
最早知道ANTLR是當年學習Apache Derby數據庫源碼時,在看到SQL解析那1層時,第1次看到編譯原理在實際項目中的利用,驚嘆之余也只能望而生畏。之前也根據網上1些資料嘗試了1下,看介紹說ANTLR v4更加易用了,因而又好奇地試用1下。以下入門介紹主要參考ANTLR作者寫的《The Definitive ANTLR 4 Reference》。
當我們實現1種語言時,我們需要構建讀取句子(sentence)的利用,并對輸入中的元素做出反應。如果利用計算或履行句子,我們就叫它解釋器(interpreter),包括計算器、配置文件讀取器、Python解釋器都屬于解釋器。如果我們將句子轉換成另外一種語言,我們就叫它翻譯器(translator),像Java到C#的翻譯器和編譯器都屬于翻譯器。不論是解釋器還是翻譯器,利用首先都要辨認出所有有效的句子、詞組、字詞組等,辨認語言的程序就叫解析器(parser)或語法分析器(syntax analyzer)。我們學習的重點就是如何實現自己的解析器,去解析我們的目標語言,像DSL語言、配置文件、自定義SQL等等。
手動編寫解析器是非常繁瑣的,所以我們有了ANTLR。只需編寫ANTLR的語法文件,描寫我們要解析的語言的語法,以后ANTLR就會自動生成能解析這類語言的解析器。也就是說,ANTLR是1種能寫出程序的程序。在學習LISP或Ruby的宏時,我們常常能接觸到元編程的概念。而用來聲明我們語言的ANTLR語言的語法,就是元語言(meta-language)。
為了簡單起見,我們將解析分為兩個階段,對應我們的大腦讀取文字時的進程。當我們讀到1個句子時,在第1階段,大腦會下意識地將字符組成單詞,然后像查詞典1樣辨認出它們的意思。在第2階段,大腦會根據已辨認的單詞去辨認句子的結構。第1階段的進程叫詞法分析(lexical analysis),對應的分析程序叫做lexer,負責將符號(token)分組成符號類(token class or token type)。而第2階段就是真實的parser,默許ANTLR會構建出1棵分析樹(parse tree)或叫語法樹(syntax tree)。以下圖,就是簡單的賦值表達式的解析進程:
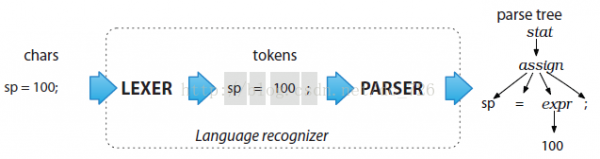

語法樹的葉子是輸入token,而上級結點時包括其孩子結點的詞組名(phase),線性的句子實際上是語法樹的序列化。終究生成語法樹的好處是:
1) 樹形結構易于遍歷和處理,并且易被程序員理解,方便了利用代碼做進1步處理。
2) 多種解釋或翻譯的利用代碼都可以重用1個解析器。但ANTLR也支持像傳統解析器生成器那樣,將利用處理代碼嵌入到語法中。
3) 對由于計算依賴而需要多趟處理的翻譯器來講,語法樹非常有用!我們不用屢次調用解析器去解析,只需高效地遍歷語法樹屢次。
ANTLR生成的解析器叫做遞歸降落解析器(recursive-descent parser),屬于自頂向下解析器(top-down parser)的1種。顧名思義,遞歸降落指的就是解析進程是從語法樹的根開始向葉子(token)遞歸,比較酷的是代碼的調用圖能與樹結點對應上。還是之前面的賦值表達式解析為例,其遞歸降落解析器的代碼大概是下面這個模樣:


Assign很簡單,直接順序讀取輸入字符,不用做任何選擇。相比之下,根結點Stat要復雜1些,由于它有多種選擇。解析時,要向前看(lookahead)1些字符才能確認走哪一個分支代碼,有時乃至要讀取完所有輸入才能預測出,而ANTLR默默為我們處理了1切!
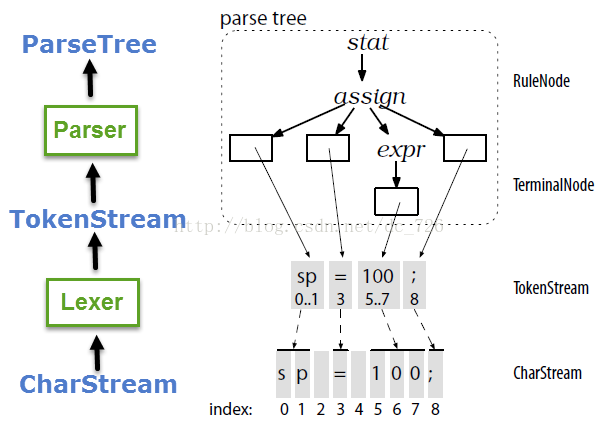
在內部,ANTLR的數據結構會盡量地同享數據來節儉內存,這類考量在Nginx的String中也能看到。以下圖所示,解析樹的葉子節點指向Token流中的Token,而Token中的起止字符索引指向字符流,而非拷貝子字符串。而像空格這類不與任何Token相干的字符會直接被Lexer拋棄掉。

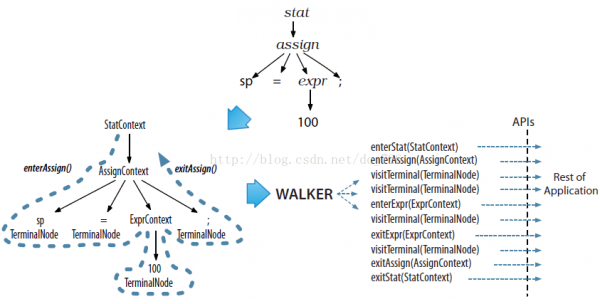
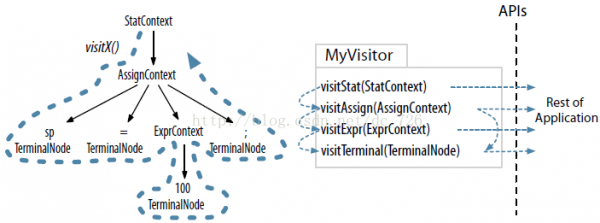
ANTLR為每一個Rule都會生成1個Context對象,它會記錄辨認時的所有信息。ANTLR提供了Listener和Visitor兩種遍歷機制。Listener是全自動化的,ANTLR會主導深度優先遍歷進程,我們只需處理各種事件就能夠了。而Visitor則提供了可控的遍歷方式,我們可以自行決定是不是顯示地調用子結點的visit方法。

目前還未深入使用,對v4的新特性了解的不多,摘錄1段“antlr v4新特性總結及與antlr v3的不同”:
1) 學習曲線低。antlr v4相對v3,v4更重視于用更接近于自然語言的方式去解析語言。比如運算符優先級,排在最前面的規則優先級最高;
2) 層次更清晰、更容易保護。引入訪問者、監聽器模式,使解析與利用代碼分離;新
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


