大數據量中的模糊查詢優化方案
來源:程序員人生 發布時間:2016-10-10 08:59:09 閱讀次數:3897次
----------------------------------------------------------------------------------------------
[版權申明:本文系作者原創,轉載請注明出處]
文章出處:http://blog.csdn.net/sdksdk0/article/details/52589761
作者:朱培 ID:sdksdk0
--------------------------------------------------------------------------------------------
對工作單使用 like模糊查詢時,實際上 數據庫內部索引沒法使用 ,需要逐條比較查詢內容,效力比較低在數據量很多情況下, 提供模糊查詢性能,我們可使用lucene全文索引庫技術。本文示例是在SSH框架中進行使用。使用Hibernate Search (用來整合 Hibernate + Lucene),工作單搜索功能。
1、首先可以在我們的maven工程中引入需要的jar包,
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search</artifactId>
<version>3.4.2.Final</version>
</dependency>
2、導入IKAnalyzer分詞器。由于IKAnalyzer在maven中沒有,所以我們需要手動下載這個jar包,固然了,在http://mvnrepository.com/網站上面可以找到。
下載好以后可以裝載到你自己的maven倉庫中或直接放在你工程的lib目錄中,然后來援用:例如我的是在
<dependency>
<groupId>org.wltea</groupId>
<artifactId>IKAnalyzer</artifactId>
<version>2012_u6</version>
<scope>system</scope>
<systemPath>E:\myeclipse_work\BOS\src\main\webapp\WEB-INF\lib\IKAnalyzer2012_u6.jar</systemPath>
</dependency>
3、在resource目錄中新建stopword.dic文件,內容為:
a
an
and
are
as
at
be
but
by
for
if
in
into
is
it
no
not
of
on
or
such
that
the
their
then
there
these
they
this
to
was
will
with
4、新建1個IKAnalyzer.cfg.xml文件,內容為:
<?xml version="1.0" encoding="UTF⑻"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴大配置</comment>
<!--用戶可以在這里配置自己的擴大字典
<entry key="ext_dict">ext.dic;</entry>
-->
<!--用戶可以在這里配置自己的擴大停止詞字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
5、在spring中進行配置:在配置SessionFactory中加入1行:固然了,這個時候需要自己去D盤目錄中新建1個文件夾DBIndex
<!-- 配置索引庫 -->
<prop key="hibernate.search.default.indexBase">d:/DBIndex</prop>
完全的以下:
<!-- 配置SessionFactory -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"></property>
<!-- 配置hibernate 屬性 ,參考 hibernate.properties 文件 -->
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.format_sql">true</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
<!-- 配置索引庫 -->
<prop key="hibernate.search.default.indexBase">d:/DBIndex</prop>
</props>
</property>
<!-- 映照hbm -->
<property name="mappingDirectoryLocations" value="classpath:cn/tf/bos/domain"></property>
</bean>
6、在想要實現查詢功能的那個domain中添加注解:想要搜索哪一個字段就在哪一個字段上面加上@Field注解,注意導入的是IKAnalyzer的分詞器,不是hibernate-search的分詞器。
@Indexed
@Analyzer(impl = IKAnalyzer.class)
public class WorkOrderManage implements java.io.Serializable {
// Fields
@DocumentId
private String id;
@Field
private String arrivecity; //到達城市
@Field
private String product;
分詞的效果以下:
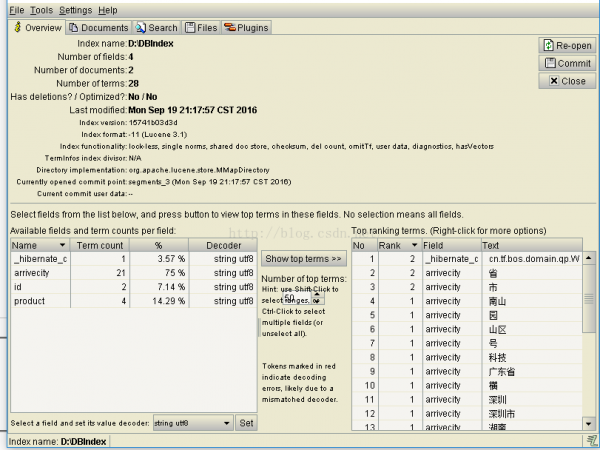
使用 Luke 工具,查詢索引文件內容 ! 在cmd中運行 java -jar lukeall⑶.5.0.jar,便可打開下圖這個頁面,查看具體的索引信息。
7、在界面中添加搜索框,我這里使用的是easyui,so...
<div data-options="region:'north'">
<!-- 編寫搜索框 -->
<!--
prompt 默許提示內容
menu 搜索條件下拉選項
searcher 點擊搜索按鈕履行js函數名稱
-->
<input id="ss" class="easyui-searchbox" style="width:300px"
data-options="prompt:'請輸入您的查詢內容',menu:'#nm',searcher:doSearch"/>
<div id="nm">
<div data-options="name:'arrivecity'">依照到達地搜索</div>
<div data-options="name:'product'">依照貨物名稱搜索</div>
</div>
</div>
8、寫doSeach這個js函數
function doSearch(value,name){
//將查詢條件緩存到datagrid
$('#grid').datagrid('load',{
conditionName:name,
conditionValue:value
});
}
9、在action中接收頁面傳過來的name和value屬性的值,然落后行處理:
public String findByPage(){
if(conditionName!=null && conditionName.trim().length()>0 && conditionValue!=null && conditionValue.trim().length()>0){
//有條件查詢
PageResponseBean pageResponseBean=workordermanagerService.findByLucene(conditionName,conditionValue,page,rows);
ActionContext.getContext().put("pageResponseBean", pageResponseBean);
}else{
DetachedCriteria detachedCriteria=DetachedCriteria.forClass(WorkOrderManage.class);
PageRequestBean pageRequestBean=initPageRequestBean(detachedCriteria);
PageResponseBean pageResponseBean=workordermanagerService.findByPage(pageRequestBean);
ActionContext.getContext().put("pageResponseBean", pageResponseBean);
}
return "findByPage";
}
private String conditionName;
private String conditionValue;
public void setConditionName(String conditionName) {
this.conditionName = conditionName;
}
public void setConditionValue(String conditionValue) {
this.conditionValue = conditionValue;
}
返回值以后如何處理這里我就不在說了。
10、在service中進行處理,經過service和serviceImpl以后,就會到達dao中,所以我們可以在dao中進行處理。
//luence查詢
@Override
public PageResponseBean findByLucene(String conditionName,
String conditionValue, int page, int rows) {
Session session=this.getSession();
FullTextSession fullTextSession=new FullTextSessionImpl(session);
Query query=new WildcardQuery(new Term(conditionName,"*"+conditionValue+"*"));
//取得全文檢索的query
FullTextQuery fullTextQuery=fullTextSession.createFullTextQuery(query);
PageResponseBean pageResponseBean=new PageResponseBean();
pageResponseBean.setTotal(fullTextQuery.getResultSize());
//當前頁數據
int firstResult=(page⑴)*rows;
int maxResults=rows;
List list=fullTextQuery.setFirstResult(firstResult).setMaxResults(maxResults).list();
pageResponseBean.setRows(list);
return pageResponseBean;
}
11、在頁面中查看搜索的效果
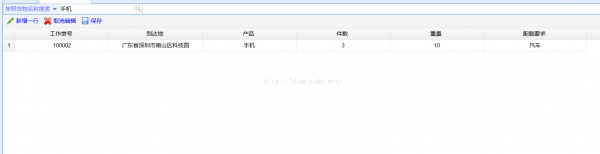
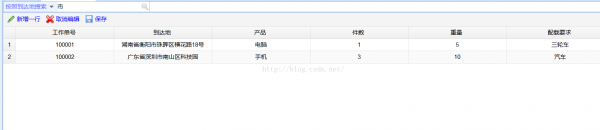
這樣我們全部開發流程就完成了。使用luence對大數據量中的模糊查詢是非常實用的功能,固然了,luence只適用于站內搜索,對模糊查詢的支持還是非常好的。
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈




