
RDD的核心方法:


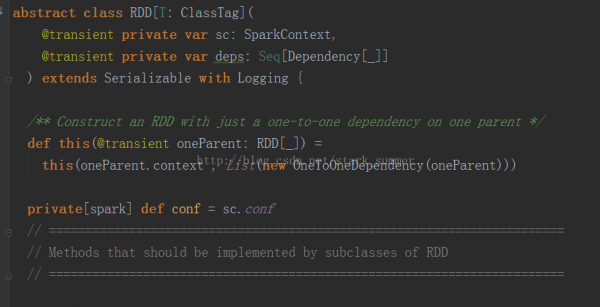
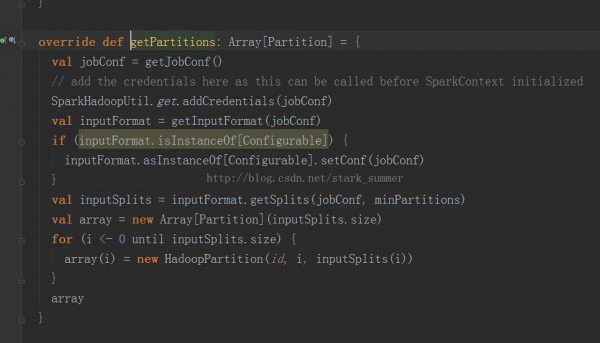
首先看1下getPartitions方法的源碼:

getPartitions返回的是1系列partitions的集合,即1個Partition類型的數組
我們就想進入HadoopRDD實現:
1、getJobConf():用來獲得job Configuration,獲得配置方式有clone和非clone方式,但是clone方式 是not thread-safe,默許是制止的,非clone方式可以從cache中獲得,如cache中沒有那就創建1個新的,然后再放到cache中
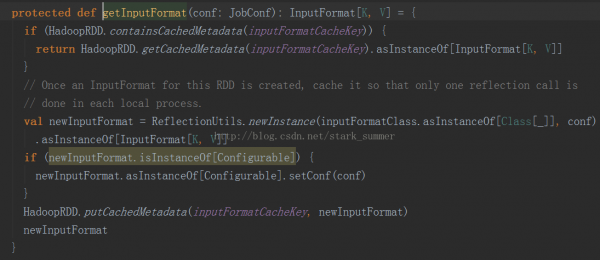
2、進入 getInputFormcat(jobConf)方法:
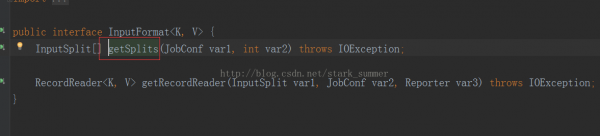
3、進入inputFormat.getSplits(jobConf, minPartitions)方法:
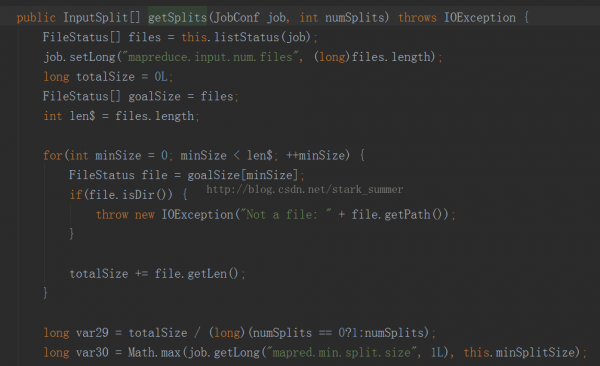
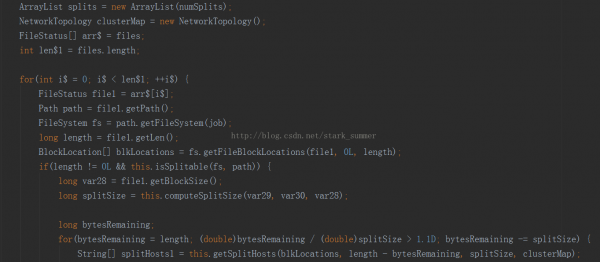
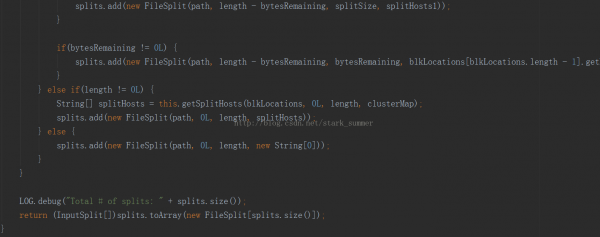
進入FileInputFormcat類的getSplits方法:
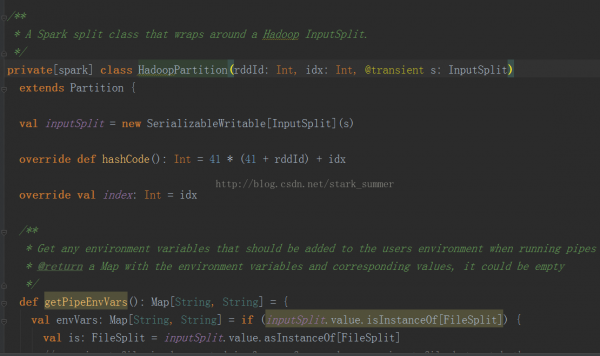
5、進入HadoopPartition:
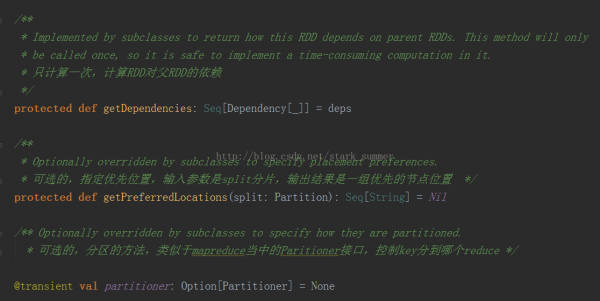
而getDependencies表達是RDD之間的依賴關系,以下所示:
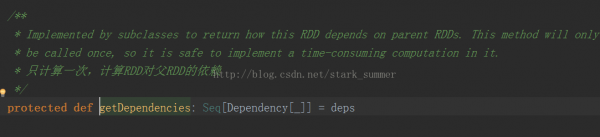
getDependencies返回的是依賴關系的1個Seq集合,里面的Dependency數組中的下劃線是類型的PlaceHolder
我們進入ShuffledRDD類中的getDependencies方法:

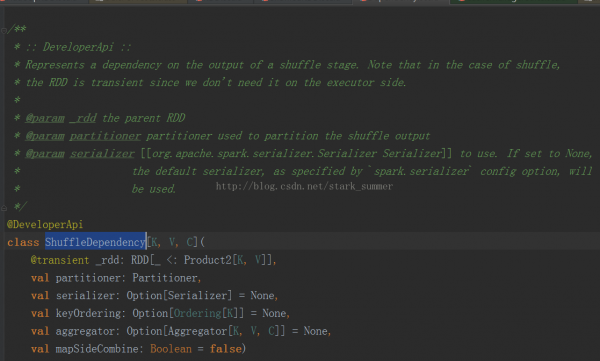
我們進入ShuffleDependency類:
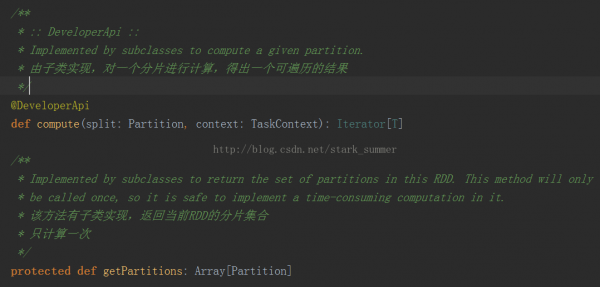
每一個RDD都會具有計算的函數,以下所示:
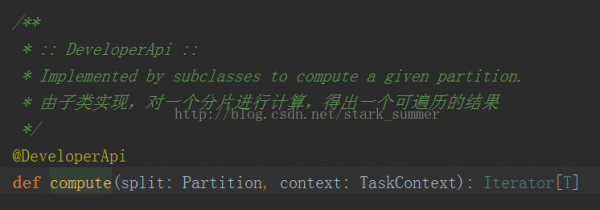
我們進入HadoopMapPartitionsWithSplitRDD的 compute方法:
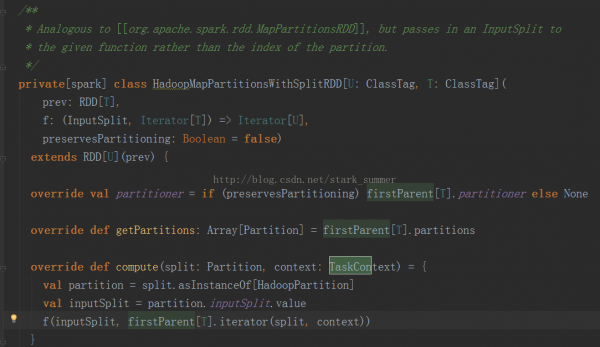
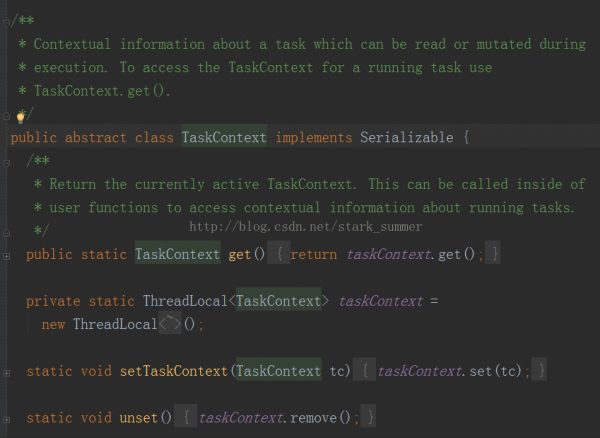
Compute方法是針對RDD的每一個Partition進行計算的,其TaskContext參數的源碼以下:
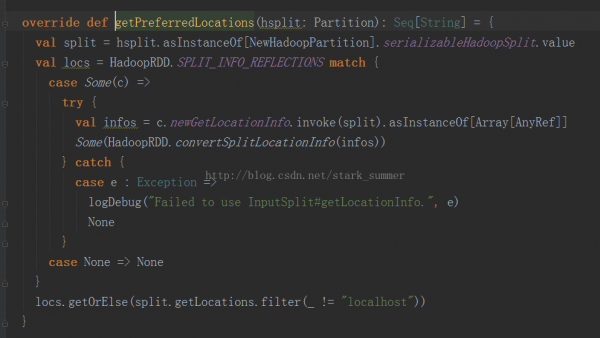
getPreferredLocations是尋覓Partition的首選位置:

我們進入NewHadoopRDD的getPreferredLocations:
其實RDD還有1個可選的分區策略:

Partitioner的源碼以下:
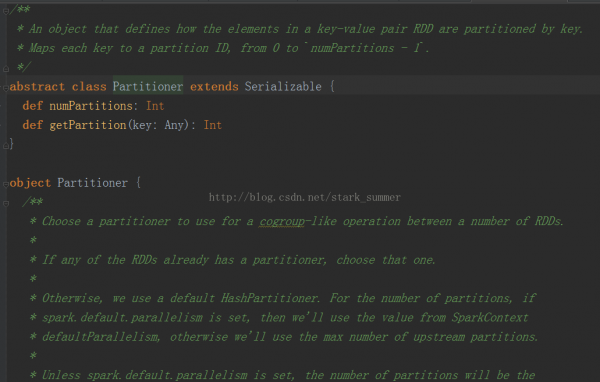
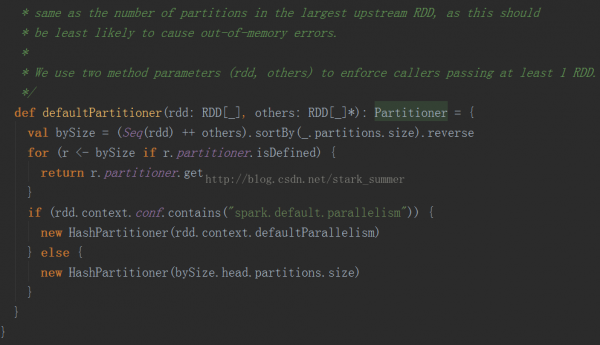
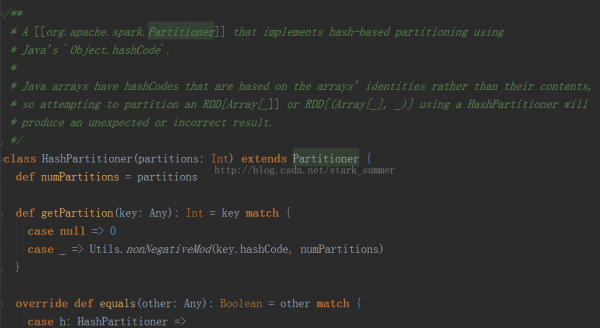
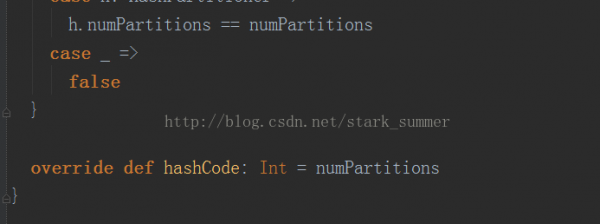
可以看出默許使用的是HashPartitioner,要注意key為Array的情況;
spark.default.parallelism必須要設置,否則會根據partitions數據來傳輸RDD,這樣也會很容易出現OOM

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


