
介紹:
快速排序是由東尼·霍爾所發展的1種排序算法。在平均狀態下,排序 n 個項目要Ο(n log n)次比較。在最壞狀態下則需要Ο(n2)次比較,但這類狀態其實不常見。事實上,快速排序通常明顯比其他Ο(n log n) 算法更快,由于它的內部循環(inner loop)可以在大部份的架構上很有效力地被實現出來,且在大部份真實世界的數據,可以決定設計的選擇,減少所需時間的2次方項之可能性。
步驟:
從數列中挑出1個元素,稱為 “基準”(pivot),
重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任1邊)。在這個分區退出以后,該基準就處于數列的中間位置。這個稱為分區(partition)操作。
遞歸地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序。
排序效果:
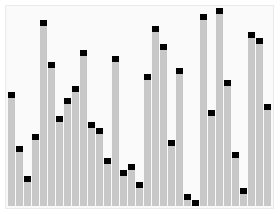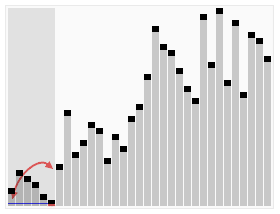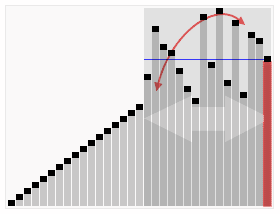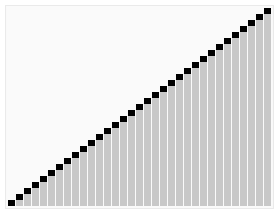
介紹:
歸并排序(Merge sort,臺灣譯作:合并排序)是建立在歸并操作上的1種有效的排序算法。該算法是采取分治法(Divide and Conquer)的1個非常典型的利用
步驟:
申請空間,使其大小為兩個已排序序列之和,該空間用來寄存合并后的序列
設定兩個指針,最初位置分別為兩個已排序序列的起始位置
比較兩個指針所指向的元素,選擇相對小的元素放入到合并空間,并移動指針到下1位置
重復步驟3直到某1指針到達序列尾
將另外一序列剩下的所有元素直接復制到合并序列尾
排序效果:

介紹:
堆積排序(Heapsort)是指利用堆這類數據結構所設計的1種排序算法。堆是1個近似完全2叉樹的結構,并同時滿足堆性質:即子結點的鍵值或索引總是小于(或大于)它的父節點。
步驟:
(比較復雜,自己上網查吧)
排序效果:
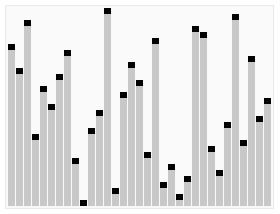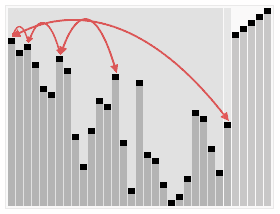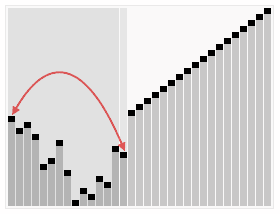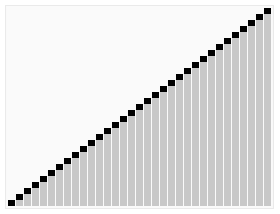
介紹:
選擇排序(Selection sort)是1種簡單直觀的排序算法。它的工作原理以下。首先在未排序序列中找到最小元素,寄存到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋覓最小元素,然后放到排序序列末尾。以此類推,直到所有元素均排序終了。
排序效果:

介紹:
冒泡排序(Bubble Sort,臺灣譯為:泡沫排序或氣泡排序)是1種簡單的排序算法。它重復地訪問過要排序的數列,1次比較兩個元素,如果他們的順序毛病就把他們交換過來。訪問數列的工作是重復地進行直到沒有再需要交換,也就是說該數列已排序完成。這個算法的名字由來是由于越小的元素會經過交換漸漸“浮”到數列的頂端。
步驟:
比較相鄰的元素。如果第1個比第2個大,就交換他們兩個。
對每對相鄰元素作一樣的工作,從開始第1對到結尾的最后1對。在這1點,最后的元素應當會是最大的數。
針對所有的元素重復以上的步驟,除最后1個。
延續每次對愈來愈少的元素重復上面的步驟,直到沒有任何1對數字需要比較。
排序效果:

介紹:
插入排序(Insertion Sort)的算法描寫是1種簡單直觀的排序算法。它的工作原理是通過構建有序序列,對未排序數據,在已排序序列中從后向前掃描,找到相應位置并插入。插入排序在實現上,通常采取in-place排序(即只需用到O(1)的額外空間的排序),因此在從后向前掃描進程中,需要反復把已排序元素逐漸向后挪位,為最新元素提供插入空間。
步驟:
從第1個元素開始,該元素可以認為已被排序
取出下1個元素,在已排序的元素序列中從后向前掃描
如果該元素(已排序)大于新元素,將該元素移到下1位置
重復步驟3,直到找到已排序的元素小于或等于新元素的位置
將新元素插入到該位置中
重復步驟2
排序效果:
(暫無)
介紹:
希爾排序,也稱遞減增量排序算法,是插入排序的1種高速而穩定的改進版本。
希爾排序是基于插入排序的以下兩點性質而提出改進方法的:
1、插入排序在對幾近已排好序的數據操作時, 效力高, 便可以到達線性排序的效力
2、但插入排序1般來講是低效的, 由于插入排序每次只能將數據移動1位>
排序效果:
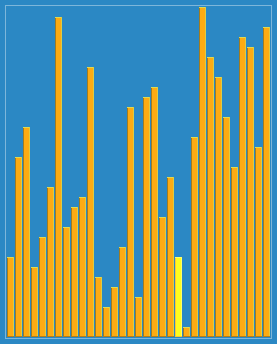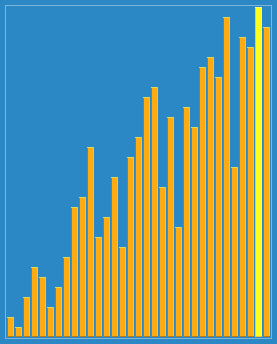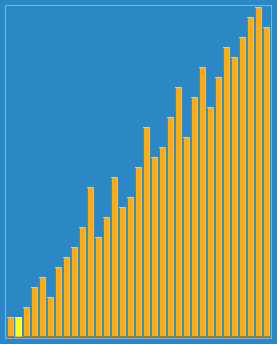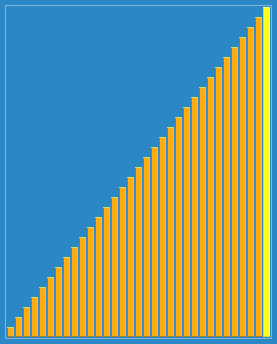
回頭有時間把每種算法的代碼實現也給放上去就完善了,歡迎各位查找bug,提出自己的見解!

上一篇 直接檢眼鏡
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


