

當在預測時,有很大的誤差,該如何處理?

1.得到更多的訓練樣本
2.選取少許的特點
3.得到更多的特點項
4.加入特點多項式
5.減少正則項系數(shù)
6.增加正則項系數(shù)
很多人,在遇到預測結(jié)果其實不理想的時候,會憑著感覺在上面的6個方案當選取1個進行,但是常常花費了大量時間卻得不到改進。
因而引入了機器學習診斷,在后面會詳細論述,

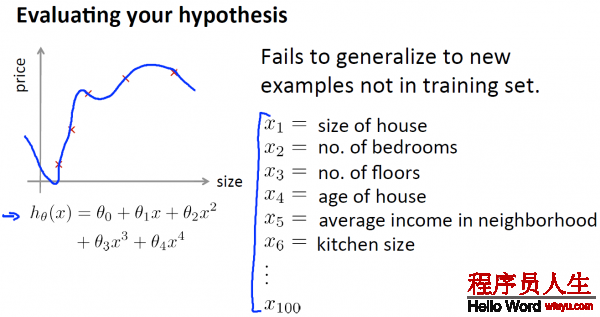
以下,給出了1種評估假定函數(shù)的標準方法:
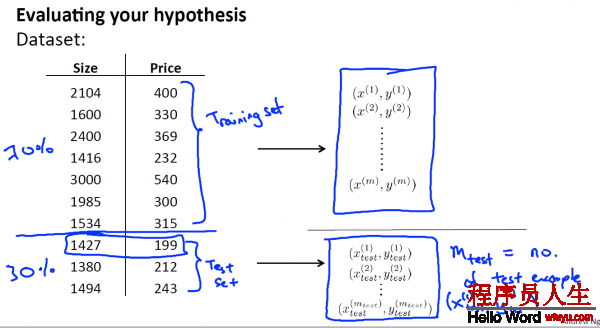
將這些數(shù)據(jù)集分為兩個部份:Training set 和 Test set, 即是 訓練集和測試集,
其中1種典型的分割方法是, 依照7:3的比例 ,將70%的數(shù)據(jù)作為訓練集, 30%的數(shù)據(jù)作為測試集 。
PS:如果數(shù)據(jù)集是有順序的話,那末最好還是隨機取樣。比如說上圖的例子中,如果price或size是按遞增或遞減排列的話,那末就應(yīng)當隨機取樣本,而不是將前70%作為訓練集,后30%作為測試集了。
接下來 這里展現(xiàn)了1種典型的方法,你可以依照這些步驟訓練和測試你的學習算法 比如線性回歸算法 。首先 ,你需要對訓練集進行學習得到參數(shù)

Linear Regreesion error:
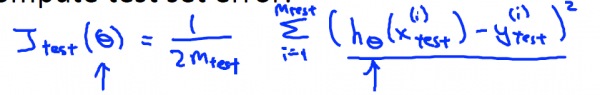
Logistic Regression error:
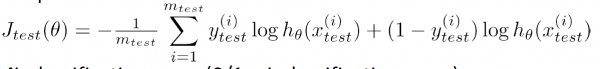
假設(shè)你想要肯定對某組數(shù)據(jù), 最適合的多項式次數(shù)是幾次 ?怎樣選用正確的特點來構(gòu)造學習算法 或假設(shè)你需要正確選擇 學習算法中的正則化參數(shù)λ ,你應(yīng)當怎樣做呢?
Model Selection:
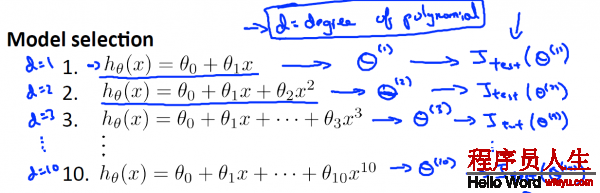
1.首先,建立d個model 假定(圖中有10個,d表示其id),分別在training set 上求使其training error最小的θ向量,那末得到d個
2.然后,對這d個model假定,帶入
PS: 其實d表示dimension,也就是維度,表示該hypothesis的最大polynomial項是d維的。
PS’: 1般地,
選擇第1個模型(
接下來,我們需要做的是對所有這些模型,求出測試集誤差(Test Error),順次求出

這里選擇的是5項式。那末問題來了,現(xiàn)在我想知道這個模型能不能很好地推行到新樣本,我們還能通過測試集來驗證1般性嗎?這看起來仿佛有點不公道,由于我們剛才是通過測試集跟假定擬合來得到多項式次數(shù)
所以,為了解決這個問題,在模型選擇中,我們將數(shù)據(jù)集不單單是分為訓練集,測試集,而是分為訓練集,交叉驗證集和測試集{60%,20%,20%}的比例

1種典型的分割比例是 將60%的數(shù)據(jù)分給訓練集,大約20%的數(shù)據(jù)給交叉驗證集 ,最后20%給測試集。這個比例可以略微調(diào)劑,但這類分法是最典型的。

依照上面所述的步驟,這里不再贅述! (詳情在上面Model Selection下面有解釋)
當你運行1個學習算法時 ,如果這個算法的表現(xiàn)不理想, 那末多半是出現(xiàn) 兩種情況 :要末是偏差比較大, 要末是方差比較大, 換句話說, 出現(xiàn)的情況要末是欠擬合, 要末是過擬合問題 。
那末這兩種情況, 哪一個和偏差有關(guān), 哪一個和方差有關(guān), 或是否是和兩個都有關(guān) 。弄清楚這1點非常重要 ,由于能判斷出現(xiàn)的情況, 是這兩種情況中的哪種, 實際上是1個很有效的唆使器, 指引著可以改進算法的 ,最有效的方法和途徑 。
1. bias指hypothesis與正確的hypothesis(如果有的話)的偏差.
2. varience是指各樣本與hypothesis的偏差和
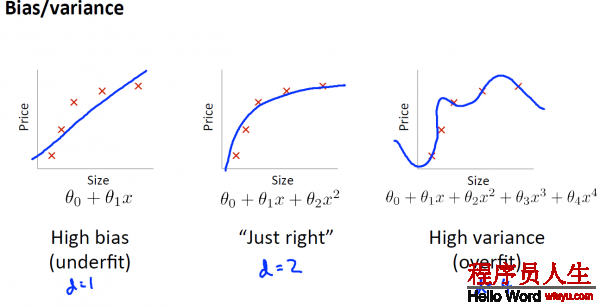
從下圖,橫軸表示多項式的次數(shù)d,縱軸表示誤差error,我們可以看出,當d很小時,也就是處于underfit狀態(tài)時,
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有



