
在Hadoop⑵.4之前,Yarn中的ResourceManager也是單點故障中的,就像Hadoop⑴.x中的NameNode,由于Hadoop⑵.X已支持NameNode的HA(高可用性),那末自然也要在hadoop的某個版本中實現ResourceManager的HA,否則又會招致1些事后諸葛亮的詬病。本文將介紹RM的高可用性,并詳細學習如何配置和使用該特性。就像NameNode的HA1樣,ResourceManager的HA也是通過冗余的Active/Standby ResourceManagers消除單點故障所存在的問題。
RM的HA架構以下(引自官方圖片),該圖所展現的架構與NameNode有很多類似的地方,比如支持自動或手動的故障轉移,使用ZooKeeper保存Active RM的狀態等。
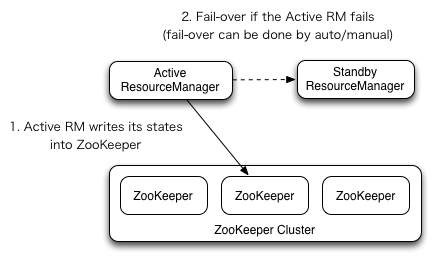
ResourceManager的HA是通過Active/Standby架構實現的,在任什么時候間點只有1個RM處于active狀態,而剩余的RM(1個或多個)則處于standby狀態,時刻準備著接收active的工作。可以通過在CLI輸入命令或在自動故障轉移啟動的條件下通過集成的故障轉移控制器實現standby到active的轉換,也就是手動故障轉移和自動故障轉移。
在沒啟用自動故障轉移的情況下,管理員必須手動地將處于standby狀態的RMs之1轉換為active狀態。手動故障轉移必須首先將本來處于active的RM轉換為standby狀態,然后再將1個standby RM轉換為active,具體的命令為:yarn rmadmin。在自動故障轉移方面,RM與NameNode略有不同,RM不需要運行單獨的守護進程ZKFC,這是由于RM有內置的基于ZooKeeper的ActiveStandbyElector類用于在active RM宕機或無響應時自動選擇哪一個standbyRM將做為active RM,由于該類實現了ZKFC的功能。
當存在多個RMs時,需要在yarn-site.xml中羅列所有RMs,這是由于客戶端、ApplicationMasters (AMs) 和NodeManagers (NMs)以循環的方式嘗試連接RM直到連接上active RM。當active RM不可用時,再依照循環的方式嘗試連接RMs,直到遇上新的active RM。默許的嘗試邏輯由org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider實現,可以通過實現org.apache.hadoop.yarn.client.RMFailoverProxyProvider接口和設置yarn.client.failover-proxy-provider的值為新類以覆蓋默許邏輯。
如果也啟用了RM的重啟特性,正在變成active狀態的RM能夠加載RM的內部狀態和盡量多的繼續先前active RM遺留的操作。將為每一個之條件交到RM的利用程序提交新的嘗試,利用程序可以周期性地進行檢查點以免丟失任何工作。狀態存儲必須對Active/Standby RMs都是可見的,正如之前已了解的,目條件供了兩個狀態存儲:FileSystemRMStateStore和ZKRMStateStore,建議在RM HA集群中使用后者做為狀態存儲。
正如Hadoop大部份特性都可以通過配置參數進行設置1樣,RM的HA也能夠通過下表中的參數進行設置(更詳細的信息可以參考yarn-default.xml):
參數 | 描寫 |
yarn.resourcemanager.zk-address | ZooKeeper服務器的地址(主機:端口號),既用于狀態存儲也用于內嵌的leader-election。 |
yarn.resourcemanager.ha.enabled | 是不是啟用RM HA,默許為false(不啟用)。 |
yarn.resourcemanager.ha.rm-ids | RMs的邏輯id列表,用逗號分隔,如:rm1,rm2 |
yarn.resourcemanager.hostname.rm-id | 每一個rm-id的主機名,rm-id的值包括在上面的參數值中。 |
yarn.resourcemanager.ha.id | 可選項,用于標識RM。如果設置了,管理員需要確保所有的RMs在配置中都有自己的ID。 |
yarn.resourcemanager.ha.automatic-failover.enabled | 是不是啟用自動故障轉移。默許情況下,在啟用HA時,啟用自動故障轉移。 |
yarn.resourcemanager.ha.automatic-failover.embedded | 啟用內置的自動故障轉移。默許情況下,在啟用HA時,啟用內置的自動故障轉移。 |
yarn.resourcemanager.cluster-id | 集群的Id,elector使用該值確保RM不會做為其它集群的active。 |
yarn.client.failover-proxy-provider | Clients, AMs和NMs使用該類故障轉移到active RM。 |
yarn.client.failover-max-attempts | FailoverProxyProvider嘗試故障轉移的最大次數。 |
yarn.client.failover-sleep-max-ms | 故障轉移間的最大休眠時間(單位:毫秒)。 |
yarn.client.failover-retries | 每一個嘗試連接到RM的重試次數。 |
yarn.client.failover-retries-on-socket-timeouts | 在socket超時時,每一個嘗試連接到RM的重試次數。 |
下面是RM故障轉移的簡單配置示例,在該示例中啟用了HA,那末也就啟用了自動故障轉移。
正如上面提到的,hadoop也為管理員提供了CLI的方式管理RM HA,但在沒有啟用HA的情況下,下面的命令是不可用的:
假定已啟用了HA,那末就能夠通過CLI的方式查看RM的狀態和手動進行故障轉移,假定yarn.resourcemanager.ha.rm-ids的值為rm1和rm2:
手動故障轉移必須在自動故障轉移禁用的條件下履行,否則會出現split-brain的情形或其它不正確的狀態,手動故障轉移的命令為:

上一篇 房間安排(nyoj168)
下一篇 玩轉Oracle服務器連接
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


