
最近由于PAC平臺自動化的需求,開始探坑推薦系統。這個乍1聽去樂趣無窮的課題,對算法大神們來講是這樣的:

而對剛接觸這個領域的我來講,是這樣的:

在深坑外圍徘徊了1周后,我整理了1些推薦系統的基本概念和1些有代表性的簡單的算法,作為初探總結,也希望能拋磚引玉,給一樣想入坑的火伴們提供1些思路。
1.甚么是推薦系統
如果你是個多年電商(剁手)黨,你會說是這個:
如果你是名充滿文藝細胞的音樂發熱友,你會答這個:
如果你是位活躍在各大社交平臺的點贊狂魔,你會答這個:
沒錯,猜你喜歡、個性歌單、熱門微博,這些都是推薦系統的輸出內容。從這些我們就能夠總結出,推薦系統究竟是做甚么的。
目的1:幫助用戶找到想要的商品(新聞/音樂/……),發掘長尾
幫用戶找到想要的東西,談何容易。商品茫茫多,乃至是我們自己,也常常點開淘寶,面對眼花繚亂的打折活動不知道要買啥。在經濟學中,有1個著名理論叫長尾理論(The Long Tail)。
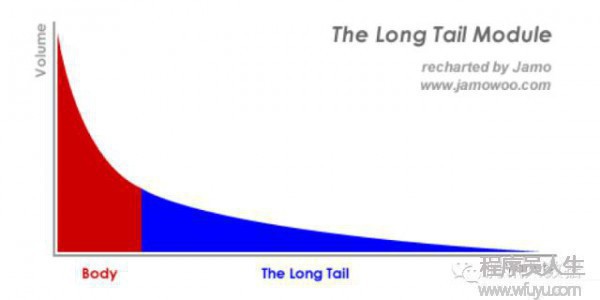
套用在互聯網領域中,指的就是最熱的那1小部份資源將得到絕大部份的關注,而剩下的很大1部份資源卻鮮少有人問津。這不但造成了資源利用上的浪費,也讓很多口味偏小眾的用戶沒法找到自己感興趣的內容。
目的2:下降信息過載
互聯網時期信息量已然處于爆炸狀態,若是將所有內容都放在網站首頁上用戶是無從瀏覽的,信息的利用率將會10分低下。因此我們需要推薦系統來幫助用戶過濾掉低價值的信息。
目的3:提高站點的點擊率/轉化率
好的推薦系統能讓用戶更頻繁地訪問1個站點,并且總是能為用戶找到他想要購買的商品或瀏覽的內容。
目的4:加深對用戶的了解,為用戶提供定制化服務
可以想見,每當系統成功推薦了1個用戶感興趣的內容后,我們對該用戶的興趣愛好等維度上的形象是愈來愈清晰的。當我們能夠精確描繪出每一個用戶的形象以后,就能夠為他們定制1系列服務,讓具有各種需求的用戶都能在我們的平臺上得到滿足。
算法是甚么?我們可以把它簡化為1個函數。函數接受若干個參數,輸出1個返回值。
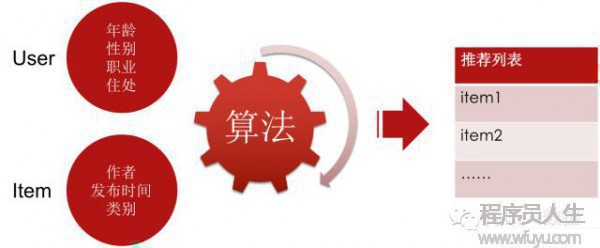
算法如上圖,輸入參數是用戶和item的各種屬性和特點,包括年齡、性別、地域、商品的種別、發布時間等等。經過推薦算法處理后,返回1個依照用戶喜好度排序的item列表。
推薦算法大致可以分為以下幾類[1]:
基于流行度的算法
協同過濾算法
基于內容的算法
基于模型的算法
混合算法
基于流行度的算法非常簡單粗魯,類似于各大新聞、微博熱榜等,根據PV、UV、日均PV或分享率等數據來按某種熱度排序來推薦給用戶。

這類算法的優點是簡單,適用于剛注冊的新用戶。缺點也很明顯,它沒法針對用戶提供個性化的推薦。基于這類算法也可做1些優化,比如加入用戶分群的流行度排序,例如把熱榜上的體育內容優先推薦給體育迷,把政要熱文推給酷愛談論政治的用戶。
協同過濾算法(Collaborative Filtering, CF)是很經常使用的1種算法,在很多電商網站上都有用到。CF算法包括基于用戶的CF(User-based CF)和基于物品的CF(Item-based CF)。
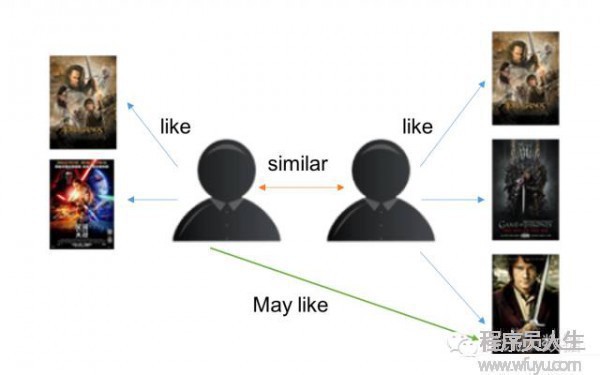
基于用戶的CF原理以下:
分析各個用戶對item的評價(通過閱讀記錄、購買記錄等);
根據用戶對item的評價計算得出所有用戶之間的相似度;
選出與當前用戶最相似的N個用戶;
將這N個用戶評價最高并且當前用戶又沒有閱讀過的item推薦給當前用戶。
示意圖以下:
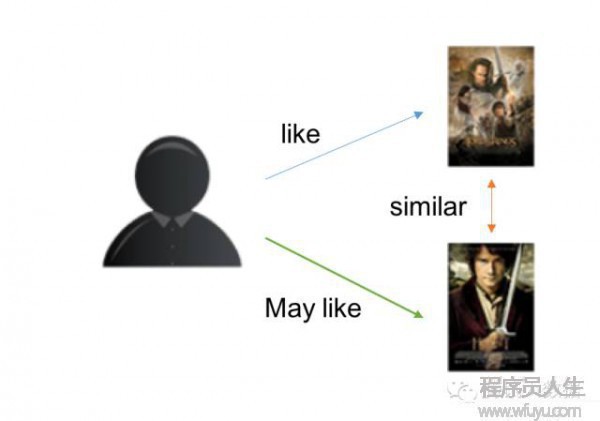
基于物品的CF原理大同小異,只是主體在于物品:
分析各個用戶對item的閱讀記錄。
根據閱讀記錄分析得出所有item之間的相似度;
對當前用戶評價高的item,找出與之相似度最高的N個item;
將這N個item推薦給用戶。
示意圖以下:
舉個栗子,基于用戶的CF算法大致的計算流程以下:
首先我們根據網站的記錄計算出1個用戶與item的關聯矩陣,以下:
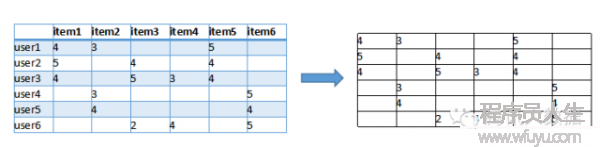
圖中,行是不同的用戶,列是所有物品,(x, y)的值則是x用戶對y物品的評分(喜好程度)。我們可以把每行視為1個用戶對物品偏好的向量,然后計算每兩個用戶之間的向量距離,這里我們用余弦相似度來算:
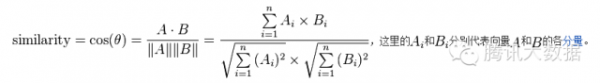
然后得出用戶向量之間相似度以下,其中值越接近1表示這兩個用戶越相似:
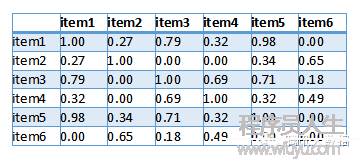
最后,我們要為用戶1推薦物品,則找出與用戶1相似度最高的N名用戶(設N=2)評價的物品,去掉用戶1評價過的物品,則是推薦結果。
基于物品的CF計算方式大致相同,只是關聯矩陣變成了item和item之間的關系,若用戶同時閱讀過item1和item2,則(1,1)的值為1,最后計算出所有item之間的關聯關系以下:

我們可以看到,CF算法確切簡單,而且很多時候推薦也是很準確的。但是它也存在1些問題:
依賴于準確的用戶評分;
在計算的進程中,那些大熱的物品會有更大的概率被推薦給用戶;
冷啟動問題。當有1名新用戶或新物品進入系統時,推薦將無從根據;
在1些item生存周期短(如新聞、廣告)的系統中,由于更新速度快,大量item不會有用戶評分,造成評分矩陣稀疏,不利于這些內容的推薦。
對矩陣稀疏的問題,有很多方法來改進CF算法。比如通過矩陣因子分解(如LFM),我們可以把1個nm的矩陣分解為1個nk的矩陣乘以1個k*m的矩陣,以下圖:
這里的k可以是用戶的特點、興趣愛好與物品屬性的1些聯系,通過因子分解,可以找到用戶和物品之間的1些潛伏關聯,從而彌補之前矩陣中的缺失值。
CF算法看起來很好很強大,通過改進也能克服各種缺點。那末問題來了,假設我是個《指環王》的忠實讀者,我買過1本《雙塔奇兵》,這時候庫里新進了第3部:《王者歸來》,那末明顯我會很感興趣。但是基于之前的算法,不管是用戶評分還是書名的檢索都不太好使,因而基于內容的推薦算法呼之欲出。
舉個栗子,現在系統里有1個用戶和1條新聞。通過分析用戶的行動和新聞的文本內容,我們提取出數個關鍵字,以下圖:
將這些關鍵字作為屬性,把用戶和新聞分解成向量,以下圖:
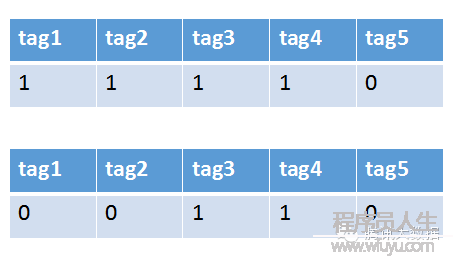
以后再計算向量距離,即可以得出該用戶和新聞的相似度了。這類方法很簡單,如果在為1名酷愛觀看英超聯賽的足球迷推薦新聞時,新聞里同時存在關鍵字體育、足球、英超,明顯匹配前兩個詞都不如直接匹配英超來得準確,系統該如何體現出關鍵詞的這類“重要性”呢?這時候我們即可以引入詞權的概念。在大量的語料庫中通過計算(比如典型的TF-IDF算法),我們可以算出新聞中每個關鍵詞的權重,在計算相似度時引入這個權重的影響,就能夠到達更精確的效果。
sim(user, item) = 文本相似度(user, item) * 詞權
但是,常常接觸體育新聞方面數據的同學就會要提出問題了:要是用戶的興趣是足球,而新聞的關鍵詞是德甲、英超,依照上面的文本匹配方法明顯沒法將他們關聯到1起。在此,我們可以援用話題聚類:
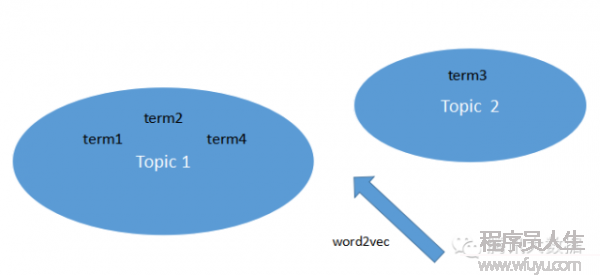
利用word2vec1類工具,可以將文本的關鍵詞聚類,然后根據topic將文本向量化。如可以將德甲、英超、西甲聚類到“足球”的topic下,將lv、Gucci聚類到“奢侈品”topic下,再根據topic為文本內容與用戶作相似度計算。
綜上,基于內容的推薦算法能夠很好地解決冷啟動問題,并且也不會囿于熱度的限制,由于它是直接基于內容匹配的,而與閱讀記錄無關。但是它也會存在1些弊端,比如過度專業化(over-specialisation)的問題。這類方法會1直推薦給用戶內容密切關聯的item,而失去了推薦內容的多樣性。
基于模型的方法有很多,用到的諸如機器學習的方法也能夠很深,這里只簡單介紹下比較簡單的方法——Logistics回歸預測。我們通過分析系統中用戶的行動和購買記錄等數據,得到以下表:
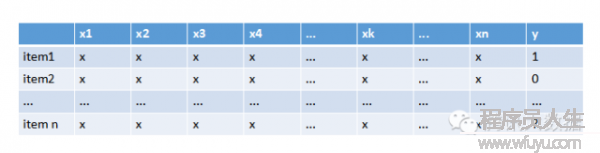
表中的行是1種物品,x1~xn是影響用戶行動的各種特點屬性,如用戶年齡段、性別、地域、物品的價格、種別等等,y則是用戶對該物品的喜好程度,可以是購買記錄、閱讀、收藏等等。通過大量這類的數據,我們可以回歸擬合出1個函數,計算出x1~xn對應的系數,這即是各特點屬性對應的權重,權重值越大則表明該屬性對用戶選擇商品越重要。
在擬合函數的時候我們會想到,單1的某種屬性和另外一種屬性可能其實不存在強關聯。比如,年齡與購買護膚品這個行動其實不呈強關聯,性別與購買護膚品也不強關聯,但當我們把年齡與性別綜合在1起斟酌時,它們便和購買行動產生了強關聯。比如(我只是比如),20~30歲的女性用戶更偏向于購買護膚品,這就叫交叉屬性。通過反復測試和經驗,我們可以調劑特點屬性的組合,擬合出最準確的回歸函數。最后得出的屬性權重以下:
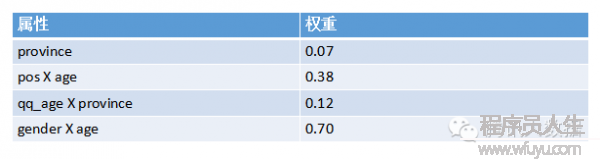
基于模型的算法由于快速、準確,適用于實時性比較高的業務如新聞、廣告等,而若是需要這類算法到達更好的效果,則需要人工干預反復的進行屬性的組合和挑選,也就是常說的Feature Engineering。而由于新聞的時效性,系統也需要反復更新線上的數學模型,以適應變化。
現實利用中,其實很少有直接用某種算法來做推薦的系統。在1些大的網站如Netflix,就是融會了數10種算法的推薦系統。我們可以通過給不同算法的結果加權重來綜合結果,或是在不同的計算環節中應用不同的算法來混合,到達更貼合自己業務的目的。
在算法最后得出推薦結果以后,我們常常還需要對結果進行處理。比如當推薦的內容里包括敏感辭匯、觸及用戶隱私的內容等等,就需要系統將其篩除;若數次推薦后用戶仍然對某個item毫無興趣,我們就需要將這個item下降權重,調劑排序;另外,有時系統還要斟酌話題多樣性的問題,一樣要在不同話題中挑選內容。
當推薦算法完成后,怎樣來評估這個算法的效果?CTR(點擊率)、CVR(轉化率)、停留時間等都是很直觀的數據。在完成算法后,可以通過線下計算算法的RMSE(均方根誤差)或線上進行ABTest來對照效果。
用戶畫像是最近常常被提及的1個名詞,引入用戶畫像可以為推薦系統帶來很多改進的余地,比如:
買通公司各大業務平臺,通過獲得其他平臺的用戶數據,完全解決冷啟動問題;
在不同裝備上同步用戶數據,包括QQID、裝備號、手機號等;
豐富用戶的人口屬性,包括年齡、職業、地域等;
更完善的用戶興趣狀態,方便生成用戶標簽和匹配內容。
另外,公司的優勢——社交平臺也是1個很好利用的地方。利用用戶的社交網絡,可以很方便地通過用戶的好友、興趣群的成員等更快捷地找到相似用戶和用戶可能感興趣的內容,提高推薦的準確度。
隨著大數據和機器學習的火熱,推薦系統也將愈發成熟,需要學習的地方還有很多,坑還有很深,希望有志的同學共勉~

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


