
上1篇文章主要論述了HDFS Cache緩存方面的知識,本文繼續帶領大家了解HDFS內存存儲相干的內容.在HDFS中,CacheAdmin設置的目標文件緩存是會寄存于DataNode的內存中,但是另外1種情況也能夠將數據寄存在DataNode的內存里.就是之前HDFS異構存儲中提到的內存存儲策略,LAZY_PERSIST.換句話說,本文也是對HDFS內存存儲策略的1個更細致的分析.斟酌到LAZY_PERSIST內存存儲與其他存儲策略類型的不同的地方,做這樣的1個分析還是比較成心義的.
對內存存儲,可能很多人會存有這么幾種看法,
仔細來看以上這2種觀點,其實都有不小的瑕疵.
首先第1個觀點,服務1旦停止,內存數據全丟,這個是沒法接受的,我們可以忍耐內存中少許的數據丟失,但是全丟就不是特別好的處理方式了.而且這個也有點不公道,內存的存儲空間是有限的,如果不及時存儲1部份數據,內存空間早晚會耗盡.
然后是第2個觀點,第2個方案種是在服務停止退出的時候做持久化操作,但是他一樣會面臨上面提到的內存空間的限制問題.而且假定機器的內存是足夠大的,那末最后寫入磁盤的那個階段想必也不會那末快,由于數據可能會很多.
所以1般的通用的比較好的做法是異步的做持久化,甚么意思呢
內存存儲新數據的同時,持久化距離當前時刻最遠(存儲時間最早)的數據換1個通俗的解釋,好比我有個內存數據塊隊列,在隊列頭部不斷有新增的數據塊插入,就是待存儲的塊,由于資源有限 ,我要把隊列尾部的塊,也就是早些時間點的塊持久化到磁盤中,然后才有空間騰出來存新的塊.然后構成這樣的1個循環,新的塊加入,老的塊移除,保證了整體數據的更新.
HDFS的LAZY_PERSIST內存存儲策略用的就是這套方法.下面是1張原理圖:
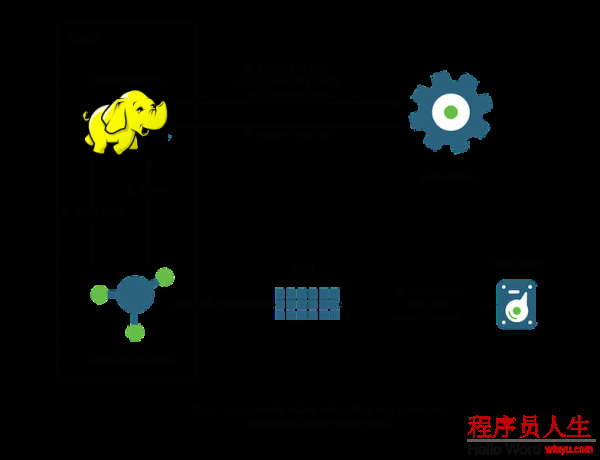
上文描寫的原理在圖中的表示實際上是4,6,的步驟.寫數據的RAM,然后異步的寫到Disk.前面幾個步驟是如何設置StorageType的操作,這個在下文種會具體提到.所以上圖所示的大體步驟可以歸納為以下:
內存的異步持久化存儲,就是明顯不同于其他介質存儲數據的地方.這應當也是LAZY_PERSIST的名稱的源由吧,數據不是馬上落盤,而是”lazy persisit”怠惰的方式,延時的處理.
這里需要了解1個額外的知識點,Linux 虛擬內存盤.之前我也是1直有個疑惑,內存也能夠當作1個塊盤使用?內存不就是臨時存數據用的嗎?因而在學習此模塊知識之前,特地查了相干的資料.其實在Linux中,可以用將內存摹擬為1個塊盤的技術,叫RAM disk.這是1種摹擬的盤,實質數據都是寄存在內存中的.RAM disk虛擬內存盤可以在某些特定的內存式存儲文件系統下結合使用,比如tmpfs,ramfs.關于tmpfsd百度百科鏈接點此.通過此項技術,我們就能夠將機器內存利用起來,作為1個獨立的虛擬盤供DataNode使用了.
下面論述的將是本文的核心內容,就是HDFS內存存儲的主要進程操作.不要小視這僅僅是1個單1的StoragePolicy,里面的進程可其實不簡單,在下面的進程種,我會給出比較多的進程圖的展現,幫助大家理解.
要想讓文件數據存儲到內存中,1開始你要做的操作就是設置此文件的存儲策略,就是上面提到的LAZY_PERSIST,而不是使用默許的StoragePolicy.DEFAULT,默許策略的存儲介質是DISK類型的.設置存儲策略的方法目前有2種:
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST方便,快速.
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);上述方式終究調用的是DFSClient的create同名方法,以下:
/**
* Call {@link #create(String, FsPermission, EnumSet, boolean, short,
* long, Progressable, int, ChecksumOpt)} with <code>createParent</code>
* set to true.
*/
public DFSOutputStream create(String src, FsPermission permission,
EnumSet<CreateFlag> flag, short replication, long blockSize,
Progressable progress, int buffersize, ChecksumOpt checksumOpt)
throws IOException {
return create(src, permission, flag, true,
replication, blockSize, progress, buffersize, checksumOpt, null);
}方法經過RPC層層調用,經過FSNamesystem,終究會到FSDirWriteFileOp的startFile方法,在此方法內部,會有設置的動作
static HdfsFileStatus startFile(
FSNamesystem fsn, FSPermissionChecker pc, String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize,
EncryptionKeyInfo ezInfo, INode.BlocksMapUpdateInfo toRemoveBlocks,
boolean logRetryEntry)
throws IOException {
assert fsn.hasWriteLock();
boolean create = flag.contains(CreateFlag.CREATE);
boolean overwrite = flag.contains(CreateFlag.OVERWRITE);
// 判斷CreateFlag是不是帶有LAZY_PERSIST標識,來判斷是不是是內存存儲策略的
boolean isLazyPersist = flag.contains(CreateFlag.LAZY_PERSIST);
...
// 然后在此設置策略
setNewINodeStoragePolicy(fsd.getBlockManager(), newNode, iip,
isLazyPersist);
fsd.getEditLog().logOpenFile(src, newNode, overwrite, logRetryEntry);
if (NameNode.stateChangeLog.isDebugEnabled()) {
NameNode.stateChangeLog.debug("DIR* NameSystem.startFile: added " +
src + " inode " + newNode.getId() + " " + holder);
}
return FSDirStatAndListingOp.getFileInfo(fsd, src, false, isRawPath);
}所以這部份的進程調用圖以下:

OK,以上就是前期存儲策略的設置進程了,這1部份還是非常的直接明了的.
這里直接跳到DataNode如何進行內存式存儲,當我們設置了文件為LAZY_PERSIST的存儲方式以后.我在下面會進行分模塊,分角色的介紹.
在之前的篇幅中已提到過,數據存儲的同時會有另外1批數據會被異步的持久化,所以這里1定會觸及到多個服務對象的合作.這些服務對象的指揮者是FsDatasetImpl.他是1個掌管DataNode所有磁盤讀寫數據的管家.
在FsDatasetImpl中,與內存存儲相干的服務對象有以下的3個.
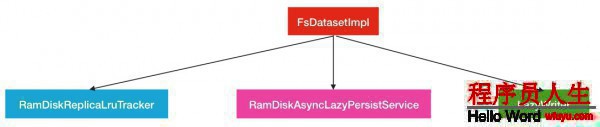
下面來1個個介紹:
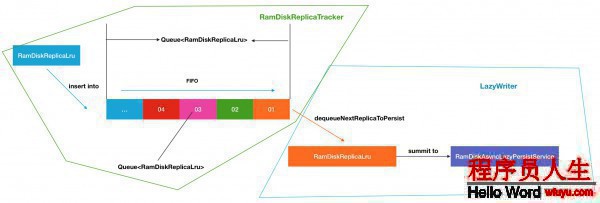
LazyWriter:lazyWriter是1個線程服務,此線程會不斷的循環著從數據塊列表中取出數據塊,加入到異步持久化線程池RamDiskAsyncLazyPersistService中去履行.
RamDiskAsyncLazyPersistService:此對象就是異步持久化線程服務,里面針對每個磁盤塊設置1個對應的線程池,然后需要持久化到給定的磁盤塊的數據塊會被提交到對應的線程池中去.每一個線程池的最大線程數為1.
RamDiskReplicaLruTracker:副本塊跟蹤類,此類種保護了所有已持久化,未持久化的副本和總副本數據信息.所以當1個副本被終究存儲到內存種后,相應的會有副本所屬隊列信息的變更.其次當節點內存不足的時候,部份距離最近最久沒有被訪問的副本塊會在此類中被移除.
綜合了以上3者的緊密合作,終究實現了HDFS的內存存儲.下面是具體的角色介紹.
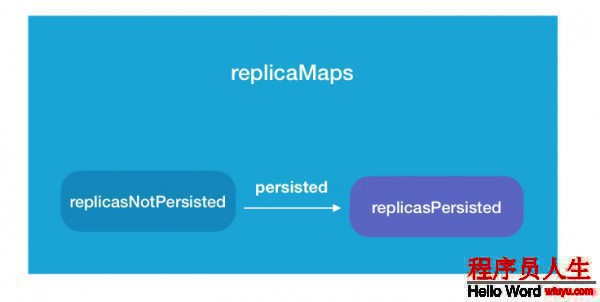
在以上3者中,RamDiskReplicaLruTracker的角色起到了1個中間人的角色.由于他內部保護了多個關系的數據塊信息.主要的就是以下3類.
public class RamDiskReplicaLruTracker extends RamDiskReplicaTracker {
...
/**
* Map of blockpool ID to <map of blockID to ReplicaInfo>.
*/
Map<String, Map<Long, RamDiskReplicaLru>> replicaMaps;
/**
* Queue of replicas that need to be written to disk.
* Stale entries are GC'd by dequeueNextReplicaToPersist.
*/
Queue<RamDiskReplicaLru> replicasNotPersisted;
/**
* Map of persisted replicas ordered by their last use times.
*/
TreeMultimap<Long, RamDiskReplicaLru> replicasPersisted;
...這里的Queue就是待內存存儲隊列.以上3個變量之間的關系圖以下
RamDiskReplicaLruTracker中的方法操作絕大多數與這3個變量的增刪改動相干,所以邏輯其實不復雜,我們只需要了解這些方法有甚么作用便可.我對此分成了2類:
第1類,異步持久化操作相干方法.如圖:
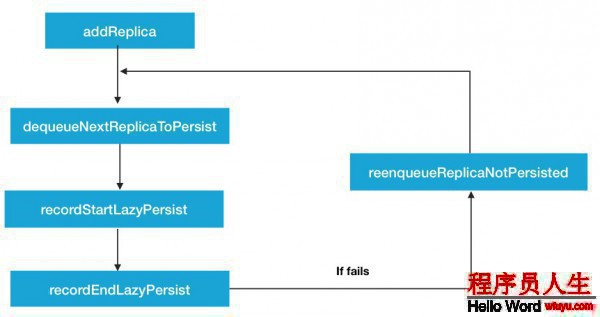
當節點重啟或有新的文件被設置了LAZY_PERSIST策略后,就會有新的副本塊被存儲到內存中,同時會加入到replicaNotPersisted隊列中.然后經過中間的dequeueNextReplicaToPersist取出下1個將被持久化的副本塊,進行寫磁盤的操作.recordStartLazyPersist,recordEndLazyPersist這2個方法會在持久化的進程中被調用,標志著持久化狀態的變更.
另外一類,異步持久化操作無直接關聯方法.如圖:

有下面3個方法:
這里反復提到1個名詞,LRU,他的全稱是Least Recently Used,意為最近最少使用算法,相干鏈接點此,getNextCandidateForEviction采取此算法的好處是保證了現有副本塊的1個活躍度,把最近很久沒有訪問過的給移除掉.對這個操作,我們有必要了解其中的細節.
先是touch會更新最近訪問的時間
synchronized void touch(final String bpid,
final long blockId) {
Map<Long, RamDiskReplicaLru> map = replicaMaps.get(bpid);
RamDiskReplicaLru ramDiskReplicaLru = map.get(blockId);
...
// Reinsert the replica with its new timestamp.
// 更新最近訪問時間戳,并重新插入數據
if (replicasPersisted.remove(ramDiskReplicaLru.lastUsedTime, ramDiskReplicaLru)) {
ramDiskReplicaLru.lastUsedTime = Time.monotonicNow();
replicasPersisted.put(ramDiskReplicaLru.lastUsedTime, ramDiskReplicaLru);
}
}然后是第2步獲得候選移除塊
synchronized RamDiskReplicaLru getNextCandidateForEviction() {
// 獲得replicasPersisted迭代器進行遍歷
final Iterator<RamDiskReplicaLru> it = replicasPersisted.values().iterator();
while (it.hasNext()) {
// 由于replicasPersisted已根據時間排好序了,所以取出當前的塊進行移除便可
final RamDiskReplicaLru ramDiskReplicaLru = it.next();
it.remove();
Map<Long, RamDiskReplicaLru> replicaMap =
replicaMaps.get(ramDiskReplicaLru.getBlockPoolId());
if (replicaMap != null && replicaMap.get(ramDiskReplicaLru.getBlockId()) != null) {
return ramDiskReplicaLru;
}
// The replica no longer exists, look for the next one.
}
return null;
}這里比較成心思的是,根據已持久化的塊的訪問時間來進行挑選移除,而不是直接是內存中的塊.最后是在內存中移除與候選塊屬于同1副本信息的塊并釋放內存空間.
/**
* Attempt to evict one or more transient block replicas until we
* have at least bytesNeeded bytes free.
*/
public void evictBlocks(long bytesNeeded) throws IOException {
int iterations = 0;
final long cacheCapacity = cacheManager.getCacheCapacity();
// 當檢測到內存空間不滿足外界需要的大小時
while (iterations++ < MAX_BLOCK_EVICTIONS_PER_ITERATION &&
(cacheCapacity - cacheManager.getCacheUsed()) < bytesNeeded) {
// 獲得待移除副本信息
RamDiskReplica replicaState = ramDiskReplicaTracker.getNextCandidateForEviction();
if (replicaState == null) {
break;
}
if (LOG.isDebugEnabled()) {
LOG.debug("Evicting block " + replicaState);
}
...
// 移除內存中的相干塊并釋放空間
// Delete the block+meta files from RAM disk and release locked
// memory.
removeOldReplica(replicaInfo, newReplicaInfo, blockFile, metaFile,
blockFileUsed, metaFileUsed, bpid);
}
}
}LazyWriter是1個線程服務,他是1個發動機,循環不斷的從隊列中取出待持久化的數據塊,提交到異步持久化服務中去.直接來看主要的run方法.
public void run() {
int numSuccessiveFailures = 0;
while (fsRunning && shouldRun) {
try {
// 取出新的副本塊并提交到異步服務中,返回是不是提交成功布爾值
numSuccessiveFailures = saveNextReplica() ? 0 : (numSuccessiveFailures + 1);
// Sleep if we have no more work to do or if it looks like we are not
// making any forward progress. This is to ensure that if all persist
// operations are failing we don't keep retrying them in a tight loop.
if (numSuccessiveFailures >= ramDiskReplicaTracker.numReplicasNotPersisted()) {
Thread.sleep(checkpointerInterval * 1000);
numSuccessiveFailures = 0;
}
} catch (InterruptedException e) {
LOG.info("LazyWriter was interrupted, exiting");
break;
} catch (Exception e) {
LOG.warn("Ignoring exception in LazyWriter:", e);
}
}
}進入saveNextReplica方法的處理
private boolean saveNextReplica() {
RamDiskReplica block = null;
FsVolumeReference targetReference;
FsVolumeImpl targetVolume;
ReplicaInfo replicaInfo;
boolean succeeded = false;
try {
// 從隊列種取出新的待持久化的塊
block = ramDiskReplicaTracker.dequeueNextReplicaToPersist();
if (block != null) {
synchronized (FsDatasetImpl.this) {
...
// 提交到異步服務中去
asyncLazyPersistService.submitLazyPersistTask(
block.getBlockPoolId(), block.getBlockId(),
replicaInfo.getGenerationStamp(), block.getCreationTime(),
replicaInfo.getMetaFile(), replicaInfo.getBlockFile(),
targetReference);
}
}
}
succeeded = true;
} catch(IOException ioe) {
LOG.warn("Exception saving replica " + block, ioe);
} finally {
if (!succeeded && block != null) {
LOG.warn("Failed to save replica " + block + ". re-enqueueing it.");
onFailLazyPersist(block.getBlockPoolId(), block.getBlockId());
}
}
return succeeded;
}所以LazyWriter線程服務的流程圖可以歸納為以下所示:
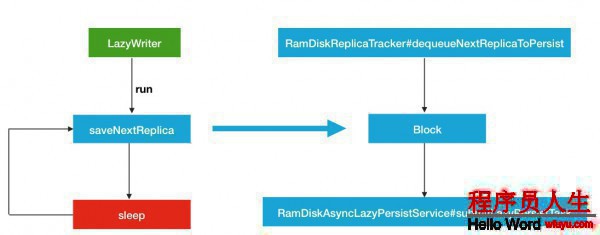
然后我們結合LazyWriter和RamDiskReplicaTracker跟蹤服務,就能夠得到下面1個完全的流程(暫且不斟酌RamDiskAsyncLazyPersistService的內部履行邏輯).
最后1部份的異步服務的內容相對就比較簡單1些了,主要圍繞著Volume磁盤和Executor線程池這2部份的內容.秉承著下面1個原則
1個磁盤服務對應1個線程池,并且1個線程池的最大線程數也只有1個.線程池列表定義以下
class RamDiskAsyncLazyPersistService {
...
private Map<File, ThreadPoolExecutor> executors
= new HashMap<File, ThreadPoolExecutor>();
...這里的File代表的是1個獨立的磁盤所在目錄,個人認為這里完全可以用String字符串替換.既可以減少存儲空間,又直觀明了.所以在這里就能夠看出是1對1的關系了.
當服務啟動的時候,就會有新的磁盤目錄加入.
synchronized void addVolume(File volume) {
if (executors == null) {
throw new RuntimeException("AsyncLazyPersistService is already shutdown");
}
ThreadPoolExecutor executor = executors.get(volume);
// 如果當前已存在此磁盤目錄對應的線程池,則跑異常
if (executor != null) {
throw new RuntimeException("Volume " + volume + " is already existed.");
}
// 否則進行添加
addExecutorForVolume(volume);
}進入addExecutorForVolume方法
private void addExecutorForVolume(final File volume) {
...
// 新建線程池,最大線程履行數為
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_THREADS_PER_VOLUME, MAXIMUM_THREADS_PER_VOLUME,
THREADS_KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(), threadFactory);
// This can reduce the number of running threads
executor.allowCoreThreadTimeOut(true);
// 加入到executors中,以為volume作為key
executors.put(volume, executor);
}還有1個需要注意的是提交履行方法submitLazyPersistTask.
void submitLazyPersistTask(String bpId, long blockId,
long genStamp, long creationTime,
File metaFile, File blockFile,
FsVolumeReference target) throws IOException {
if (LOG.isDebugEnabled()) {
LOG.debug("LazyWriter schedule async task to persist RamDisk block pool id: "
+ bpId + " block id: " + blockId);
}
// 獲得需要持久化到目標磁盤實例
FsVolumeImpl volume = (FsVolumeImpl)target.getVolume();
File lazyPersistDir = volume.getLazyPersistDir(bpId);
if (!lazyPersistDir.exists() && !lazyPersistDir.mkdirs()) {
FsDatasetImpl.LOG.warn("LazyWriter failed to create " + lazyPersistDir);
throw new IOException("LazyWriter fail to find or create lazy persist dir: "
+ lazyPersistDir.toString());
}
// 新建此服務Task
ReplicaLazyPersistTask lazyPersistTask = new ReplicaLazyPersistTask(
bpId, blockId, genStamp, creationTime, blockFile, metaFile,
target, lazyPersistDir);
// 提交到對應volume的線程池中履行
execute(volume.getCurrentDir(), lazyPersistTask);
}如果在上述履行的進程中產生失敗,會調用失敗處理的方法,并會重新將此副本塊插入到replicateNotPersisted隊列等待下1次的持久化.
public void onFailLazyPersist(String bpId, long blockId) {
RamDiskReplica block = null;
block = ramDiskReplicaTracker.getReplica(bpId, blockId);
if (block != null) {
LOG.warn("Failed to save replica " + block + ". re-enqueueing it.");
// 重新插入隊列操作
ramDiskReplicaTracker.reenqueueReplicaNotPersisted(block);
}
}其他的removeVolume等方法實現比較簡單,這里不做過量的介紹.下面是RamDiskAsyncLazyPersistService總的結構圖:
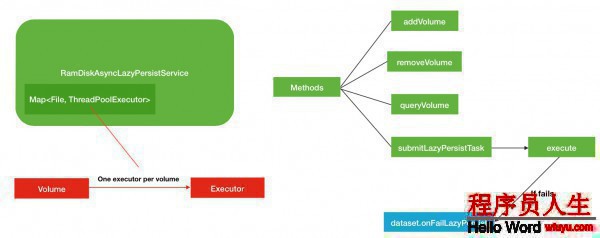
綜合以上3部份的內容論述,主要描寫了LAZT_PERSIST下的FIFO先進先出的隊列式內存數據塊持久化的順序,異步持久化服務的內部運行邏輯和LRU算法移除數據副本塊來預留內存空間.
介紹完以上原理部份的內容以后,最后補充具體的配置使用了.
首先要使用LAZY_PERSIST內存存儲策略,需要有對應的存儲介質,內存存儲介質對應的類型是RAM_DISK.
所以第1步,需要將機器中已完成好的RAM disk虛擬內存盤配置到配置項dfs.datanode.data.dir中,其次還要帶上,RAM_DISK的標簽.以下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>注意,這個標簽是必須要打上的,否則HDFS都默許的是DISK.
第2步就是設置具體的文件的策略類型了,上文中已提到過了.
然后附帶2個注意事項:
1.http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/MemoryStorage.html
2.百度百科.tmpfs
3.百度百科.RAM disk
4.百度百科.LRU算法

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


