
遇到罕見病例時,醫院會組織專家團進行臨床會診共同分析病例以判定結果。猶如專家團臨床會診1樣,重大決定匯總多個人的意見常常勝過1個人的決定。機器學習中也吸取了‘3個臭皮匠頂個諸葛亮’(實質上是由3個裨將頂個諸葛亮口誤演變而來)的思想,這就是元算法的思想。元算法(meta-algorithm)也叫集成方法(ensemble method),通過將其他算法進行組合而構成更優的算法,組合方式包括:不同算法的集成,數據集不同部份采取不同算法分類后的集成或同1算法在不同設置下的集成。
有了元算法的思想,PAC((Probably Approximately Correct)學習模型中就有了弱學習算法和強學習算法的等價性問題--即組合任意給定的弱學習算法 ,是不是可以將其提升為強學習算法 ? 如果2者等價 ,那末只需將弱學習算法提升為強學習算法就行,而沒必要尋覓很難取得的強學習算法。理論證明,實際上只要弱分類器個數趨向于無窮個時,其組合而成的強分類器的毛病率將趨向于零。
弱學習算法---辨認毛病率小于1/2(即準確率僅比隨機猜想略高的學習算法)
強學習算法---辨認準確率很高并能在可接受時間內完成的學習算法
介紹幾種比較重要的將多個分類器整合為1個分類器的方法--boostrapping方法、bagging方法和Boosting算法。
1)Bootstrapping:
i)重復地從1個樣本集合D中采樣n個樣本,新樣本中可能存在重復的值或丟失原樣本集合的1些值。
ii)針對每次采樣的子樣本集,進行統計學習,取得假定Hi
iii)將若干個假定進行組合,構成終究的假定Hfinal
iv)將終究的假定用于具體的分類任務
2)Bagging方法
i)訓練分類器-從整體樣本集合中,抽樣n* < N個樣本, 針對抽樣的集合訓練分類器Ci,抽取方法有很多種
ii)分類器進行投票,終究的結果是分類器投票的優越結果,每一個分類器權重是相等的
3)Boosting
Boosting是1種與Bagging很類似的技術,二者所使用的多個分類器的類型都是1致的。但是在前者當中,不同的分類器是通過串行訓練而取得的,每一個新分類器都在已訓練出的分類器的性能基礎上再進行訓練,通過集中關注被已有分類器錯分的些數據來取得新的分類器。Boosting分類的結果是基于所有分類器的加權求和結果的,分類器權重其實不相等,每一個權重代表的是其對應分類器在上1輪迭代中的成功度。Boosting算法有很多種,AdaBoost(Adaptive Boost)就是其中最流行的,與SVM分類并稱機器學習中最強大的學習算法。
AdaBoost 是1種迭代算法,其核心思想是針對同1個訓練集訓練M個弱分類器,每一個弱分類器賦予不同的權重,然后把這些弱分類器集合起來而構造1個更強的終究分類器,本文就詳解AdaBoost算法的詳細進程。
AdaBoost算法有AdaBoost.M1和AdaBoost.M2兩種算法,AdaBoost.M1是我們通常所說的Discrete AdaBoost,而AdaBoost.M2是M1的泛化情勢。關于AdaBoost算法的1個結論是:當弱分類器算法使用簡單的分類方法時,boosting的效果明顯地統1地比bagging要好.當弱分類器算法使用C4.5時,boosting比bagging較好,但是沒有前者明顯。后來又有學者提出了解決多標簽問題的AdaBoost.MH和AdaBoost.MR算法,其中AdaBoost.MH算法的1種情勢又被稱為Real Boost算法---弱分類器輸出1個可能度,該值的范圍是全部R, 和與之相應的權值調劑,強分類器生成的AdaBoost算法。
事實上:Discrete AdaBoost是指,弱分類器的輸出值限定在{⑴,+1},和與之相應的權值調劑,強分類器生成的AdaBoost算法。本文就詳解該2分類的AdaBoost算法,其他請參考‘Adaboost原理、算法和利用’。
假定是2值分類問題,X表示樣本空間,Y={⑴,+1}表示樣本分類。令S={(Xi,yi)|i=1,2,…,m}為樣本訓練集,其中Xi∈X,yi∈Y。再次重申,我們假定統計樣本的散布式是均勻散布的,如此在兩分類分類中(種別⑴或1)可以將閾值設為0。實際訓練數據中,樣本常常是不均衡的,需要算法來選擇最優閾值(如ROC曲線)。AdaBoost算法就是學習出1個分類器YM(x) --由M個弱分類器構成。在進行分類的時候,將新的數據點x代入,如果YM(x)小于0則將x的種別賦為⑴,如果YM(x)大于0則將x的種別賦為1。均勻散布中閾值就是0,非均衡散布則還要根據ROC曲線等方法肯定1個分類的最優閾值。

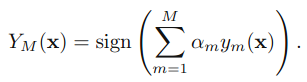
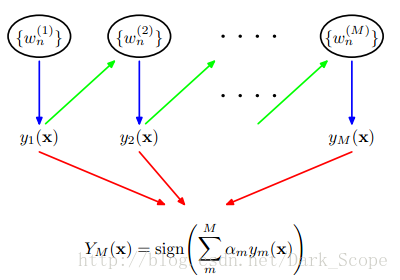

基本進程:針對不同的訓練集訓練1個個基本分類器(弱分類器),然后集成而構成1個更強的終究的分類器(強分類器)。不同的訓練集是通過調劑訓練數據中每一個樣本對應的權重實現的。每次訓練后根據此次訓練集中的每一個樣本是不是被分類正確和上次的整體分類的準確率,來肯定每一個樣本的權值。將修改權值的新數據送給下層分類器進行訓練,然后將每次訓練得到的分類器融會起來,作為最后的決策分類器。
每一個弱分類器可以是機器學習算法中的任何1個,如logistic回歸,SVM,決策樹等。
Adaboost有很多優點:
1)adaboost是1種有很高精度的分類器
2)可使用各種方法構建子分類器,adaboost算法提供的是框架
3)當使用簡單分類器時,計算出的結果是可以理解的,而且弱分類器構造極為簡單
4)簡單,不用做特點挑選
5)不用擔心overfitting
完全的adaboost算法以下(訓練樣本樣本總數是N個,M是迭代停止后(積累毛病率為0或到達最大迭代次數)得到弱分類器數目)。
給定1個訓練數據集T={(x1,y1), (x2,y2)…(xN,yN)},其中實例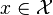 ,而實例空間
,而實例空間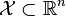 ,yi屬于標記集合{⑴,+1},Adaboost的目的就是從訓練數據中學習1系列弱分類器或基本分類器,然后將這些弱分類器組合成1個強分類器,流程以下:
,yi屬于標記集合{⑴,+1},Adaboost的目的就是從訓練數據中學習1系列弱分類器或基本分類器,然后將這些弱分類器組合成1個強分類器,流程以下:
最開始的時候,每一個樣本對應的權重是相同的(1/m),在此樣本散布下訓練出1個基本分類器h1(x)。對h1(x)錯分的樣本,則增加其對應樣本的權重;而對正確分類的樣本,則下降其權重。這樣可使得錯分的樣本突出出來,并得到1個新的樣本散布。同時,根據錯分的情況賦予h1(x)1個權重,表示該基本分類器的重要程度,錯分得越少權重越大。在新的樣本散布下,再次對基本分類器進行訓練,得到基本分類器h2(x)及其權重。順次類推,經過M次這樣的循環,就得到了M個基本分類器及對應權重。最后把這M個基本分類器按1定權重累加起來,就得到了終究所期望的強分類器YM(x)。迭代的停止條件就是到達了訓練樣本累加分類毛病率為0.0或到達了最大迭代次數。
(i)初始化訓練數據的權值散布,每個訓練樣本最開始時被賦予相同的權值:1/N。
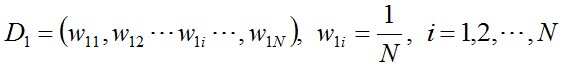
(ii)進行多輪迭代,迭代的停止條件就是到達了訓練樣本累加分類毛病率為0.0或到達了最大迭代次數L。用m = 1,2, ..., M表示迭代的第多少輪,也就是得到了多少個弱分類器,M<=L。
a.使用具有權值散布Dm的訓練數據集學習,得到基本分類器:
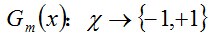

b.計算Gm(x)在訓練數據集上的分類誤差率
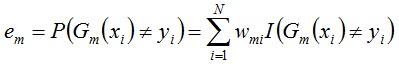

由上述式子可知,Gm(x)在訓練數據集上的誤差率em就是被弱分類器Gm(x)分類毛病樣本的權值之和。就是在這里,訓練樣本權重因子產生了作用,所有的1切都指向了當前弱分類器的誤差。提高分類毛病樣本的權值,下1個分類器學習中其“地位”就提高了(以單層決策樹為例,由于每次都要得到當前訓練樣本中em最小的決策樁);同時若這次的弱分類器再次分錯了這些點,那末其毛病率em也就更大,終究致使這個分類器在全部混合分類器的權值am變低---讓優秀的分類器占整體的權值更高,而挫的分類器權值更低。
c. 計算Gm(x)的權值系數,am表示Gm(x)在終究分類器中的重要程度(目的:得到基本分類器在終究分類器中所占的權重):
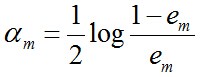

可知:em <= 1/2時(兩分類Adaboost算法em不可能大于1/2),am >= 0;am隨著em的減小而增大,意味著分類誤差率越小的本分類器在終究分類器中的作用越大。
另外,若某1個若分類器分類毛病率為0計算am將會產生除數為0的異常,這屬于邊界處理。此時可以根據數據集的具體情況設定毛病率為1個很小的數值,例如1e⑴6。視察樣本權重更新就能夠知道:沒有錯分,所有樣本的權重就不會進1步調劑,樣本權重相當于沒有改變。固然,該弱分類器權重alpha將較大,但是由于算法其實不因此停止,如果后面還有其他弱分類器也能到達訓練毛病率為0,也一樣會有較大的權重,從而避免由單個弱分類器完全決定強分類器的情況。固然,如果第1個弱分類器毛病率就為0,那末全部分類就完成了,它有再大的權重alpha也無妨。采取下述修正方案:
alpha = float(0.5*log((1.0-error)/max(error,1e⑴6) ))
d. 更新訓練數據集的權值散布(目的:得到樣本的新的權值散布),用于下1輪迭代。這使得被基本分類器Gm(x)分類毛病的樣本的權值增大,而被正確分類樣本的權值減小。通過這樣的方式,AdaBoost算法提高了較難分類的樣本的‘地位’。
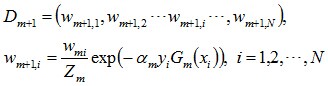

Zm的意義在于讓權重因子之和為1.0,使向量D是1個幾率散布向量。其定義是
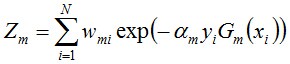

(iii) 組合各個弱分類器得到終究分類器,以下:
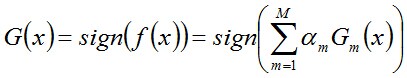

單層決策樹(decision stump,也叫決策樹樁)是1種簡單的決策樹,決策樹中只有1個樹樁,也就是僅基于樣本單個特點來做決策分類。單層決策樹是AdaBoost算法中最流行的弱分類器。
AdaBoost把多個不同的決策樹用1種非隨機的方式組合起來,表現出驚人的性能。第1,把決策樹的準確率大大提高,可以與SVM媲美。第2,速度快,且基本不用調參數。第3,幾近不Overfitting。本節就以多個單層決策樹做基本分類器實現AdaBoost算法,值得注意的是每一個基本分類器單層決策樹決策用分類使用的特點都是在樣本N個特點中做最優選擇的(也就是說在分類特點選擇這個層面,每一個單層決策樹彼此之間是完全獨立的,可能若干個單層決策樹都是基于同1個樣本特點),而非樣本特點的串連。
該版本的AdaBoost分類算法包括decisionstump.py(decisionstump對象,其屬性是包括dim, thresh, ineqtype3個域的決策樹樁,方法有buildstump()、stumpClassify()等。),adaboost.py, object_json.py, test.py,其中adaboot.py實現分類算法,對象adaBoost包括屬性分類器詞典adaboostClassifierDict和adaboost train&classify方法等。為了存儲和傳輸更少的字節數,也能夠在adaboost模塊增加1個新類adaboostClassifier只用來存儲分類詞典和分類算法(本包中沒有這么做)。test模塊則包括了1個使用adaboost分類器進行分類的示例。
由于adaboost算法每個基本分類器都可以采取任何1種分類算法,因此通用的方案是采取dict來存儲學習到的AdaBoost分類器,結構以下圖:
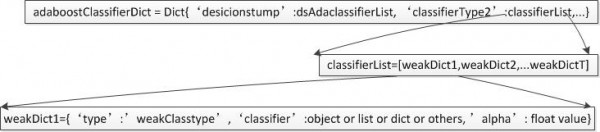
adaboost對象可以針對決策樹、SVM等定義私有的各種弱分類算法,train和classifier方法則會根據當前的弱分類器類型創建響應的弱分類器實例并調用私有弱分類trainclassifer方法完成trainclassify。需要記住的是,adaboost train方法創建的弱分類器對象只用來調用相應的弱分類器方法,而該弱分類實例所有的屬性則存儲在adaboostClassifierDict中,這樣可以減少弱分類器實例數目。另外,方法jsonDumpsTransfer()和jsonLoadTransfer()則要根據adaboostClassifierDict中支持的弱分類器類型刪除創建相應實例,從而支持JSON存儲和解析。
采取上圖中的分類器存儲方案及相應的分類函數,AdaBoost支持每個基本分類器在決策樹、貝葉斯、SVM等監督學習算法中做最優選擇。分類其中adaboostClassifierDict中的classifierType用戶可以自己指定,從而在上述分類存儲結構的基礎上做1些利于分類器程序編寫的調劑。我實現的單層決策樹Adaboost指定classifierType為desicionstump,即基本分類器采取desicionstump,每個弱分類器都是1個DS對象。所以存儲結構可以調劑為下圖所示(利于分類函數實現):


通過調劑adaboost算法弱分類器的數目,會得到分類毛病率不同的adaboost分類器。測試證明,numIt=50時毛病率最低。
AdaBoost分類算法學習包的下載地址是:
由于adaboost算法是1種實現簡單、利用也很簡單的算法,應當說是1種很合適于在各種分類場景下利用的算法。adaboost算法的1些實際可使用的場景:
1)用于2分類或多分類的利用場景
2)用于做分類任務的baseline--無腦化,簡單,不會overfitting,不用調分類器
3)用于特點選擇(feature selection)
4)Boosting框架用于對badcase的修正--只需要增加新的分類器,不需要變動原有分類器
參考:
AdaBoost--從原理到實現
Adaboost 算法的原理與推導

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


