
在HDFS的使用進程中,有的時候集群保護者可能想要知道哪些用戶使用他們集群的資源比較多,以此有1個全面的了解。在YARN中,衡量用戶使用資源的1個指標是container數,而在HDFS中我們 可以用甚么指標呢?答案是要求數。固然你可能會說,為何不能用寫入寫出的總數據量作為指標呢?沒錯,這的確也是1個可選指標,但是明顯它們不容易搜集和統計,相比于要求數而言。那末問題又來了,是不是我們有必要自己寫程序做這樣的1套分析功能呢?HDFS是不是已幫我們做了這樣的事情呢?帶著以上的幾個問題,我們繼續下文的瀏覽,答案將會1點點的揭曉。
先拋開前面所說的內容,如果單純斟酌HDFS要求數的Top統計功能,我們會采取甚么樣的辦法呢?可能我們的實現思路會是這樣的:
在以上3步中,第1步的實現是最難的,由于這個“入口”不好找,在這里我羅列了3種辦法:
上面的第3種方案無疑是最好的方案,重新回到剛剛前言中提過的1個問題,現有HDFS中是不是已實現這樣的概念呢?答案是肯定的,在目前的Hadoop 2.7和以上版本中已實現了這樣的功能,相干JIRA HDFS⑹982(nntop: top--like tool for name node users)。此JIRA的實現者是來自twitter的1個hadoop工程師,此特性已在twitter內部用了幾個月的時間,然后此工程師將其貢獻到了社區。在HDFS⑹982的設計中,還添加了Top統計值的獲得方式,以下圖所示:
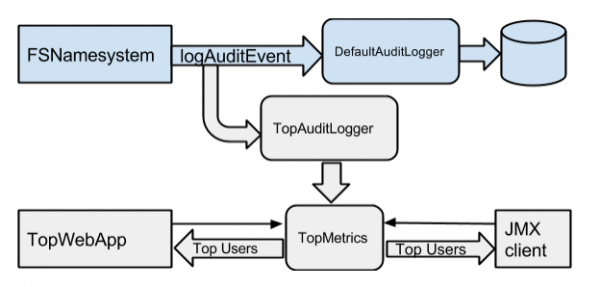
從上面的設計中,我們可以看到,這里新定義了1個叫TopAuditLogger來做這樣的攔截解析,將統計值存入TopMetrics中,然后通過web和jmx的方式進行Top用戶數據的獲得。在后面代碼的實現分析中,大家會更能體會此架構的設計思路。在HDFS⑹982中,將此HDFS Top要求數的用戶統計簡稱為HDFS nnTop,所以在后續的文字描寫中也將會以這樣的簡稱來稱呼。
在本節中,我們將會聊聊HDFS nnTop細節上的1些實現。其中最大的1個問題就是Metric統計值的細節設計,我們到底以怎樣樣的情勢來存這些統計值呢?由于不同的用戶在不同時間段內訪問的要求數是各不相同的,所以1個比較適合的辦法是每次統計階段時間內的Top user統計。然后對這個區間時間,我們是可以根據配置進行配置的,5分鐘,1分鐘,或30s等等。基于這個核心設計思想,在HDFS⑹982中,那位twitter的工程師使用了類似滑動窗口的機制,入下圖所示:
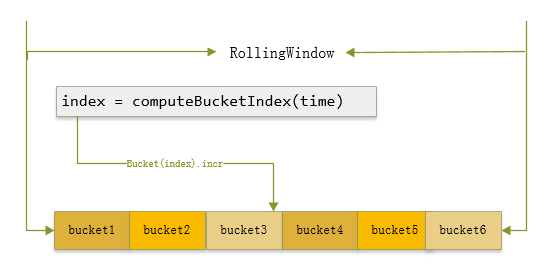
比如上面顯示的RollingWindow表示的全部區間是假定是最近1分鐘,就是60s,然后其內部份成了6個bucket,每一個bucket就是代表10s。然后根據動作的產生時間,計算出其中所在的bucket,在此bucket對象內進行計數累加。但是在這里得要提1點,bucket如果配的越多,代表統計的精度就會越準,一樣內存的開消也將會加大,這里會有1個內存空間與準確度之間的博弈比較。
這里的RollingWindow是對應到具體用戶的具體要求動作了。所在HDFS中,你會看到針對不同用戶,操作的許許多多的RollingWindow,它的總的結構組織圖如:
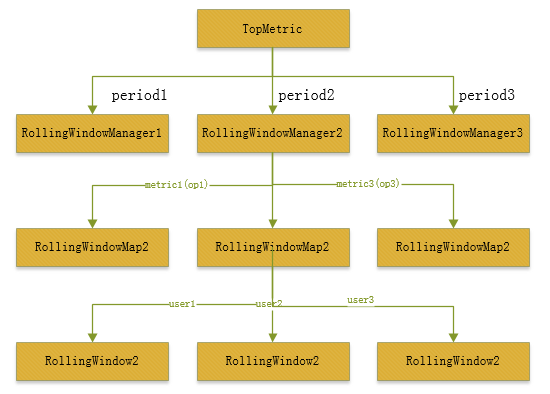
上面的結構圖用1句話概括以下:
TopMetric根據不同period時間創建不同的RollingWindowManager,在每一個RollingWindowManager中,又包括了數個不同操作要求類型的RollingWindowMap,最后在每一個RollingWindowMap中,依照用戶又劃分出了許多個RolingWindow對象。
下面是我們非常關注的nnTop的代碼實現部份,我盡可能會挑選其中核心的代碼進行分析,這樣看起來會更加的簡潔。
我們首先來看要求數據的攔截獲得,下面是TopMetric的定義,
public class TopMetrics {
...
// RollingWindowManagers對象圖,每一個對象映照到1個周期時間
final Map<Integer, RollingWindowManager> rollingWindowManagers =
new HashMap<Integer, RollingWindowManager>();
public TopMetrics(Configuration conf, int[] reportingPeriods) {
logConf(conf);
for (int i = 0; i < reportingPeriods.length; i++) {
// 根據配置傳入的period,創建不同的RollingWindowManager,并加入變量rollingWindowManagers中
rollingWindowManagers.put(reportingPeriods[i], new RollingWindowManager(
conf, reportingPeriods[i]));
}
}然后TopMetric會在FSNamesystem的initAuditLoggers方法中被構造,
private List<AuditLogger> initAuditLoggers(Configuration conf) {
// Initialize the custom access loggers if configured.
Collection<String> alClasses =
conf.getTrimmedStringCollection(DFS_NAMENODE_AUDIT_LOGGERS_KEY);
List<AuditLogger> auditLoggers = Lists.newArrayList();
...
// Add audit logger to calculate top users
// 判斷是不是開啟nnTop統計功能
if (topConf.isEnabled) {
// 創建TopMetric對象進行nnTop的統計,傳入配置的周期時間
topMetrics = new TopMetrics(conf, topConf.nntopReportingPeriodsMs);
// 新建TopAuditLogger對象進行audit log記錄的攔截處理
auditLoggers.add(new TopAuditLogger(topMetrics));
}
return Collections.unmodifiableList(auditLoggers);
}隨后在logAuditEvent方法中,topAuditLogger會被調用到,
private void logAuditEvent(boolean succeeded,
UserGroupInformation ugi, InetAddress addr, String cmd, String src,
String dst, HdfsFileStatus stat) {
FileStatus status = null;
...
final String ugiStr = ugi.toString();
// 在每次的logAuditEvent方法中,會得到每次的要求事件,給到AuditLogger處理,包括之前的TopAuditLogger
for (AuditLogger logger : auditLoggers) {
if (logger instanceof HdfsAuditLogger) {
HdfsAuditLogger hdfsLogger = (HdfsAuditLogger) logger;
hdfsLogger.logAuditEvent(succeeded, ugiStr, addr, cmd, src, dst,
status, CallerContext.getCurrent(), ugi, dtSecretManager);
} else {
logger.logAuditEvent(succeeded, ugiStr, addr, cmd, src, dst, status);
}
}
}在這里topAuditLogger的logAuditEvent一樣會被調用到,我們進入此方法,
public void logAuditEvent(boolean succeeded, String userName,
InetAddress addr, String cmd, String src, String dst, FileStatus status) {
try {
// 這里會調用topMetrics的report統計方法,進行計數的累加
topMetrics.report(succeeded, userName, addr, cmd, src, dst, status);
} catch (Throwable t) {
LOG.error("An error occurred while reflecting the event in top service, "
+ "event: (cmd={},userName={})", cmd, userName);
}
...
}每次的數據我們已拿到了,然后我們怎樣統計到之前的RollingWindow對象中呢?我們繼續剛才的topMetric的report統計方法,
public void report(long currTime, String userName, String cmd) {
LOG.debug("a metric is reported: cmd: {} user: {}", cmd, userName);
userName = UserGroupInformation.trimLoginMethod(userName);
for (RollingWindowManager rollingWindowManager : rollingWindowManagers
.values()) {
// 遍歷不同period的rollingWindowManager對象,傳入當前時間,操作類型,用戶,增加的計數值
rollingWindowManager.recordMetric(currTime, cmd, userName, 1);
// 額外增加總數的統計類型
rollingWindowManager.recordMetric(currTime,
TopConf.ALL_CMDS, userName, 1);
}
}Ok,上面的進程仿佛與之前我們所設計的進程10分的吻合了,我們再次進入RollWindowManafer的方法,
public void recordMetric(long time, String command,
String user, long delta) {
// 傳入操作類型,用戶名稱,獲得目標的RollingWindow對象
RollingWindow window = getRollingWindow(command, user);
// 在此rollingWindow中進行計數累加
window.incAt(time, delta);
}繼續進入RollingWindow的incr方法,
public void incAt(long time, long delta) {
// 計算當前時間對應的bucket下標
int bi = computeBucketIndex(time);
Bucket bucket = buckets[bi];
// 如果此時間已超過此bucket上次更新時間的周期范圍,進行計數重置,
// 表明此bucket是上1周期內的bucket。
if (bucket.isStaleNow(time)) {
bucket.safeReset(time);
}
// 增加bucket上的計數統計,此bucket內部用的是AtomicLong數據類型,所以不會有線程安全的問題
bucket.inc(delta);
}上面的統計方法,實際上是個滑動技術統計的進程,老的超時的bucket會被重新統計,然后又從0開始,相當因而往后挪了1個窗口,以此保證了最近周期內的統計,所之前面我們說bucket越多,統計的精度將會越準,bucket所控制的時間范圍會越短,重置bucket的影響會變小。
前面數據的攔截,統計都完成了,那末我們有甚么樣的方式拿到呢?這里以jmx的獲得方式為例,獲得的代碼以下,
public String getTopUserOpCounts() {
if (!topConf.isEnabled) {
return null;
}
Date now = new Date();
// 從topMetric對象中獲得top user返回結果
final List<RollingWindowManager.TopWindow> topWindows =
topMetrics.getTopWindows();
Map<String, Object> topMap = new TreeMap<String, Object>();
topMap.put("windows", topWindows);
topMap.put("timestamp", DFSUtil.dateToIso8601String(now));
try {
// 將Top統計結果轉為json字符返回
return JsonUtil.toJsonString(topMap);
} catch (IOException e) {
LOG.warn("Failed to fetch TopUser metrics", e);
}
return null;
}上面的代碼意味著通過http://nn-address:50070/jmx的方式能夠拿到top user的結果。本人在測試集群中進行測試,拿到的結果以下:
NNTop:
"NumStaleStorages" : 0,
"TopUserOpCounts" : "{\"timestamp\":\"2016-09⑴1T16:31:27+0800\",\"windows\":[{\"windowLenMs\":300000,\"ops\":
[{\"opType\":\"delete\",\"topUsers\":[{\"user\":\"root\",\"count\":3}],\"totalCount\":3},
{\"opType\":\"setTimes\",\"topUsers\":[{\"user\":\"data\",\"count\":2}],\"totalCount\":2},
{\"opType\":\"open\",\"topUsers\":[{\"user\":\"root\",\"count\":22230},{\"user\":\"data\",\"count\":4766}],\"totalCount\":26996},
{\"opType\":\"create\",\"topUsers\":[{\"user\":\"root\",\"count\":518},{\"user\":\"data\",\"count\":5}],\"totalCount\":523},
{\"opType\":\"setPermission\",\"topUsers\":[{\"user\":\"root\",\"count\":15}],\"totalCount\":15},
{\"opType\":\"*\",\"topUsers\":[{\"user\":\"root\",\"count\":50134},{\"user\":\"data\",\"count\":21943},{\"user\":\"bc\",\"count\":20}],\"totalCount\":72097},
{\"opType\":\"rename\",\"topUsers\":[{\"user\":\"root\",\"count\":285},{\"user\":\"data\",\"count\":2}],\"totalCount\":287},
{\"opType\":\"mkdirs\",\"topUsers\":[{\"user\":\"root\",\"count\":8},{\"user\":\"bc\",\"count\":4}],\"totalCount\":12},
{\"opType\":\"setReplication\",\"topUsers\":[{\"user\":\"root\",\"count\":212}],\"totalCount\":212},
{\"opType\":\"listStatus\",\"topUsers\":[{\"user\":\"data\",\"count\":12400},{\"user\":\"root\",\"count\":102}],\"totalCount\":12502},
{\"opType\":\"getfileinfo\",\"topUsers\":[{\"user\":\"root\",\"count\":25929},{\"user\":\"data\",\"count\":6362},{\"user\":\"bc\",\"count\":16}],\"totalCount\":32307}]},
{\"windowLenMs\":1500000,\"ops\":
[{\"opType\":\"delete\",\"topUsers\":...}"
}, {相信上面的統計結果大家都能直接看得懂,大家可以通過拿到jmx的數據,自行解析成object對象便可拿來用了。
OK,HDFS nnTop用戶Top要求數統計功能就是如上所描寫的,此功能默許是開啟的,由配置項dfs.namenode.top.enabled所控制,而且里面top用戶的數量和統計的周期時間都是可配的,大家可以好好把此功能給用起來了。
[1].https://issues.apache.org/jira/browse/HDFS⑹982
[2].https://issues.apache.org/jira/secure/attachment/12665990/nntop-design-v1.pdf

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


