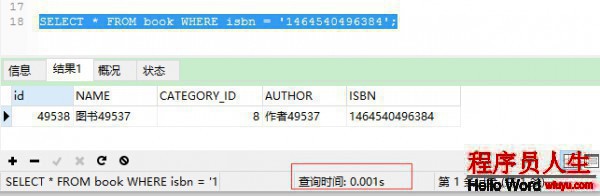
查詢時間從0.134縮短到0.001,效果還是很明顯的。
接下來通過1個故事來講明1下,索引是甚么?
很久之前,在1個古城的的大圖書館中收藏有不計其數本書籍,但書架上的書沒有按任何順序擺放,因此每當有人詢問某本書時,圖書管理員只有挨個尋覓,每次都要花費大量的時間。[這就好比數據表沒有主鍵1樣,搜索表中的數據時,數據庫引擎必須進行全表掃描,效力極為低下。]
更糟的是圖書館的圖書愈來愈多,圖書管理員的工作變得異常痛苦,有1天來了1個聰明的小伙子,他看到圖書管理員的痛苦工作后,想出了1個辦法,他建議將每本書都編上號,然后按編號放到書架上,如果有人指定了圖書編號,那末圖書管理員很快就能夠找到它的位置了。
[給圖書編號就象給表創建主鍵1樣,創建主鍵時,會創建聚集索引樹,表中的所有行會在文件系統上根據主鍵值進行物理排序,當查詢表中任1行時,數據庫首先使用聚集索引樹找到對應的數據頁(就象首先找到書架1樣),然后在數據頁中根據主鍵鍵值找到目標行(就象找到書架上的書1樣)。]
因而圖書管理員開始給圖書編號,然后根據編號將書放到書架上,為此他花了整整1天時間,但最后經過測試,他發現找書的效力大大提高了。[在1個表上只能創建1個聚集索引,就象書只能按1種規則擺放1樣。]
但問題并未完全解決,由于很多人記不住書的編號,只記得書的名字,圖書管理員無賴又只有掃描所有的圖書編號挨個尋覓,但這次他只花了20分鐘,之前未給圖書編號時要花2⑶小時,但與根據圖書編號查找圖書相比,時間還是太長了,因此他向那個聰明的小伙子求助。
[這就好像你給Product表增加了主鍵ProductID,但除此以外沒有建立其它索引,當使用Product Name進行檢索時,數據庫引擎又只要進行全表掃描,逐一尋覓了。]
聰明的小伙告知圖書管理員,之前已創建好了圖書編號,現在只需要再創建1個索引或目錄,將圖書名稱和對應的編號1起存儲起來,但這1次是按圖書名稱進行排序,如果有人想找“Database Management System”1書,你只需要跳到“D”開頭的目錄,然后依照編號就能夠找到圖書了。
因而圖書管理員興奮地花了幾個小時創建了1個“圖書名稱”目錄,經過測試,現在找1本書的時間縮短到1分鐘了(其中30秒用于從“圖書名稱”目錄中查找編號,另外根據編號查找圖書用了30秒)。
圖書管理員開始了新的思考,讀者可能還會根據圖書的其它屬性來找書,如作者,因而他用一樣的辦法為作者也創建了目錄,現在可以根據圖書編號,書名和作者在1分鐘內查找任何圖書了,圖書管理員的工作變得輕松了,故事也到此結束。
通過這個故事很容易理解索引的真正含義。假定我們有1個Products表,創建了1個聚集索引(根據表的主鍵自動創建的),我們還需要在ProductName列上創建1個非聚集索引,創建非聚集索引時,數據庫引擎會為非聚集索引自動創建1個索引樹(就象故事中的“圖書名稱”目錄1樣),產品名稱會存儲在索引頁中,每一個索引頁包括1定范圍的產品名稱和它們對應的主鍵鍵值,當使用產品名稱進行檢索時,數據庫引擎首先會根據產品名稱查找非聚集索引樹查出主鍵鍵值,然后使用主鍵鍵值查找聚集索引樹找到終究的產品。
確保每一個表都有主鍵
這樣可以確保每一個表都有聚集索引(表在磁盤上的物理存儲是依照主鍵順序排列的),使用主鍵檢索表中的數據,或在主鍵字段上進行排序,或在where子句中指定任意范圍的主鍵鍵值時,其速度都是非常快的。
在下面這些列上創建非聚集索引:
1)搜索時常常使用到的;
2)用于連接其它表的;
3)用于外鍵字段的;
4)高選中性的;
5)ORDER BY子句使用到的;
增加普通索引和UNIQUE兩種索引。其格式以下:
create index index_name on table_name (column_list) ;
create unique index index_name on table_name (column_list) ;
刪除索引
drop index index_name on table_name ;
alter table table_name drop index index_name ;

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


