
本講內容:
a. Receiver啟動的方式假想
b. Receiver啟動源碼完全分析
注:本講內容基于Spark 1.6.1版本(在2016年5月來講是Spark最新版本)講授。
上節回顧
上1講中,我們給大家具體分析了RDD的物理生成和邏輯生成進程,完全明白DStream和RDD之間的關系,及其內部其他有關類的具體依賴等信息:
a. DStream是RDD的模板,其內部generatedRDDs 保存了每一個BatchDuration時間生成的RDD對象實例。DStream的依賴構成了RDD依賴關系,即從后往前計算時,只要對最后1個DStream計算便可。
b. JobGenerator每隔BatchDuration調用DStreamGraph的generateJobs方法,調用了ForEachDStream的generateJob方法,其內部先調用父DStream的getOrCompute方法來獲得RDD,然后在進行計算,從后往前推,第1個DStream是ReceiverInputDStream,其comput方法中從receiverTracker中獲得對應時間段的metadata信息,然后生成BlockRDD對象,并放入到generatedRDDs中
開講
由上幾節課中我們知道:
a. Spark Streaming的利用程序在處理數據時,會在開始的階段做好接收數據的準備
b. Spark Streaming的利用程序代碼定義DStream時,會定義1個或多個InputDStream;而每一個InputDStream則分別對應有1個Receiver
結合源碼的具體類和方法繪制Receiver啟動全生命周期主流程圖:
(原圖信息來自http://blog.csdn.net/andyshar/article/details/51476113,感謝作者!)
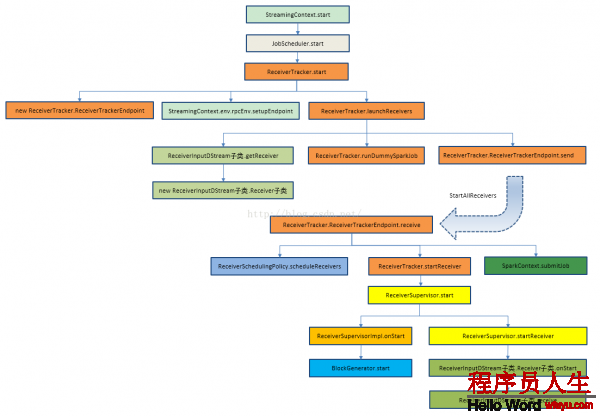
我們就從本講的內容開始,為大家解析:
那末Receiver啟動的方式假想究竟是甚么呢?
Receiver啟動的設計問題分析:
a. Spark Streaming通過Receiver延續不斷的從外部數據源接收數據,并把數據匯報給Driver端,由此每一個Batch Durations就能夠根據匯報的數據生成不同的Job
b. 即有可能在同1個Executor當中啟動多個Receiver,這類情況之下致使負載不均勻
c. 由于Executor運行本身的故障,task 有可能啟動失敗,全部job啟動就失敗,即receiver啟動失敗
d. Receiver屬于Spark Streaming利用程序啟動階段,它又是如何設計,來到達Receiver始終會被啟動
e. Receivers和InputDStreams又是如何逐一對應的,默許情況下1般只有1個Receiver嗎?
來吧,走進源碼1起看個究竟!!
Receiver啟動源碼完全分析:
如何啟動Receiver?
a. 從Spark Core的角度來看,Receiver的啟動Spark Core其實不知道, Receiver是通過Job的方式啟動的,運行在Executor之上的,由task運行
b. 1般情況下,只有1個Receiver,但是可以創建不同的數據來源的InputDStream
c. 啟動Receiver的時候,實際上1個receiver就是1個partition,并由1個Job啟動,這個Job里面有RDD的transformations操作和action的操作,隨著定時器觸發,不斷的產生有數據接收,每一個時間段中產生的接收數據實際上就是1個partition
如此,又回到了最初Receiver啟動的方式假想中的問題:
a. 如果有多個InputDStream,那就要啟動多個Receiver,每一個Receiver也就相當于分片partition,那我啟動Receiver的時候理想的情況下是在不同的機器上啟動Receiver,但是Spark Core的角度來看就是利用程序,感覺不到Receiver的特殊性,所以就會依照正常的Job啟動的方式來處理,極有可能在1個Executor上啟動多個Receiver;這樣的話便可能致使負載不均衡
b. 有可能啟動Receiver失敗,只要集群存在,Receiver就不應當啟動失敗
c. 從運行進程中看,1個Reveiver就是1個partition的話,Reveiver的啟動伴隨1個Task啟動,如果Task啟動失敗,以Task啟動的Receiver也會失敗
由此,可以得出,對Receiver失敗的話,后果是非常嚴重的,那末在Spark Streaming如何避免這些事的呢?
Spark Streaming源碼分析,在Spark Streaming當中就指定以下信息:
a. Spark使用1個Job啟動1個Receiver.最大程度的保證了負載均衡
b. Spark Streaming已指定每一個Receiver運行在那些Executor上,在Receiver運行之前就指定了運行的地方
c. 如果Receiver啟動失敗,此時其實不是Job失敗,在內部會重新啟動Receiver
進入到StreamingContext源碼,開啟解密之旅吧!
在StreamingContext的start方法被調用的時候,JobScheduler的start方法會被調用
scheduler.start()://啟動子線程,1方面為了本地初始化工作,另外1方面是不要阻塞主線程
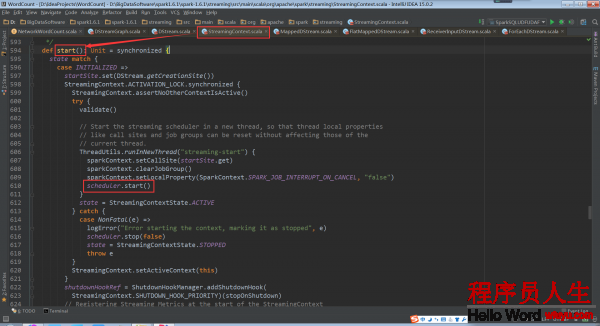
而在JobScheduler的start方法中ReceiverTracker的start方法被調用,Receiver就啟動了
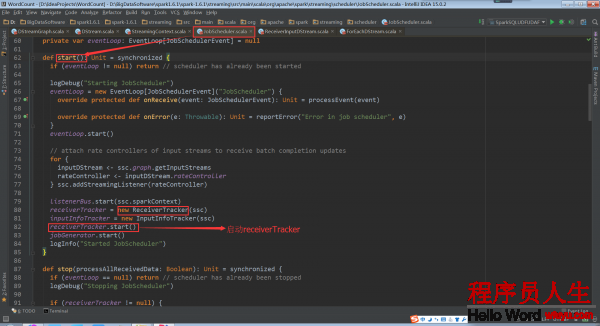
ReceiverTracker的start方法啟動RPC消息通訊體,為啥呢?由于receiverTracker會監控全部集群中的Receiver,Receiver轉過來要向ReceiverTrackerEndpoint匯報自己的狀態,接收的數據,包括生命周期等信息
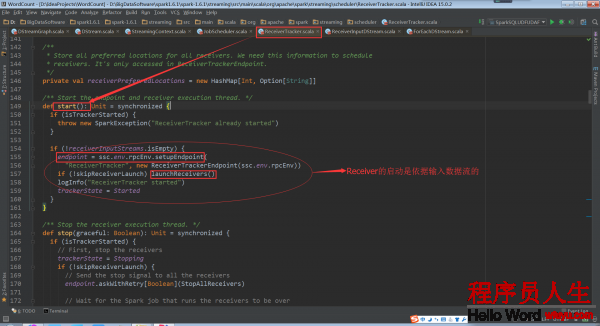
基于ReceiverInputDStream(是在Driver端)來取得具體的Receivers實例,然后再把他們散布到Worker節點上。1個ReceiverInputDStream只對應1個Receiver
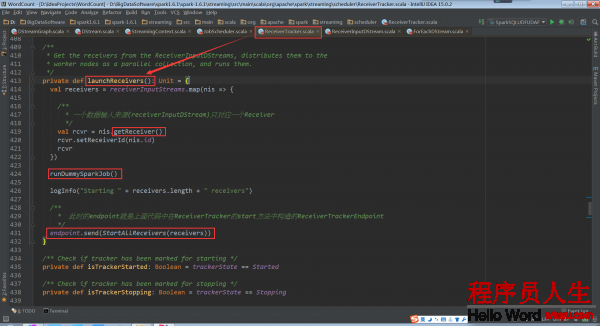
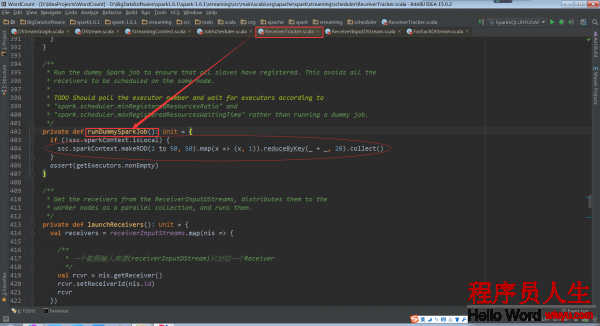
其中runDummySparkJob()為了確保所有節點活著,而且避免所有的receivers集中在1個節點上
再回去看ReceiverTracker.launchReceivers()中的getReceiver()
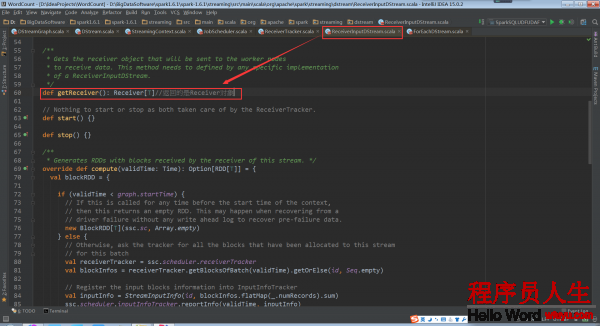
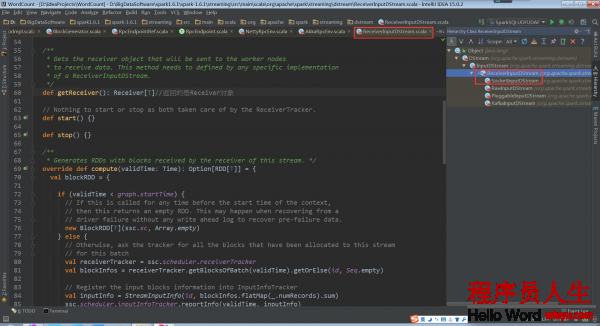
ReceiverInputDStream的getReceiver()方法返回Receiver對象。 該方法實際上要在ReceiverInputDStream的子類實現。
相應的,ReceiverInputDStream的子類中必須要實現這個getReceiver()方法。ReceiverInputDStream的子類還必須定義自己對應的Receiver子類,由于這個Receiver子類會在getReceiver()方法中用來創建這個Receiver子類的對象。
因此,我們需要查看以下ReceiverInputDStream的繼承關系
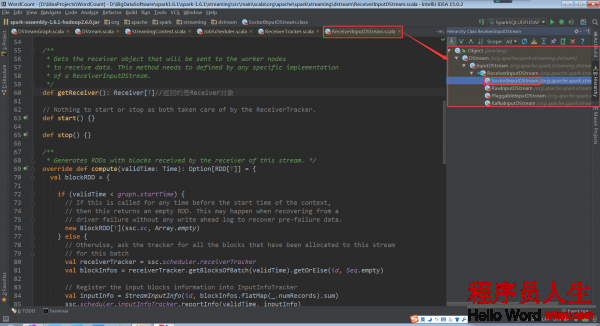
根據繼承關系,這里看1下ReceiverInputDStream的子類SocketInputDStream中的getReceiver方法
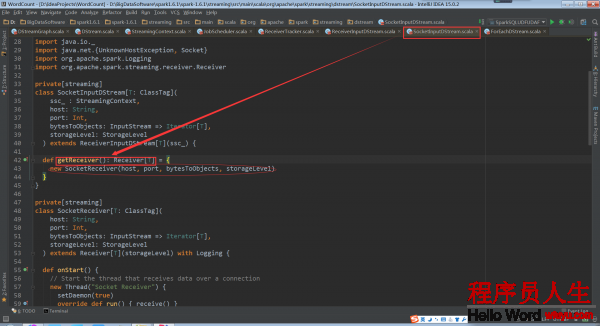
SocketInputDStream中還定義了相應的Receiver子類SocketReceiver。SocketReceiver類中還必須定義onStart方法
onStart方法會啟動后臺線程,調用receive方法
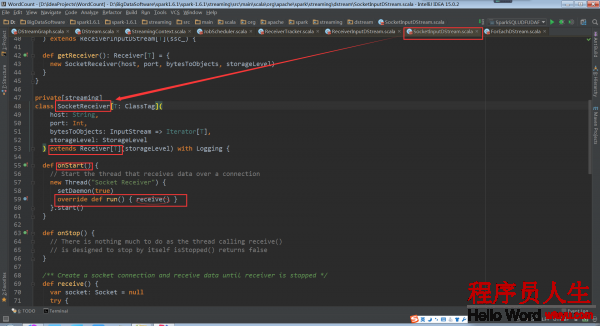
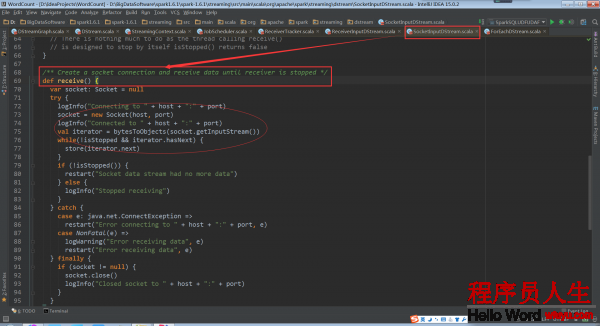
啟動socket開始接收數據
再回到ReceiverTracker.launchReceivers()中,看最后的代碼 endpoint.send(StartAllReceivers(receivers))。這個代碼給ReceiverTrackerEndpoint對象發送了StartAllReceivers消息,ReceiverTrackerEndpoint對象接收后所做的處理在ReceiverTrackerEndpoint.receive中。
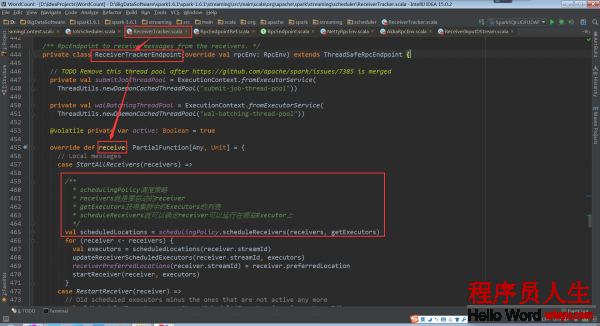
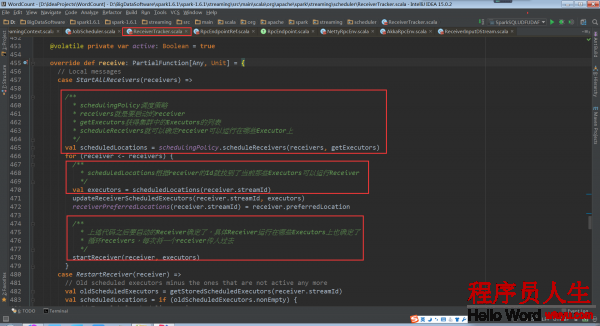
從注釋中可以看到,Spark Streaming指定receiver在哪些Executors上運行,而不是基于Spark Core中的Task來指定
Spark使用submitJob的方式啟動Receiver,而在利用程序履行的時候會有很多Receiver,這個時候是啟動1個Receiver呢,還是把所有的Receiver通過這1個Job啟動?
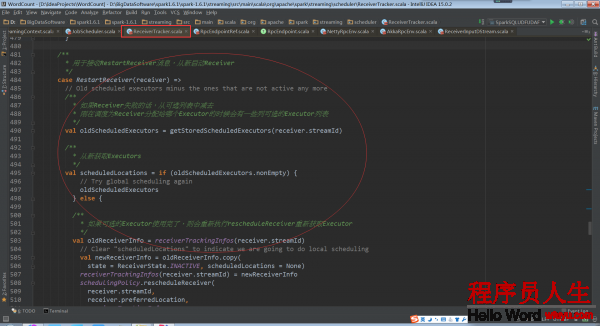
在ReceiverTracker的receive方法中startReceiver方法第1個參數就是receiver,從實現中可以看出for循環不斷取出receiver,然后調用startReceiver。由此就能夠得出1個Job只啟動1個Receiver
如果Receiver啟動失敗,此時其實不會認為是作業失敗,會重新發消息給ReceiverTrackerEndpoint重新啟動Receiver,這樣也就確保了Receivers1定會被啟動,這樣就不會像Task啟動Receiver的話如果失敗受重試次數的影響。
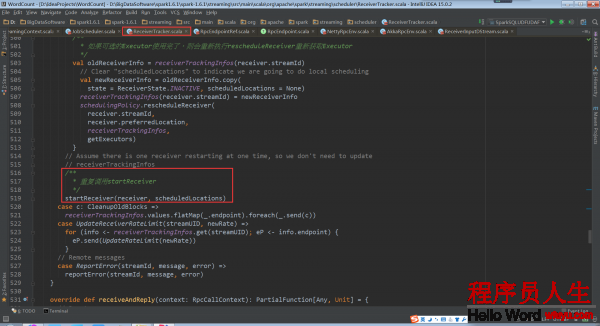
ReceiverTracker.startReceiver:
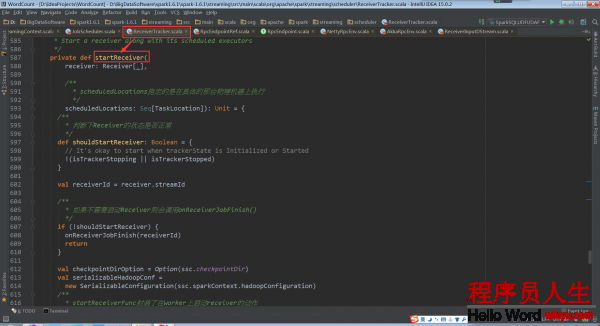
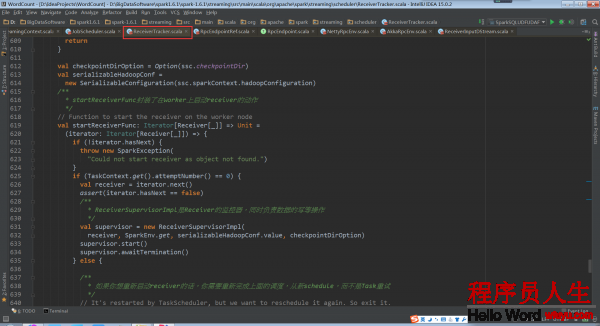
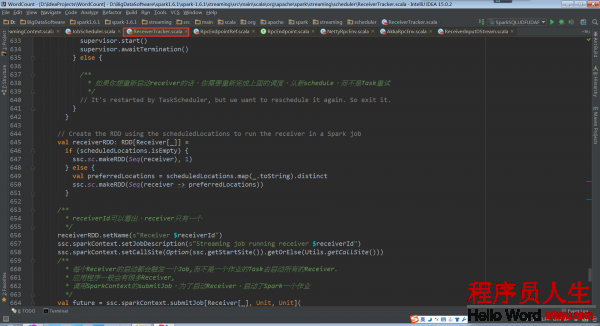
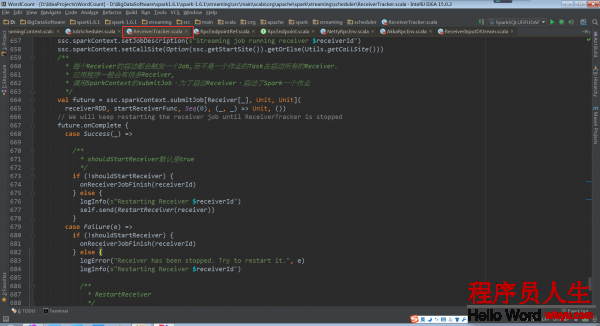
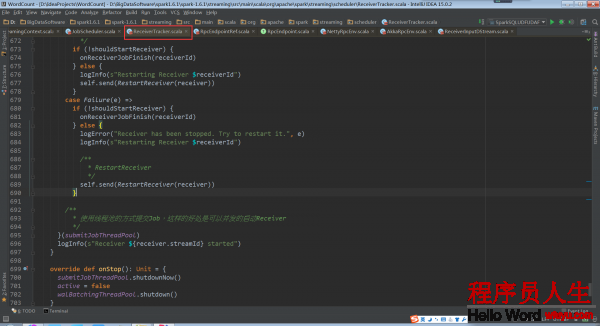
當Receiver啟動失敗的話,就會觸發ReceiverTrackEndpoint重新啟動1個Spark Job去啟動Receiver
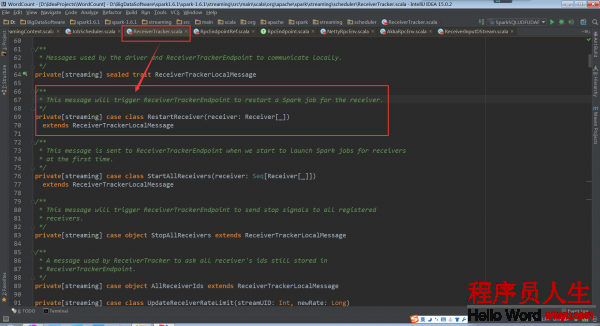
當Receiver關閉的話,其實不需要重新啟動Spark Job
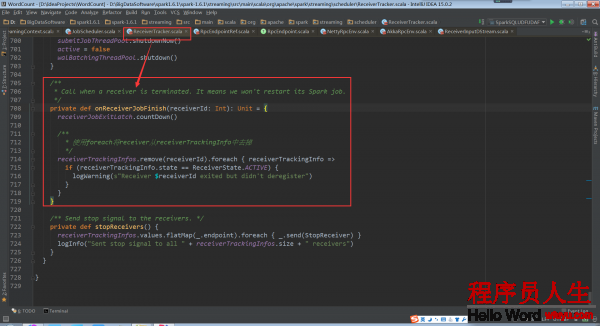
回頭再看ReceiverTracker.startReceiver中的代碼supervisor.start()。在子類ReceiverSupervisorImpl中并沒有start方法,因此調用的是父類ReceiverSupervisor的start方法。
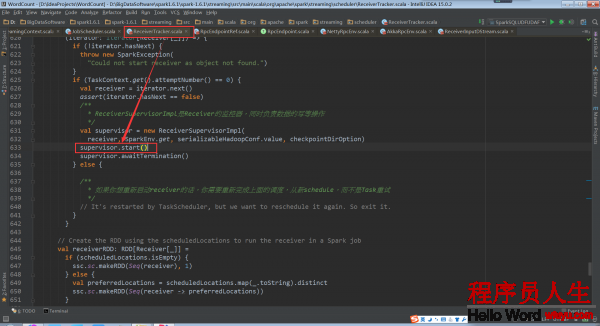
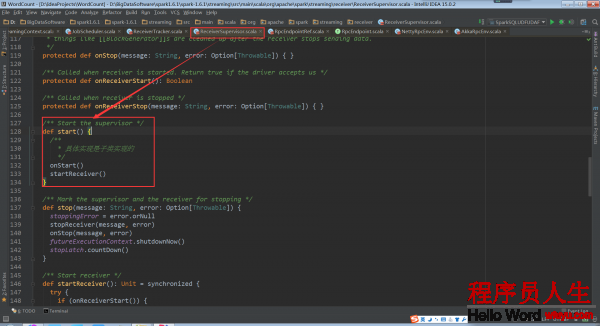
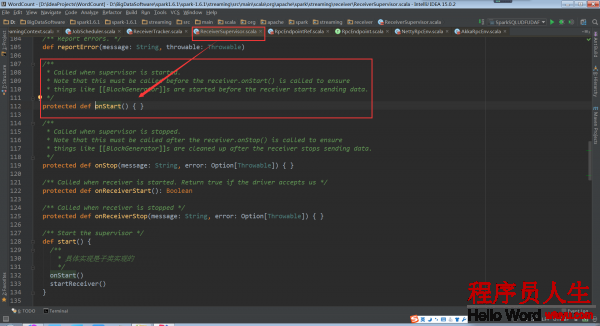
其具體實現是在子類的ReceiverSupervisorImpl的onStart方法:
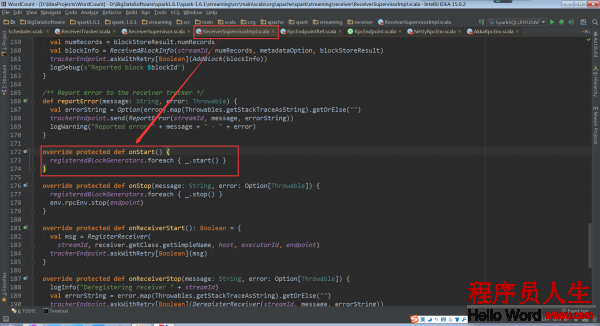
其中的_.start()是BlockGenerator.start:
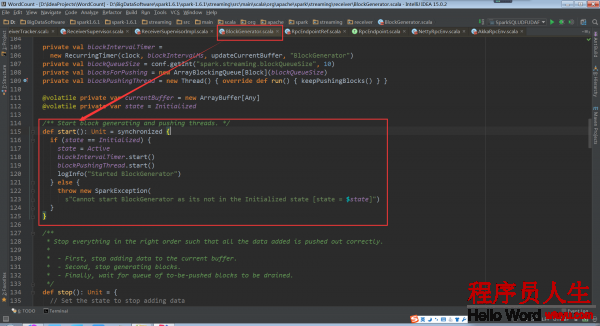
回過頭再看ReceiverSupervisor.start中的startReceiver()
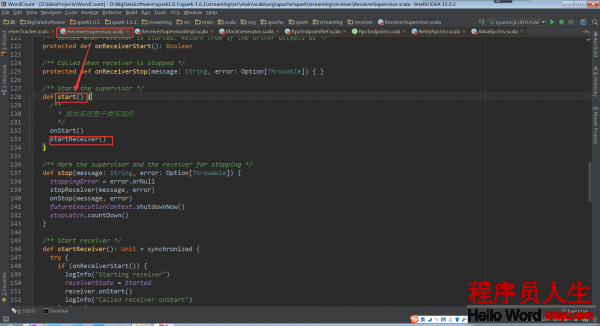
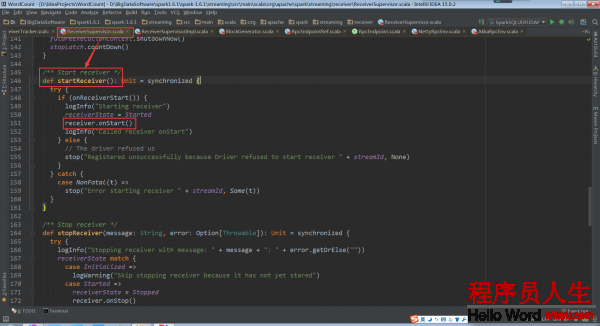
仍以Receiver的子類SocketReceiver為例說明onStart方法
SocketReceiver.onStart:
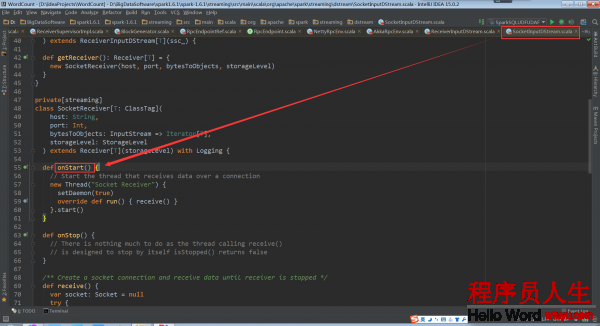
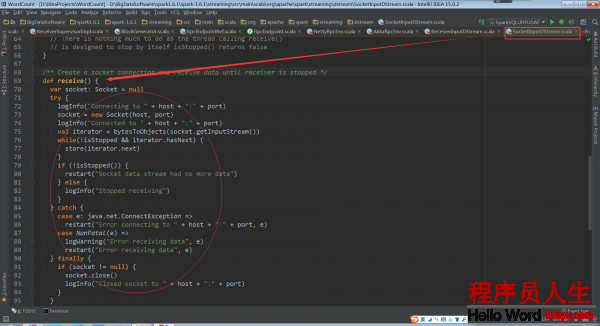
這個onStart方法開啟了的線程,用于啟動socket來接收數據。這個被運行的receive()被定義在ReceiverInputDStream的子類SocketInputDStream中
備注:
1、DT大數據夢工廠微信公眾號DT_Spark
2、Spark大神級專家:王家林
3、新浪微博: http://www.weibo.com/ilovepains

下一篇 Spring(一)
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


