
快速排序是最流行的,也是速度最快的排序算法(C++ STL 的sort函數(shù)就是實現(xiàn)的快速排序); 快速排序(Quicksort)是對冒泡排序的1種改進。由C. A. R. Hoare在1962年提出。它的基本思想是:通過1趟排序?qū)⒁判虻臄?shù)據(jù)分割成獨立的兩部份,其中1部份的所有數(shù)據(jù)都比另外1部份的所有數(shù)據(jù)都要小,然后再按此方法對這兩部份數(shù)據(jù)分別進行快速排序,全部排序進程可以遞歸進行,以此到達全部數(shù)據(jù)序列變成有序序列。其算法的特點就是有1個樞軸(pivot), 樞軸左側(cè)的元素都小于/等于樞軸所指向的元素, 樞軸右側(cè)的元素都大于樞軸指向的元素;
快速排序算法思想:
設(shè)要排序的數(shù)組是A[0], ..., A[N⑴],首先任意選取1個數(shù)據(jù)作為standard(通常選用數(shù)組的最后1個數(shù))作為關(guān)鍵數(shù)據(jù),然后將所有比它小的數(shù)都放到它前面,所有比它大的數(shù)都放到它后面(其實只要保證所有比他小的元素都在其前面,則后1條件則自動滿足了),這個進程稱為1趟快速排序。值得注意的是,快速排序不是1種穩(wěn)定的排序算法,也就是說,多個相同的值的相對位置或許會在算法結(jié)束時產(chǎn)生變動。(信息來源:百度百科)
目標(biāo):
找1個記錄,以它的關(guān)鍵字/下標(biāo)作為”樞軸/pivot”,凡是值小于樞軸的元素均移動至該樞軸所指向的記錄之前,凡關(guān)鍵字大于樞軸的記錄均移動至該記錄以后。
導(dǎo)致1趟排序以后,記錄的無序序列R[s..t]將分割成兩部份:R[s..i⑴]和R[i+1..t],且
R[j].value ≤ R[i].value ≤ R[j].value
首先對無序的記錄序列進行“1次劃分”,以后分別對分割所得兩個子序列“遞歸”進行快速排序。
假定1次劃分所得樞軸位置 i = k,則對 n 個記錄進行快排所需時間:
T(n) = {Tpass(n) + T(k⑴) + T(n-k) |Tpass(n)為對 n 個記錄進行1次劃分所需時間}
若待排序列中記錄的關(guān)鍵字是隨機散布的,則 k 取 1 至 n 中任意1值的可能性相同。
由此可得快速排序所需時間的平均值為:

設(shè) Tavg(1)≤b,則可得結(jié)果:
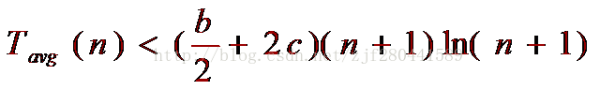
因此:快速排序的時間復(fù)雜度為O(nlogn)
若待排記錄的初始狀態(tài)為按關(guān)鍵字有序時,快速排序?qū)櫬錇槠鹋菖判颍鋾r間復(fù)雜度為O(n^2)。
為避免出現(xiàn)這類情況,需在進行1次劃分之前,進行“預(yù)處理”,即:先對 R(s).key, R(t).key 和 R[?(s+t)/2?].key,進行相互比較,然后取關(guān)鍵字為3個元素中居中間的那個元素作為樞軸記錄。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


