
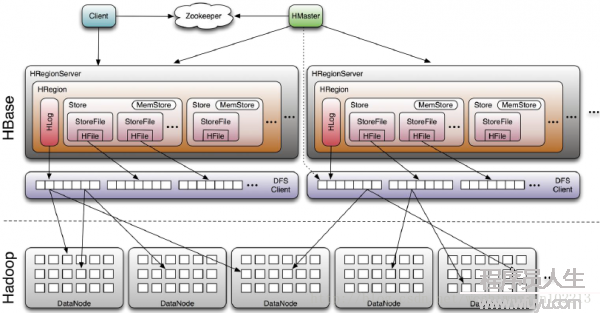
* Client
1. 包括訪問HBase的接口,并保護cache來加快對HBase的訪問,比如region的位置信息。
* Zookeeper:
1. 選舉集群中的Master,Master與RegionServers 啟動時會向ZooKeeper注冊。
2. 存儲所有Region的尋址入口。
3. 實時監控Region server狀態并實時通知Master。
4. 存儲HBase的schema和table元數據。
5. 使Master不存在單點故障。
* Master
1. 在Region Split后,為Region server分配region。
2. 管理HRegionServer的負載均衡,調劑Region散布。
3. 發現失效的Region server后重新分配其上的region,并負責Regions遷移。。
4. 管理用戶對table的增刪改查操作。
* Region Server
1. Regionserver保護region,處理對這些region的IO要求,向HDFS文件系統讀寫數據。
2. Regionserver負責切分在運行進程中變得過大的region。
* Region
1. table依照行分割成若干Region,每一個Region對應table中的1個Region。
2. Region由多個HStore組成。
* HLog
1. 類似mysql的binlog,數據會先寫到WAL上,然后再放到內存中,數據恢復。
2. 已持久化到StoreFile的HLog會定期被刪除。
* HStore
1. HBase的存儲核心,由MemStore和StoreFile組成。
2. 每一個HStore對應Table的1個列族的存儲。
* MemStore
1. 數據不直接寫磁盤而是先寫到MemStore,當滿了才會Flush到StoreFile中。
2. 底層由HFile實現。
3. 數據只需寫入到此內存便可返回,快速的插入操作。
* StoreFile
1. StoreFile文件數到1定閥值會觸發Compact合并操作,多個StoreFile變成1個StoreFile。
2. 所有數據操作都是添加操作,保證I/O,而對數據更新/刪除都是在后續compact進程中完成。
HBase支持很多文件系統的存儲。
1. 操作系統原生文件系統。
2. HDFS文件系統。
3. 其他文件系統。
HDFS可靠性高及其同屬同個生態,選擇HDFS作為存儲。
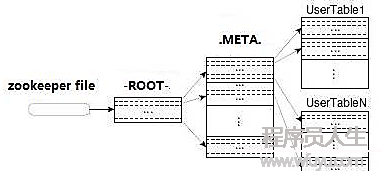
尋址進程大致為client -> -ROOT- -> .META. -> RS ->region -> rowkey。
客戶端會緩存查詢過的rowkey的地址。
client訪問hbase上數據的進程其實不需要master參與(尋址訪問zookeeper和region server,數據讀寫訪問region server),master僅僅保護table和region的元數據信息,負載很低。
HBase的插入性能很好,查詢還不錯,騰訊給出的數據是經過調優在百億數據級別80%以上數據能在20ms查到。
詳細的1些數據后面在寫代碼階段會給出。
當數據峰值接近系統設計容量時,可以簡單的通過增加服務器的方式來擴大容量。某種程度上來講,這個動態擴容進程無需停機,HBase系統可以照舊運行并提供讀寫服務,完全實現動態無縫無宕機擴容。
balance模式下,會自動將數據遷移到新機器上,合適中小集群,遷移進程大量消耗機器資源。
非balance模式下,新寫入文件寫到新機器上。
hbase優勢在于接近線性的任意水平擴大,沒必要在單機上與redis性能太叫真,看自己場景選擇。

上一篇 聊一聊ThreadLocal
下一篇 二叉搜索樹的第k個結點
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


