
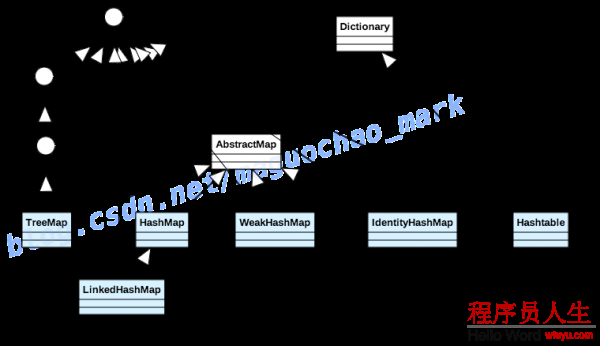
java.util
Interface Map
Type Parameters:
K - the type of keys maintained by this map
V - the type of mapped valuesBindings, ConcurrentMap<K,V>, ConcurrentNavigableMap<K,V>, LogicalMessageContext,
MessageContext, NavigableMap<K,V>, SOAPMessageContext, SortedMap<K,V>AbstractMap, Attributes, AuthProvider, ConcurrentHashMap, ConcurrentSkipListMap, EnumMap,
HashMap, Hashtable, IdentityHashMap, LinkedHashMap, PrinterStateReasons, Properties,
Provider, RenderingHints, SimpleBindings, TabularDataSupport, TreeMap, UIDefaults,
WeakHashMap先來看看 interface Map 的定義
interface Map 定義了整體的數(shù)據(jù)結(jié)構(gòu)
下面我們逐一介紹具體的實(shí)現(xiàn)類來講明
package java.util;
public interface Map<K,V> {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> { // 子接口
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
boolean equals(Object o);
int hashCode();
}public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
/**
* 默許初始容量,必須是2的倍數(shù) .
* 為何是2的倍數(shù)后面介紹到 .
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大容量 1<<30.
* 必須是2的倍數(shù)
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 1個空表實(shí)例,是1個Entry類型數(shù)組 .
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* 表根據(jù)需要調(diào)劑大小。長度必須是2的冪
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* map確當(dāng)前長度.
*/
transient int size;
/**
* 要調(diào)劑大小的極限值(容量*默許計算閥值參數(shù)因子) resize (capacity * load factor)
*
* @serial
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
int threshold;
/**
* 哈希表的負(fù)載系數(shù).
*
* @serial
*/
final float loadFactor;
/**
*
* 這個HashMap結(jié)構(gòu)修改的次數(shù)
* 結(jié)構(gòu)修改是那些改變的映照
* HashMap或修改其內(nèi)部結(jié)構(gòu)(例如重復(fù))。
* 這個字段是用來使迭代器的集合視圖 HashMap很快失敗。
* (見ConcurrentModificationException)。
*
*/
transient int modCount;
} /**
* 構(gòu)造1個HashMap
* 初始容量
* 負(fù)載系數(shù)
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 默許初始大小 16
* 默許計算閥值參數(shù)因子 0.75
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* 接受map子集 , 將map子集轉(zhuǎn)換為HashMap類型數(shù)據(jù) .
* 默許計算閥值參數(shù)因子 .75
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}通過源碼分析,明確清楚程序首先根據(jù)該 key 的 hashCode() 返回值決定該 Entry 的存儲位置:如果兩個 Entry 的 key 的 hashCode() 返回值相同,那它們的存儲位置相同。如果這兩個 Entry 的 key 通過 equals 比較返回 true,新添加 Entry 的 value 將覆蓋集合中原有 Entry 的 value。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);//根據(jù)key計算hash值
int i = indexFor(hash, table.length);//計算出索引
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}hash 方法是位運(yùn)算的進(jìn)程
關(guān)于位運(yùn)算可以移步到我的另外一篇文章
http://blog.csdn.net/maguochao_mark/article/details/51010289
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
indexFor(int h, int length) 方法來計算該對象應(yīng)當(dāng)保存在 table 數(shù)組的哪一個索引處。
/**
* 當(dāng) length 總是 2 的倍數(shù)時,h & (length⑴)
* 將是1個非常奇妙的設(shè)計:假定 h=5,length=16, 那末 h & length - 1 將得到 5;
* 如果 h=6, length=16, 那末 h & length - 1 將得到 6 ;
* 如果 h=15,length=16, 那末 h & length - 1 將得到 15 ;
* 但是當(dāng) h=16 時 , length=16 時,那末 h & length - 1 將得到 0 了;當(dāng) h=17 時 ,
* length=16 時,那末 h & length - 1 將得到 1 了
* 這樣保證計算得到的索引值總是位于 table 數(shù)組的索引以內(nèi)。
*/
static int indexFor(int h, int length) {
return h & (length-1);
}由于hash算法是取hashCode在進(jìn)行位運(yùn)算,那末難免會有hashCode相同的情況產(chǎn)生.
那末這個時候HashMap是怎樣添加值的呢?我們來通過1段代碼來講明 .
package com.cn.mark.java.util;
import java.util.HashMap;
class Student {
public Student(String name) {
this.setName(name);
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int hashCode() {
return 9999; // 測試 使得 hashCode 相同
}
public boolean equals(Object obj) {
Student student = (Student) obj;
if (this.getName().equals(student.getName()))
return true;
return false;
}
}
@SuppressWarnings({ "rawtypes", "unchecked" })
public class HashMapTest {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put(new Student("zhangsan"), "zhangsan");
map.put(new Student("lisi"), "lisi");
}
}
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);//根據(jù)key計算hash值
int i = indexFor(hash, table.length);//計算出索引
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];//會取出 zhangsan 的 Student 對象
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}我們看到createEntry時將 zhangsan 的 Student 對象 做為參數(shù)傳遞給了 new Entry<>(hash, key, value, e);方法.
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
static class Entry<K,V> implements Map.Entry<K,V> {
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}在new Entry<>(hash, key, value, e); 方法中是將 zhangsan 的 Student 對象 作為了 lisi的next屬性關(guān)聯(lián)這.
也就是說 hash相同時會構(gòu)成1個 Entry的單項鏈表,最早加入的Entry會在當(dāng)前鏈表的最末端 .
當(dāng)HashMap中的元素愈來愈多的時候,hash沖突的概率也就愈來愈高,由于數(shù)組的長度是固定的。所以為了提高查詢的效力,就要對HashMap的數(shù)組進(jìn)行擴(kuò)容,數(shù)組擴(kuò)容這個操作也會出現(xiàn)在ArrayList中,這是1個經(jīng)常使用的操作,而在HashMap數(shù)組擴(kuò)容以后,最消耗性能的點(diǎn)就出現(xiàn)了:原數(shù)組中的數(shù)據(jù)必須重新計算其在新數(shù)組中的位置,并放進(jìn)去,這就是resize。
那末HashMap甚么時候進(jìn)行擴(kuò)容呢?當(dāng)HashMap中的元素個數(shù)超過 數(shù)組大小*loadFactor時,就會進(jìn)行數(shù)組擴(kuò)容,loadFactor的默許值為0.75,這是1個折衷的取值。也就是說,默許情況下,數(shù)組大小為16,那末當(dāng)HashMap中元素個數(shù)超過16*0.75=12的時候,就把數(shù)組的大小擴(kuò)大為 2*16=32,即擴(kuò)大1倍,然后重新計算每一個元素在數(shù)組中的位置,而這是1個非常消耗性能的操作,所以如果我們已預(yù)知HashMap中元素的個數(shù),那末預(yù)設(shè)元素的個數(shù)能夠有效的提高HashMap的性能。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
} 我們知道java.util.HashMap是線程不安全的,因此如果在使用迭代器的進(jìn)程中有其他線程修改了map,那末將拋出ConcurrentModificationException,這就是所謂fail-fast策略。
這1策略在源碼中的實(shí)現(xiàn)是通過modCount域,modCount顧名思義就是修改次數(shù),對HashMap內(nèi)容的修改都將增加這個值,那末在迭代器初始化進(jìn)程中會將這個值賦給迭代器的expectedModCount。
在迭代進(jìn)程中,判斷modCount跟expectedModCount是不是相等,如果不相等就表示已有其他線程修改了Map注意到modCount聲明為volatile,保證線程之間修改的可見性。
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


