
第1次采取Markdown看看效果。
思路:首先找到1篇小說,獲得第1章小說的URL,然后根據該URL來獲得該章小說的標題、內容和下1章的URL。以后重復類似動作,就可以獲得到整篇小說的內容了。
實現方法:這里語言采取==Java==,使用了jsoup。jsoup簡單的使用方法可以參考這里。
實現進程:首先找到1篇小說,這里以“神墓”為例,我們打開第1章,然后查看網頁源代碼。
在源碼中我們可以看到下1頁的url、文章標題和小說內容。我們可以先獲得1個Document對象,然后分別根據Element的Id或樣式來獲得小說的內容、標題或下1頁URL。



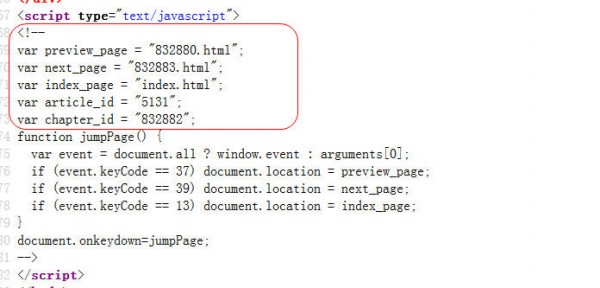
實現代碼:新建1個項目spider,導入jsoup⑴.7.3.jar包。
package com.dapeng.bean;
public class Article {
private String id;//id
private String title;//標題
private String content;//內容
private String url;//當前章節url
private String nextUrl;//下1章url
/**
*省略getter、setter方法
*/
@Override
public String toString() {
return "Article [id=" + id + ", title=" + title + ", content="
+ content + ", url=" + url + ", nextUrl=" + nextUrl + "]";
}
}2.新建com.dapeng.method包,在該包下新建UtilMethod類。主要用于實現獲得文章標題、內容、下1章URL等方法。其代碼以下:
package com.dapeng.method;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import com.dapeng.bean.Article;
public class UtilMethod {
/**
* 根據url獲得Document對象
* @param url 小說章節url
* @return Document對象
*/
public static Document getDocument(String url){
Document doc = null;
try {
doc = Jsoup.connect(url).timeout(5000).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return doc;
}
/**
* 根據獲得的Document對象找到章節標題
* @param doc
* @return 標題
*/
public static String getTitle(Document doc){
return doc.getElementById("title").text();
}
/**
* 根據獲得的Document對象找到小說內容
* @param doc
* @return 內容
*/
public static String getContent(Document doc){
if(doc.getElementById("content") != null){
return doc.getElementById("content").text();
}else{
return null;
}
}
/**
* 根據獲得的Document對象找到下1章的Url地址
* @param doc
* @return 下1章Url
*/
public static String getNextUrl(Document doc){
Element ul = doc.select("ul").first();
String regex = "<li><a href="(.*?)">下1頁</a></li>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(ul.toString());
Document nextDoc = null;
if (matcher.find()) {
nextDoc = Jsoup.parse(matcher.group());
Element href = nextDoc.select("a").first();
return "http://www.bxwx.org/b/5/5131/" + href.attr("href");
}else{
return null;
}
}
/**
* 根據url獲得id
* @param url
* @return id
*/
public static String getId(String url){
String urlSpilts[] = url.split("/");
return (urlSpilts[urlSpilts.length - 1]).split(".")[0];
}
/**
* 根據小說的Url獲得1個Article對象
* @param url
* @return
*/
public static Article getArticle(String url){
Article article = new Article();
article.setUrl(url);
Document doc = getDocument(url);
article.setId(getId(url));
article.setTitle(getTitle(doc));
article.setNextUrl(getNextUrl(doc));
article.setContent(getContent(doc));
return article;
}
}
3.新建com.dapeng.test包,用于測試獲得整篇小說。新建GetArticles類。其代碼以下:
package com.dapeng.test;
import com.dapeng.bean.Article;
import com.dapeng.method.UtilMethod;
public class GetArticles {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
String firstUrl = "http://www.bxwx.org/b/5/5131/832882.html";
Article article = UtilMethod.getArticle(firstUrl);
while(article.getNextUrl() != null && article.getContent() != null && !article.getId().equals("996627")){
article = UtilMethod.getArticle(article.getNextUrl());
System.out.println(article.getId()+"----"+article.getTitle());
}
}
}
運行GetArticles方法,可以看到類似以下的效果:
832883----第1卷 從神墓中走出 第2章 滄海桑田
832884----第1卷 從神墓中走出 第3章 人世悠悠
832885----第1卷 從神墓中走出 第4章 無解之謎
832886----第1卷 從神墓中走出 第5章 冷艷
832887----第1卷 從神墓中走出 第6章 公主
832888----第1卷 從神墓中走出 第7章 小惡魔
832889----第1卷 從神墓中走出 第8章 烈火仙蓮
832890----第1卷 從神墓中走出 第9章 百丈巨蛇
....到這里該代碼就告1段落了。后續的就不再進行了,比如說將小說插入數據庫,然后自己搭建1個小說站點,或將小說寫入到1個txt文檔中,不用再看那煩人的廣告了。等等。。這里就不再進行了。
最后代碼附上。

上一篇 andriod 藍牙打印問題
下一篇 Docker的核心是什么?
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


