《hadoop進階》PeopleRank從社交關系中挖掘價值用戶
來源:程序員人生 發布時間:2016-06-07 16:16:59 閱讀次數:4433次
轉載請注明出處: 轉載自 Thinkgamer的CSDN博客: blog.csdn.net/gamer_gyt
代碼下載地址:點擊查看
pagerank算法的python實現請參考:http://blog.csdn.net/gamer_gyt/article/details/47443877
pagerank算法的mapreduce實現請參考:http://blog.csdn.net/gamer_gyt/article/details/47451021
1:PageRank 與 PeopleRank
2:需求分析:發掘CSDN博客的價值用戶
3:算法模型:PeopleRank算法
4:架構設計:從數據準備到PR算法的MR化
5:程序開發:hadoop實現PeopleRank算法
1:PageRank與PeopleRank
PageRank算法是Google從垃圾堆里撿黃金的重量級算法,它讓谷歌的搜索引擎1度成為No.1,固然谷歌所公然的PR算法畢竟是過去式了,既然它能公然,那末肯定不是它最新的算法演變版本,但是不管怎樣,我們照舊從中學習到很多創新和獨特的思想。
PR算法主要用于網頁評分計算,它利用互聯網的網頁之間的連接關系,給網頁進行打分,終究PR值越高的網頁價值也就越高。
自2012以來,中國開始進入社交網絡的時期,開心網,人人網,新浪微博,騰訊微博,微信等社交網絡利用,開始進入大家的生活。最早是由“搶車位”,“偷菜”等社交游戲帶動的社交網絡的興起,如今人們會更多的利用社交網絡,獲得信息和分享信息。我們的互聯網,正在從以網頁信息為核心的網絡,向著以人為核心的網絡轉變著。
因而有人就提出了,把PageRank模型利用于社交網絡,定義以人為核心的個體價值。這樣PageRank模型就有了新的利用領域,同時也有了1個新的名字PeopleRank。
2 . 需求分析:發掘CSDN博客的價值用戶
如上圖所示,CSDN博客的每一個用戶都有關注人數和粉絲人數,這在1定程度上和網頁之間的連接關系是10分相似的,我個人比較菜,粉絲數太少,固然我希望看過我博客的人,如果你感覺不錯的話是不是可以關注以下呢,閑話少說,這類相互關注的關系在1定程度上體現了用戶的價值,粉絲數目越多的人,在1定程度上,其本身所具有的重要性。
順便給大家看1個CSDN排名47的牛人
這恰好符合PR算法,我們是不是可以斟酌使用PeopleRank算法,利用用戶之間的關注關系,來計算不同用戶的PR值,從而提取出“價值”更高的用戶呢?答案是肯定的。
3 . 算法模型:PeopleRank算法
那末甚么是PageRank算法?固然本篇博客其實不是來談PR算法的,而是將如何利用hadoop實現pr算法從而發掘有價值的用戶,所以以下只是簡單的對pr算法的描寫,更多還請自己搜索查看(以下部份摘自:http://blog.jobbole.com/71431/)
互聯網中的網頁可以看出是1個有向圖,其中網頁是結點,如果網頁A有鏈接到網頁B,則存在1條有向邊A->B,下面是1個簡單的示例:
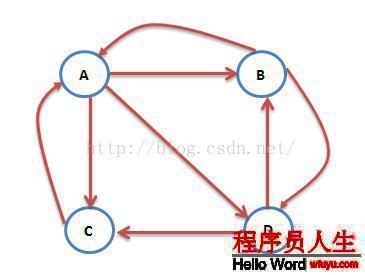
這個例子中只有4個網頁,如果當前在A網頁,那末悠閑的上網者將會各以1/3的幾率跳轉到B、C、D,這里的3表示A有3條出鏈,如果1個網頁有k條出鏈,那末跳轉任意1個出鏈上的幾率是1/k,同理D到B、C的幾率各為1/2,而B到C的幾率為0。1般用轉移矩陣表示上網者的跳轉幾率,如果用n表示網頁的數目,則轉移矩陣M是1個n*n的方陣;如果網頁j有k個出鏈,那末對每個出鏈指向的網頁i,有M[i][j]=1/k,而其他網頁的M[i][j]=0;上面示例圖對應的轉移矩陣以下:

初試時,假定上網者在每個網頁的幾率都是相等的,即1/n,因而初試的幾率散布就是1個所有值都為1/n的n維列向量V0,用V0去右乘轉移矩陣M,就得到了第1步以后上網者的幾率散布向量MV0,(nXn)*(nX1)仍然得到1個nX1的矩陣。下面是V1的計算進程:

注意矩陣M中M[i][j]不為0表示用1個鏈接從j指向i,M的第1行乘以V0,表示累加所有網頁到網頁A的幾率即得到9/24。得到了V1后,再用V1去右乘M得到V2,1直下去,終究V會收斂,即Vn=MV(n⑴),上面的圖示例,不斷的迭代,終究V=[3/9,2/9,2/9,2/9]’:

4 .架構設計:從數據準備到PR算法的MR化
這里我采取的是用戶和用戶之間的關注關系,例如 用戶A 關注 用戶B
1:數據收集
使用Python爬蟲收集CSDN博客的用戶和用戶的關注關系,這里我使用的收集程序架構圖以下:

由于我這個PR計算是我做的另外1個項目(博客統計分析系統:github地址 在線演示地址:點擊查看
該地址會在1定的時間內有效)的其中的1部份,所以數據也是從其中摘取的,本來的收集程序是為了收集所有CSDN博客用戶udell信息和博客內容的,固然由于各種關系,終究收集的用戶數量為7萬左右,終究收集到的數據格式以下:
用戶信息數據:
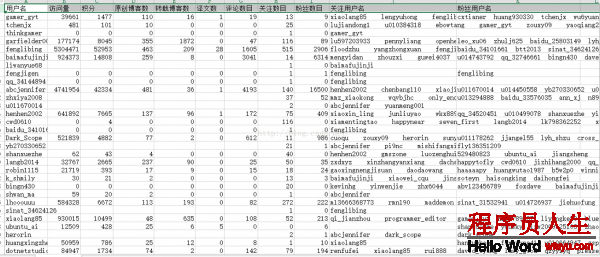
博客信息數據:
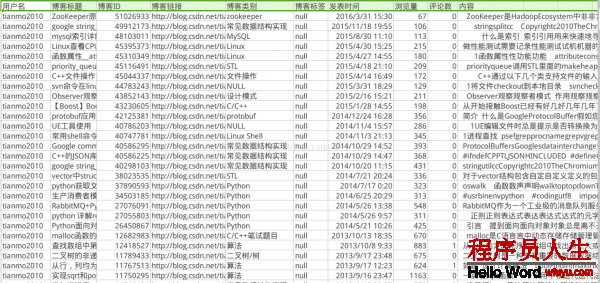
2:數據整理
我從中隨機抽取了100個用戶,同時利用1定的技術手段,給這個100個用戶之間賦予1定的關注關系,整理后的數據以下,主要包括兩部份,第1部份是用戶之間的關注關系(用戶id,關注的用戶id),第2是給每一個用戶賦予1定的初始值(用戶id,初始用戶pr值全部為1)
(1) 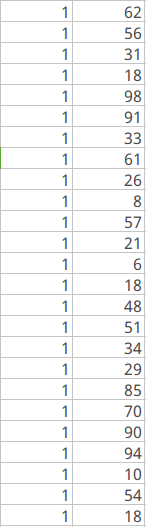 (2)
(2) 
3:PR算法的MR化設計
我么以下面這個圖來講1下
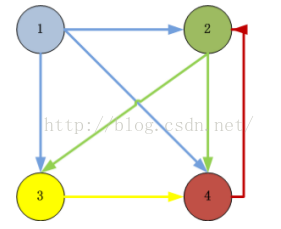
ID=1的頁面鏈向2,3,4頁面,所以1個用戶從ID=1的頁面跳轉到2,3,4的幾率各為1/3
ID=2的頁面鏈向3,4頁面,所以1個用戶從ID=2的頁面跳轉到3,4的幾率各為1/2
ID=3的頁面鏈向4頁面,所以1個用戶從ID=3的頁面跳轉到4的幾率各為1
ID=4的頁面鏈向2頁面,所以1個用戶從ID=4的頁面跳轉到2的幾率各為1
(1):構造鄰接矩陣

(2):構造鄰接矩陣

(3):轉換為幾率矩陣(轉移矩陣)
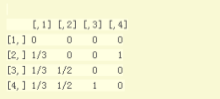
(4):阻尼系數幾率矩陣
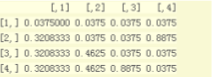
(5):進行迭代計算
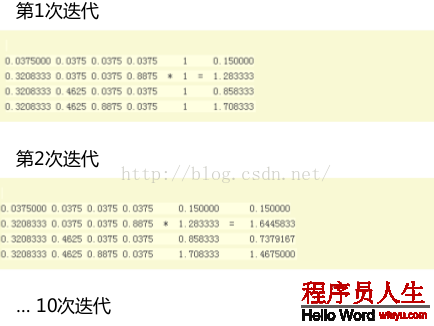
至于迭代的次數有自己設定,其實不是越多越好,根據6度分割理論來說,1般迭代6次
5 .
程序開發:hadoop實現PeopleRank算法
程序架構以下:
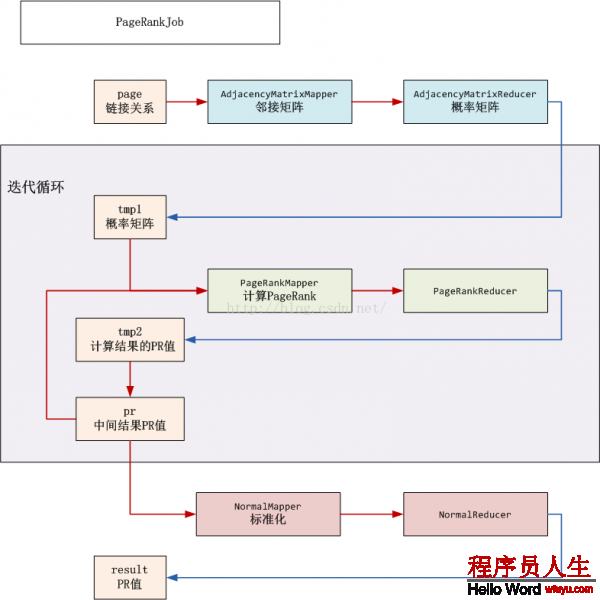
個人代碼目錄:
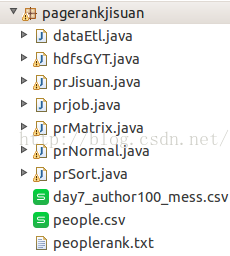
下面我們具體說1說每個文件是干甚么的
day7_author100_mess.csv:源文件,由dataEtl.java處理成我們所需要的數據格式
people.csv,peoplerank.txt :day7_author100_mess.csv處理后得到的文件
prjob.java:程序調度的主函數
prMatrix.java:數據轉換為矩陣情勢
prJisuan.java: 計算每一個用戶的PR值
prNormal.java:PR值的標準化
prSort.java:對轉化后的PR值進行排序
終究的輸出文件目錄
下面只對部份代碼進行展現,更多請前往github下載:點擊查看
dataEtl.java
package pagerankjisuan;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class dataEtl {
public static void main() throws IOException {
File f1 = new File("MyItems/pagerankjisuan/people.csv");
if(f1.isFile()){
f1.delete();
}
File f = new File("MyItems/pagerankjisuan/peoplerank.txt");
if(f.isFile()){
f.delete();
}
//打開文件
File file = new File("MyItems/pagerankjisuan/day7_author100_mess.csv");
//定義1個文件指針
BufferedReader reader = new BufferedReader(new FileReader(file));
try {
String line=null;
//判斷讀取的1行是不是為空
while( (line=reader.readLine()) != null)
{
String[] userMess = line.split( "," );
//第1字段為id,第是個字段為粉絲列表
String userid = userMess[0];
if(userMess.length!=0){
if(userMess.length==11)
{
int i=0;
String[] focusName = userMess[10].split("\\|"); // | 為轉義符
for (i=1;i < focusName.length; i++)
{
write(userid,focusName[i]);
// System.out.println(userid+ " " + focusName[i]);
}
}
else
{
int j =0;
String[] focusName = userMess[9].split("\\|"); // | 為轉義符
for (j=1;j < focusName.length; j++)
{
write(userid,focusName[j]);
// System.out.println(userid+ " " + focusName[j]);
}
}
}
}
}
catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
finally
{
reader.close();
//etl peoplerank.txt
for(int i=1;i<=100;i++){
FileWriter writer = new FileWriter("MyItems/pagerankjisuan/peoplerank.txt",true);
writer.write(i + "\t" + 1 + "\n");
writer.close();
}
}
System.out.println("OK..................");
}
private static void write(String userid, String nameid) {
// TODO Auto-generated method stub
//定義寫文件,按行寫入
try {
if(!nameid.contains("\n")){
FileWriter writer = new FileWriter("MyItems/pagerankjisuan/people.csv",true);
writer.write(userid + "," + nameid + "\n");
writer.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
prjob.java
package pagerankjisuan;
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
/*
* 調度函數
*/
public class prjob {
public static final String HDFS = "hdfs://127.0.0.1:9000";
public static void main(String[] args) {
Map <String, String> path= new HashMap<String, String>();
path.put("page" ,"/home/thinkgamer/MyCode/hadoop/MyItems/pagerankjisuan/people.csv");
path.put("pr" ,"/home/thinkgamer/MyCode/hadoop/MyItems/pagerankjisuan/peoplerank.txt");
path.put("input", HDFS + "/mr/blog_analysic_system/people"); // HDFS的目錄
path.put("input_pr", HDFS + "/mr/blog_analysic_system/pr"); // pr存儲目錄
path.put("tmp1", HDFS + "/mr/blog_analysic_system/tmp1"); // 臨時目錄,寄存鄰接矩陣
path.put("tmp2", HDFS + "/mr/blog_analysic_system/tmp2"); // 臨時目錄,計算到得PR,覆蓋input_pr
path.put("result", HDFS + "/mr/blog_analysic_system/result"); // 計算結果的PR
path.put("sort", HDFS + "/mr/blog_analysic_system/sort"); //終究排序輸出的結果
try {
dataEtl.main();
prMatrix.main(path);
int iter = 3; // 迭代次數
for (int i = 0; i < iter; i++) {
prJisuan.main(path);
}
prNormal.main(path);
prSort.main(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
public static String scaleFloat(float f) {// 保存6位小數
DecimalFormat df = new DecimalFormat("##0.000000");
return df.format(f);
}
}
prSort.java
package pagerankjisuan;
import java.io.IOException;
import java.net.URISyntaxException;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.IntWritable.Comparator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class prSort {
/**
* @param args
* @throws IOException
* @throws IllegalArgumentException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public static class myComparator extends Comparator {
@SuppressWarnings("rawtypes")
public int compare( WritableComparable a,WritableComparable b){
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
public static class sortMap extends Mapper<Object,Text,FloatWritable,IntWritable>{
public void map(Object key,Text value,Context context) throws NumberFormatException, IOException, InterruptedException{
String[] split = value.toString().split("\t");
context.write(new FloatWritable(Float.parseFloat(split[1])),new IntWritable(Integer.parseInt(split[0])) );
}
}
public static class Reduce extends Reducer<FloatWritable,IntWritable,IntWritable,FloatWritable>{
public void reduce(FloatWritable key,Iterable<IntWritable>values,Context context) throws IOException, InterruptedException{
for (IntWritable text : values) {
context.write( text,key);
}
}
}
public static void main(Map<String, String> path) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
String input = path.get("result");
String output = path.get("sort");
hdfsGYT hdfs = new hdfsGYT();
hdfs.rmr(output);
Job job = new Job();
job.setJarByClass(prSort.class);
// 1
FileInputFormat.setInputPaths(job, new Path(input) );
// 2
job.setMapperClass(sortMap.class);
job.setMapOutputKeyClass(FloatWritable.class);
job.setMapOutputValueClass(IntWritable.class);
// 3
// 4 自定義排序
job.setSortComparatorClass( myComparator.class);
// 5
job.setNumReduceTasks(1);
// 6
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(FloatWritable.class);
// 7
FileOutputFormat.setOutputPath(job, new Path(output));
// 8
System.exit(job.waitForCompletion(true)? 0 :1 );
}
}
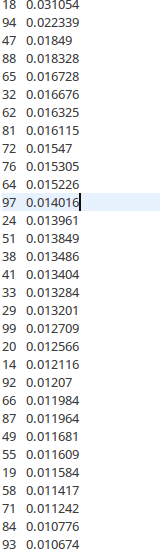
終究排序輸出的結果為:
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈




