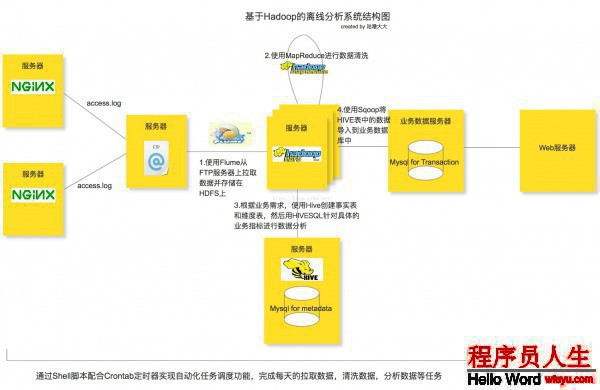
需要注意的是Flume的Source在本文的系統(tǒng)當(dāng)選擇的是Spooling
Directory Source,而沒有選擇Exec
Source,由于當(dāng)Flume服務(wù)down掉的時(shí)候Spooling
Directory Source能記錄上1次讀取到的位置,而Exec
Source則沒有,需要用戶自己去處理,當(dāng)重啟Flume服務(wù)器的時(shí)候如果處理不好就會(huì)有重復(fù)數(shù)據(jù)的問題。固然Spooling
Directory Source也是有缺點(diǎn)的,會(huì)對(duì)讀取過的文件重命名,所以多架1層FTP服務(wù)器也是為了不Flume“污染”生產(chǎn)環(huán)境。Spooling
Directory Source另外1個(gè)比較大的缺點(diǎn)就是沒法做到靈活監(jiān)聽某個(gè)文件夾底下所有子文件夾里的所有文件里新追加的內(nèi)容。關(guān)于這些問題的解決方案也有很多,比如選擇其它的日志收集工具,像logstash等。
FTP服務(wù)器上的Flume配置文件以下: agent.channels = memorychannel
agent.sinks = target
agent.sources.origin.type = spooldir
agent.sources.origin.spoolDir = /export/data/trivial/weblogs
agent.sources.origin.channels = memorychannel
agent.sources.origin.deserializer.maxLineLength = 2048
agent.sources.origin.interceptors = i2
agent.sources.origin.interceptors.i2.type = host
agent.sources.origin.interceptors.i2.hostHeader = hostname
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memorychannel
agent.channels.memorychannel.type = memory
agent.channels.memorychannel.capacity = 10000
agent.sinks.target.type = avro
agent.sinks.target.channel = memorychannel
agent.sinks.target.hostname = 172.16.124.130
agent.sinks.target.port = 4545
這里有幾個(gè)參數(shù)需要說明,Flume Agent Source可以通過配置deserializer.maxLineLength這個(gè)屬性來指定每一個(gè)Event的大小,默許是每一個(gè)Event是2048個(gè)byte。Flume
Agent Channel的大小默許等于于本地服務(wù)器上JVM所獲得到的內(nèi)存的80%,用戶可以通過byteCapacityBufferPercentage和byteCapacity兩個(gè)參數(shù)去進(jìn)行優(yōu)化。
需要特別注意的是FTP上放入Flume監(jiān)聽的文件夾中的日志文件不能同名,不然Flume會(huì)報(bào)錯(cuò)并停止工作,最好的解決方案就是為每份日志文件拼上時(shí)間戳。
在Hadoop服務(wù)器上的配置文件以下: agent.sources = origin
agent.channels = memorychannel
agent.sinks = target
agent.sources.origin.type = avro
agent.sources.origin.channels = memorychannel
agent.sources.origin.bind = 0.0.0.0
agent.sources.origin.port = 4545
#agent.sources.origin.interceptors = i1 i2
#agent.sources.origin.interceptors.i1.type = timestamp
#agent.sources.origin.interceptors.i2.type = host
#agent.sources.origin.interceptors.i2.hostHeader = hostname
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memorychannel
agent.channels.memorychannel.type = memory
agent.channels.memorychannel.capacity = 5000000
agent.channels.memorychannel.transactionCapacity = 1000000
agent.sinks.target.type = hdfs
agent.sinks.target.channel = memorychannel
agent.sinks.target.hdfs.path = /flume/events/%y-%m-%d/%H%M%S
agent.sinks.target.hdfs.filePrefix = data-%{hostname}
agent.sinks.target.hdfs.rollInterval = 60
agent.sinks.target.hdfs.rollSize = 1073741824
agent.sinks.target.hdfs.rollCount = 1000000
agent.sinks.target.hdfs.round = true
agent.sinks.target.hdfs.roundValue = 10
agent.sinks.target.hdfs.roundUnit = minute
agent.sinks.target.hdfs.useLocalTimeStamp = true
agent.sinks.target.hdfs.minBlockReplicas=1
agent.sinks.target.hdfs.writeFormat=Text
agent.sinks.target.hdfs.fileType=DataStream
round, roundValue,roundUnit3個(gè)參數(shù)是用來配置每10分鐘在hdfs里生成1個(gè)文件夾保存從FTP服務(wù)器上拉取下來的數(shù)據(jù)。
Troubleshooting
使用Flume拉取文件到HDFS中會(huì)遇到將文件分散成多個(gè)1KB⑸KB的小文件的問題
需要注意的是如果遇到Flume會(huì)將拉取過來的文件分成很多份1KB⑸KB的小文件存儲(chǔ)到HDFS上,那末極可能是HDFS
Sink的配置不正確,致使系統(tǒng)使用了默許配置。spooldir類型的source是將指定目錄中的文件的每行封裝成1個(gè)event放入到channel中,默許每行最大讀取1024個(gè)字符。在HDFS Sink端主要是通過rollInterval(默許30秒), rollSize(默許1KB), rollCount(默許10個(gè)event)3個(gè)屬性來決定寫進(jìn)HDFS的分片文件的大小。rollInterval表示經(jīng)過量少秒后就將當(dāng)前.tmp文件(寫入的是從channel中過來的events)下沉到HDFS文件系統(tǒng)中,rollSize表示1旦.tmp文件到達(dá)1定的size后,就下沉到HDFS文件系統(tǒng)中,rollCount表示.tmp文件1旦寫入了指定數(shù)量的events就下沉到HDFS文件系統(tǒng)中。
使用Flume拉取到HDFS中的文件格式錯(cuò)亂
這是由于HDFS Sink的配置中,hdfs.writeFormat屬性默許為“Writable”會(huì)將本來的文件的內(nèi)容序列化成HDFS的格式,應(yīng)當(dāng)手動(dòng)設(shè)置成hdfs.writeFormat=“text”; 并且hdfs.fileType默許是“SequenceFile”類型的,是將所有event拼成1行,應(yīng)當(dāng)該手動(dòng)設(shè)置成hdfs.fileType=“DataStream”,這樣就能夠是1行1個(gè)event,與原文件格式保持1致
使用Mapreduce清洗日志文件
當(dāng)把日志文件中的數(shù)據(jù)拉取到HDFS文件系統(tǒng)后,使用Mapreduce程序去進(jìn)行日志清洗
第1步,先用Mapreduce過濾掉無效的數(shù)據(jù)
package com.guludada.clickstream;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.StringTokenizer;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.guludada.dataparser.WebLogParser;
public class logClean {
public static class cleanMap extends Mapper<Object,Text,Text,NullWritable> {
private NullWritable v = NullWritable.get();
private Text word = new Text();
WebLogParser webLogParser = new WebLogParser();
public void map(Object key,Text value,Context context) {
//將1行內(nèi)容轉(zhuǎn)成string
String line = value.toString();
String cleanContent = webLogParser.parser(line);
if(cleanContent != "") {
word.set(cleanContent);
try {
context.write(word,v);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ymhHadoop:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(logClean.class);
//指定本業(yè)務(wù)job要使用的mapper/Reducer業(yè)務(wù)類
job.setMapperClass(cleanMap.class);
//指定mapper輸出數(shù)據(jù)的kv類型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//指定job的輸入原始文件所在目錄
Date curDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yy-MM-dd");
String dateStr = sdf.format(curDate);
FileInputFormat.setInputPaths(job, new Path("/flume/events/" + dateStr + "/*/*"));
//指定job的輸出結(jié)果所在目錄
FileOutputFormat.setOutputPath(job, new Path("/clickstream/cleandata/"+dateStr+"/"));
//將job中配置的相干參數(shù),和job所用的java類所在的jar包,提交給yarn去運(yùn)行
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
package com.guludada.dataparser;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.guludada.javabean.WebLogBean;
/**
* 用
正則表達(dá)式匹配出合法的日志記錄
*
*
*/
public class WebLogParser {
public String parser(String weblog_origin) {
WebLogBean weblogbean = new WebLogBean();
// 獲得IP地址
Pattern IPPattern = Pattern.compile("\\d+.\\d+.\\d+.\\d+");
Matcher IPMatcher = IPPattern.matcher(weblog_origin);
if(IPMatcher.find()) {
String IPAddr = IPMatcher.group(0);
weblogbean.setIP_addr(IPAddr);
} else {
return ""
}
// 獲得時(shí)間信息
Pattern TimePattern = Pattern.compile("\\[(.+)\\]");
Matcher TimeMatcher = TimePattern.matcher(weblog_origin);
if(TimeMatcher.find()) {
String time = TimeMatcher.group(1);
String[] cleanTime = time.split(" ");
weblogbean.setTime(cleanTime[0]);
} else {
return "";
}
//獲得其余要求信息
Pattern InfoPattern = Pattern.compile(
"(\\\"[POST|GET].+?\\\") (\\d+) (\\d+).+?(\\\".+?\\\") (\\\".+?\\\")");
Matcher InfoMatcher = InfoPattern.matcher(weblog_origin);
if(InfoMatcher.find()) {
String requestInfo = InfoMatcher.group(1).replace('\"',' ').trim();
String[] requestInfoArry = requestInfo.split(" ");
weblogbean.setMethod(requestInfoArry[0]);
weblogbean.setRequest_URL(requestInfoArry[1]);
weblogbean.setRequest_protocol(requestInfoArry[2]);
String status_code = InfoMatcher.group(2);
weblogbean.setRespond_code(status_code);
String respond_data = InfoMatcher.group(3);
weblogbean.setRespond_data(respond_data);
String request_come_from = InfoMatcher.group(4).replace('\"',' ').trim();
weblogbean.setRequst_come_from(request_come_from);
String browserInfo = InfoMatcher.group(5).replace('\"',' ').trim();
weblogbean.setBrowser(browserInfo);
} else {
return "";
}
return weblogbean.toString();
}
}
package com.guludada.javabean;
public class WebLogBean {
String IP_addr;
String time;
String method;
String request_URL;
String request_protocol;
String respond_code;
String respond_data;
String requst_come_from;
String browser;
public String getIP_addr() {
return IP_addr;
}
public void setIP_addr(String iP_addr) {
IP_addr = iP_addr;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getMethod() {
return method;
}
public void setMethod(String method) {
this.method = method;
}
public String getRequest_URL() {
return request_URL;
}
public void setRequest_URL(String request_URL) {
this.request_URL = request_URL;
}
public String getRequest_protocol() {
return request_protocol;
}
public void setRequest_protocol(String request_protocol) {
this.request_protocol = request_protocol;
}
public String getRespond_code() {
return respond_code;
}
public void setRespond_code(String respond_code) {
this.respond_code = respond_code;
}
public String getRespond_data() {
return respond_data;
}
public void setRespond_data(String respond_data) {
this.respond_data = respond_data;
}
public String getRequst_come_from() {
return requst_come_from;
}
public void setRequst_come_from(String requst_come_from) {
this.requst_come_from = requst_come_from;
}
public String getBrowser() {
return browser;
}
public void setBrowser(String browser) {
this.browser = browser;
}
@Override
public String toString() {
return IP_addr + " " + time + " " + method + " "
+ request_URL + " " + request_protocol + " " + respond_code
+ " " + respond_data + " " + requst_come_from + " " + browser;
}
}
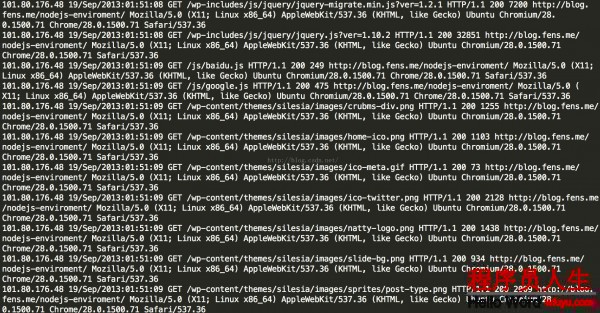
第1第二天記清洗后的記錄以下圖:
package com.guludada.clickstream;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.HashMap;
import java.util.Locale;
import java.util.UUID;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.guludada.clickstream.logClean.cleanMap;
import com.guludada.dataparser.SessionParser;
import com.guludada.dataparser.WebLogParser;
import com.guludada.javabean.WebLogSessionBean;
public class logSession {
public static class sessionMapper extends Mapper<Object,Text,Text,Text> {
private Text IPAddr = new Text();
private Text content = new Text();
private NullWritable v = NullWritable.get();
WebLogParser webLogParser = new WebLogParser();
public void map(Object key,Text value,Context context) {
//將1行內(nèi)容轉(zhuǎn)成string
String line = value.toString();
String[] weblogArry = line.split(" ");
IPAddr.set(weblogArry[0]);
content.set(line);
try {
context.write(IPAddr,content);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
static class sessionReducer extends Reducer<Text, Text, Text, NullWritable>{
private Text IPAddr = new Text();
private Text content = new Text();
private NullWritable v = NullWritable.get();
WebLogParser webLogParser = new WebLogParser();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
SessionParser sessionParser = new SessionParser();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Date sessionStartTime = null;
String sessionID = UUID.randomUUID().toString();
//將IP地址所對(duì)應(yīng)的用戶的所有閱讀記錄按時(shí)間排序
ArrayList<WebLogSessionBean> sessionBeanGroup = new ArrayList<WebLogSessionBean>();
for(Text browseHistory : values) {
WebLogSessionBean sessionBean = sessionParser.loadBean(browseHistory.toString());
sessionBeanGroup.add(sessionBean);
}
Collections.sort(sessionBeanGroup,new Comparator<WebLogSessionBean>() {
public int compare(WebLogSessionBean sessionBean1, WebLogSessionBean sessionBean2) {
Date date1 = sessionBean1.getTimeWithDateFormat();
Date date2 = sessionBean2.getTimeWithDateFormat();
if(date1 == null && date2 == null) return 0;
return date1.compareTo(date2);
}
});
for(WebLogSessionBean sessionBean : sessionBeanGroup) {
if(sessionStartTime == null) {
//當(dāng)天日志中某用戶第1次訪問網(wǎng)站的時(shí)間
sessionStartTime = timeTransform(sessionBean.getTime());
content.set(sessionParser.parser(sessionBean, sessionID));
try {
context.write(content,v);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} else {
Date sessionEndTime = timeTransform(sessionBean.getTime());
long sessionStayTime = timeDiffer(sessionStartTime,sessionEndTime);
if(sessionStayTime > 30 * 60 * 1000) {
//將當(dāng)前閱讀記錄的時(shí)間設(shè)為下1個(gè)session的開始時(shí)間
sessionStartTime = timeTransform(sessionBean.getTime());
sessionID = UUID.randomUUID().toString();
continue;
}
content.set(sessionParser.parser(sessionBean, sessionID));
try {
context.write(content,v);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
private Date timeTransform(String time) {
Date standard_time = null;
try {
standard_time = sdf.parse(time);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return standard_time;
}
private long timeDiffer(Date start_time,Date end_time) {
long diffTime = 0;
diffTime = end_time.getTime() - start_time.getTime();
return diffTime;
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ymhHadoop:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(logClean.class);
//指定本業(yè)務(wù)job要使用的mapper/Reducer業(yè)務(wù)類
job.setMapperClass(sessionMapper.class);
job.setReducerClass(sessionReducer.class);
//指定mapper輸出數(shù)據(jù)的kv類型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定終究輸出的數(shù)據(jù)的kv類型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
Date curDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yy-MM-dd");
String dateStr = sdf.format(curDate);
//指定job的輸入原始文件所在目錄
FileInputFormat.setInputPaths(job, new Path("/clickstream/cleandata/"+dateStr+"/*"));
//指定job的輸出結(jié)果所在目錄
FileOutputFormat.setOutputPath(job, new Path("/clickstream/sessiondata/"+dateStr+"/"));
//將job中配置的相干參數(shù),和job所用的java類所在的jar包,提交給yarn去運(yùn)行
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
package com.guludada.dataparser;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import com.guludada.javabean.WebLogSessionBean;
public class SessionParser {
SimpleDateFormat sdf_origin = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH);
SimpleDateFormat sdf_final = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public String parser(WebLogSessionBean sessionBean,String sessionID) {
sessionBean.setSession(sessionID);
return sessionBean.toString();
}
public WebLogSessionBean loadBean(String sessionContent) {
WebLogSessionBean weblogSession = new WebLogSessionBean();
String[] contents = sessionContent.split(" ");
weblogSession.setTime(timeTransform(contents[1]));
weblogSession.setIP_addr(contents[0]);
weblogSession.setRequest_URL(contents[3]);
weblogSession.setReferal(contents[7]);
return weblogSession;
}
private String timeTransform(String time) {
Date standard_time = null;
try {
standard_time = sdf_origin.parse(time);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return sdf_final.format(standard_time);
}
}
package com.guludada.javabean;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class WebLogSessionBean {
String time;
String IP_addr;
String session;
String request_URL;
String referal;
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getIP_addr() {
return IP_addr;
}
public void setIP_addr(String iP_addr) {
IP_addr = iP_addr;
}
public String getSession() {
return session;
}
public void setSession(String session) {
this.session = session;
}
public String getRequest_URL() {
return request_URL;
}
public void setRequest_URL(String request_URL) {
this.request_URL = request_URL;
}
public String getReferal() {
return referal;
}
public void setReferal(String referal) {
this.referal = referal;
}
public Date getTimeWithDateFormat() {
SimpleDateFormat sdf_final = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
if(this.time != null && this.time != "") {
try {
return sdf_final.parse(this.time);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return null;
}
@Override
public String toString() {
return time + " " + IP_addr + " " + session + " "
+ request_URL + " " + referal;
}
}
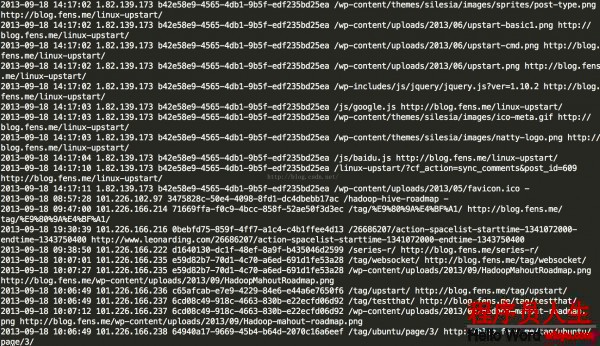
第2次清算出來的Session信息結(jié)構(gòu)以下:
| 時(shí)間 |
IP |
SessionID |
要求頁面URL |
Referal URL |
| 2015-05⑶0 19:38:00 |
192.168.12.130 |
Session1 |
/blog/me |
www.baidu.com |
| 2015-05⑶0 19:39:00 |
192.168.12.130 |
Session1 |
/blog/me/details |
www.mysite.com/blog/me |
| 2015-05⑶0 19:38:00 |
192.168.12.40 |
Session2 |
/blog/me |
www.baidu.com |
第3步,清洗第2步生成的Session信息,生成PageViews信息表
package com.guludada.clickstream;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.guludada.clickstream.logClean.cleanMap;
import com.guludada.clickstream.logSession.sessionMapper;
import com.guludada.clickstream.logSession.sessionReducer;
import com.guludada.dataparser.PageViewsParser;
import com.guludada.dataparser.SessionParser;
import com.guludada.dataparser.WebLogParser;
import com.guludada.javabean.PageViewsBean;
import com.guludada.javabean.WebLogSessionBean;
public class PageViews {
public static class pageMapper extends Mapper<Object,Text,Text,Text> {
private Text word = new Text();
public void map(Object key,Text value,Context context) {
String line = value.toString();
String[] webLogContents = line.split(" ");
//根據(jù)session來分組
word.set(webLogContents[2]);
try {
context.write(word,value);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static class pageReducer extends Reducer<Text, Text, Text, NullWritable>{
private Text session = new Text();
private Text content = new Text();
private NullWritable v = NullWritable.get();
PageViewsParser pageViewsParser = new PageViewsParser();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//上1條記錄的訪問信息
PageViewsBean lastStayPageBean = null;
Date lastVisitTime = null;
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//將session所對(duì)應(yīng)的所有閱讀記錄按時(shí)間排序
ArrayList<PageViewsBean> pageViewsBeanGroup = new ArrayList<PageViewsBean>();
for(Text pageView : values) {
PageViewsBean pageViewsBean = pageViewsParser.loadBean(pageView.toString());
pageViewsBeanGroup.add(pageViewsBean);
}
Collections.sort(pageViewsBeanGroup,new Comparator<PageViewsBean>() {
public int compare(PageViewsBean pageViewsBean1, PageViewsBean pageViewsBean2) {
Date date1 = pageViewsBean1.getTimeWithDateFormat();
Date date2 = pageViewsBean2.getTimeWithDateFormat();
if(date1 == null && date2 == null) return 0;
return date1.compareTo(date2);
}
});
//計(jì)算每一個(gè)頁面的停留時(shí)間
int step = 0;
for(PageViewsBean pageViewsBean : pageViewsBeanGroup) {
Date curVisitTime = pageViewsBean.getTimeWithDateFormat();
if(lastStayPageBean != null) {
//計(jì)算前后兩次訪問記錄像差的時(shí)間,單位是秒
Integer timeDiff = (int) ((curVisitTime.getTime() - lastVisitTime.getTime())/1000);
//根據(jù)當(dāng)前記錄的訪問信息更新上1條訪問記錄中訪問的頁面的停留時(shí)間
lastStayPageBean.setStayTime(timeDiff.toString());
}
//更新訪問記錄的步數(shù)
step++;
pageViewsBean.setStep(step+"");
//更新上1條訪問記錄的停留時(shí)間后,將當(dāng)前訪問記錄設(shè)定為上1條訪問信息記錄
lastStayPageBean = pageViewsBean;
lastVisitTime = curVisitTime;
//輸出pageViews信息
content.set(pageViewsParser.parser(pageViewsBean));
try {
context.write(content,v);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ymhHadoop:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(PageViews.class);
//指定本業(yè)務(wù)job要使用的mapper/Reducer業(yè)務(wù)類
job.setMapperClass(pageMapper.class);
job.setReducerClass(pageReducer.class);
//指定mapper輸出數(shù)據(jù)的kv類型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定終究輸出的數(shù)據(jù)的kv類型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
Date curDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yy-MM-dd");
String dateStr = sdf.format(curDate);
//指定job的輸入原始文件所在目錄
FileInputFormat.setInputPaths(job, new Path("/clickstream/sessiondata/"+dateStr+"/*"));
//指定job的輸出結(jié)果所在目錄
FileOutputFormat.setOutputPath(job, new Path("/clickstream/pageviews/"+dateStr+"/"));
//將job中配置的相干參數(shù),和job所用的java類所在的jar包,提交給yarn去運(yùn)行
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
package com.guludada.dataparser;
import com.guludada.javabean.PageViewsBean;
import com.guludada.javabean.WebLogSessionBean;
public class PageViewsParser {
/**
* 根據(jù)logSession的輸出數(shù)據(jù)加載PageViewsBean
*
* */
public PageViewsBean loadBean(String sessionContent) {
PageViewsBean pageViewsBean = new PageViewsBean();
String[] contents = sessionContent.split(" ");
pageViewsBean.setTime(contents[0] + " " + contents[1]);
pageViewsBean.setIP_addr(contents[2]);
pageViewsBean.setSession(contents[3]);
pageViewsBean.setVisit_URL(contents[4]);
pageViewsBean.setStayTime("0");
pageViewsBean.setStep("0");
return pageViewsBean;
}
public String parser(PageViewsBean pageBean) {
return pageBean.toString();
}
}
package com.guludada.javabean;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class PageViewsBean {
String session;
String IP_addr;
String time;
String visit_URL;
String stayTime;
String step;
public String getSession() {
return session;
}
public void setSession(String s
生活不易,碼農(nóng)辛苦
如果您覺得本網(wǎng)站對(duì)您的學(xué)習(xí)有所幫助,可以手機(jī)掃描二維碼進(jìn)行捐贈(zèng)

------分隔線----------------------------
------分隔線----------------------------