
HDFS(Hadoop Distributed File System )Hadoop散布式文件系統的簡稱。HDFS被設計成合適運行在通用硬件(commodity hardware)上的散布式文件系統。DFS是1個高度容錯性的系統,合適部署在便宜的機器上。HDFS能提供高吞吐量的數據訪問,非常合適大范圍數據集上的利用。HDFS放寬了1部份POSIX束縛,來實現流式讀取文件系統數據的目的。HDFS在最開始是作為Apache Nutch搜索引擎項目的基礎架構而開發的。HDFS是Apache Hadoop Core項目的1部份。
本篇首先對HDFS的重要特性和使用處景做1個扼要說明,以后對HDFS的數據讀寫、元數據管理和NameNode、SecondaryNamenode的工作機制進行深入分析。
HDFS是1個文件系統,用于存儲和管理文件,通過統1的命名空間(類似于本地文件系統的目錄樹)。HDFS是散布式的系統,服務器集群中各個節點都有自己的角色和職責。理解HDFS,需要注意以下幾個概念:
客戶端要向HDFS寫數據,首先要跟namenode通訊以確認可以寫文件并取得接收文件block的datanode,然后客戶端按順序將文件逐一block傳遞給相應datanode,并由接收到block的datanode負責向其他datanode復制block的副本。
對HDFS寫數據的流程大概可以用以下的流程圖表示:
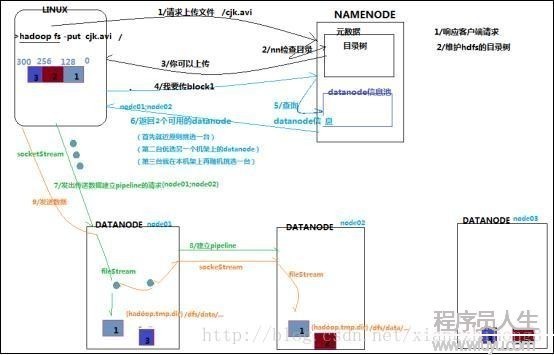
7. 客戶端向namenode發送上傳文件要求,namenode對要上傳目錄和文件進行檢查,判斷是不是可以上傳,并向客戶端返回檢查結果。
8. 客戶端得到上傳文件的允許后讀取客戶端配置,如果沒有指定配置則會讀取默許配置(例如副本數和塊大小默許為3和128M,副本是由客戶端決定的)。向namenode要求上傳1個數據塊。
9. namenode會根據客戶真個配置來查詢datanode信息,如果使用默許配置,那末終究結果會返回同1個機架的兩個datanode和另外一個機架的datanode。這稱為“機架感知”策略。
10. 客戶端在開始傳輸數據塊之前會把數據緩存在本地,當緩存大小超過了1個數據塊的大小,客戶端就會從namenode獲得要上傳的datanode列表。以后會在客戶端和第1個datanode建立連接開始流式的傳輸數據,這個datanode會1小部份1小部份(4K)的接收數據然后寫入本地倉庫,同時會把這些數據傳輸到第2個datanode,第2個datanode也一樣1小部份1小部份的接收數據并寫入本地倉庫,同時傳輸給第3個datanode,順次類推。這樣逐級調用和返回以后,待這個數據塊傳輸完成客戶端后告知namenode數據塊傳輸完成,這時候候namenode才會更新元數據信息記錄操作日志。
11. 第1個數據塊傳輸完成后會使用一樣的方式傳輸下面的數據塊直到全部文件上傳完成。
細節:
a.要求和應對是使用RPC的方式,客戶端通過ClientProtocol與namenode通訊,namenode和datanode之間使用DatanodeProtocol交互。在設計上,namenode不會主動發起RPC,而是響應來自客戶端或 datanode 的RPC要求。客戶端和datanode之間是使用socket進行數據傳輸,和namenode之間的交互采取nio封裝的RPC。
b.HDFS有自己的序列化協議。
c.在數據塊傳輸成功后但客戶端沒有告知namenode之前如果namenode宕機那末這個數據塊就會丟失。
d.在流式復制時,逐級傳輸和響應采取響應隊列來等待傳輸結果。隊列響應完成后返回給客戶端。
c.在流式復制時如果有1臺或兩臺(不是全部)沒有復制成功,不影響最后結果,只不過datanode會定期向namenode匯報本身信息。如果發現異常namenode會指揮datanode刪除殘余數據和完善副本。如果副本數量少于某個最小值就會進入安全模式。
客戶端將要讀取的文件路徑發送給namenode,namenode獲得文件的元信息(主要是block的寄存位置信息)返回給客戶端,客戶端根據返回的信息找到相應datanode逐一獲得文件的block并在客戶端本地進行數據追加合并從而取得全部文件。
HDFS讀數據步驟大概可以用以下的流程圖表示:
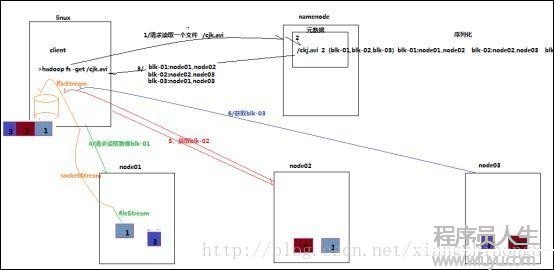
12. 客戶端向namenode發起RPC調用,要求讀取文件數據。
13. namenode檢查文件是不是存在,如果存在則獲得文件的元信息(blockid和對應的datanode列表)。
14. 客戶端收到元信息后選取1個網絡距離最近的datanode,順次要求讀取每一個數據塊。客戶端首先要校檢文件是不是破壞,如果破壞,客戶端會選取另外的datanode要求。
15. datanode與客戶端簡歷socket連接,傳輸對應的數據塊,客戶端收到數據緩存到本地,以后寫入文件。
順次傳輸剩下的數據塊,直到全部文件合并完成。
注:文件合并的問題從某個Datanode獲得的數據塊有多是破壞的,破壞多是由Datanode的存儲裝備毛病、網絡毛病或軟件bug釀成的。HDFS客戶端軟件實現了對HDFS文件內容的校驗和(checksum)檢查。當客戶端創建1個新的HDFS文件,會計算這個文件每一個數據塊的校驗和,并將校驗和作為1個單獨的隱藏文件保存在同1個HDFS名字空間下。當客戶端獲得文件內容后,它會檢驗從Datanode獲得的數據跟相應的校驗和文件中的校驗和是不是匹配,如果不匹配,客戶端可以選擇從其他Datanode獲得該數據塊的副本。
HDFS刪除數據比較流程相對簡單,只列出詳細步驟:
16. 客戶端向namenode發起RPC調用,要求刪除文件。namenode檢查合法性。
17. namenode查詢文件相干元信息,向存儲文件數據塊的datanode發出刪除要求。
18. datanode刪除相干數據塊。返回結果。
19. namenode返回結果給客戶端。
注:當用戶或利用程序刪除某個文件時,這個文件并沒有立刻從HDFS中刪除。實際上,HDFS會將這個文件重命名轉移到/trash目錄。只要文件還在/trash目錄中,該文件就能夠被迅速地恢復。文件在/trash中保存的時間是可配置的,當超過這個時間時,Namenode就會將該文件從名字空間中刪除。刪除文件會使得該文件相干的數據塊被釋放。注意,從用戶刪除文件到HDFS空閑空間的增加上間會有1定時間的延遲。只要被刪除的文件還在/trash目錄中,用戶就能夠恢復這個文件。如果用戶想恢復被刪除的文件,他/她可以閱讀/trash目錄找回該文件。/trash目錄僅僅保存被刪除文件的最后副本。/trash目錄與其他的目錄沒有甚么區分,除1點:在該目錄上HDFS會利用1個特殊策略來自動刪除文件。目前的默許策略是刪除/trash中保存時間超過6小時的文件。將來,這個策略可以通過1個被良好定義的接口配置。
當1個文件的副本系數被減小后,Namenode會選擇多余的副本刪除。下次心跳檢測時會將該信息傳遞給Datanode。Datanode遂即移除相應的數據塊,集群中的空閑空間加大。一樣,在調用setReplication API結束和集群中空閑空間增加間會有1定的延遲。
首先明確namenode的職責:響應客戶端要求、管理元數據。
namenode對元數據有3種存儲方式:內存元數據(NameSystem)、磁盤元數據鏡像文件、數據操作日志文件(可通過日志運算出元數據)
細節:HDFS不合適存儲小文件的緣由,每一個文件都會產生元信息,當小文件多了以后元信息也就多了,對namenode會造成壓力。
3種存儲機制的解釋
內存元數據就是當前namenode正在使用的元數據,是存儲在內存中的。磁盤元數據鏡像文件是內存元數據的鏡像,保存在namenode工作目錄中,它是1個準元數據,作用是在namenode宕機時能夠快速較準確的恢復元數據。稱為fsimage。數據操作日志文件是用來記錄元數據操作的,在每次改動元數據時都會追加日志記錄,如果有完全的日志就能夠還原完全的元數據。主要作用是用來完善fsimage,減少fsimage和內存元數據的差距。稱為editslog。
checkpoint機制分析
由于namenode本身的任務就非常重要,為了不再給namenode壓力,日志合并到fsimage就引入了另外一個角色secondarynamenode。secondarynamenode負責定期把editslog合并到fsimage,“定期”是namenode向secondarynamenode發送RPC要求的,是按時間或日志記錄條數為“間隔”的,這樣即不會浪費合并操作又不會造成fsimage和內存元數據有很大的差距。由于元數據的改變頻率是不固定的。
每隔1段時間,會由secondary namenode將namenode上積累的所有edits和1個最新的fsimage下載到本地,并加載到內存進行merge(這個進程稱為checkpoint)。
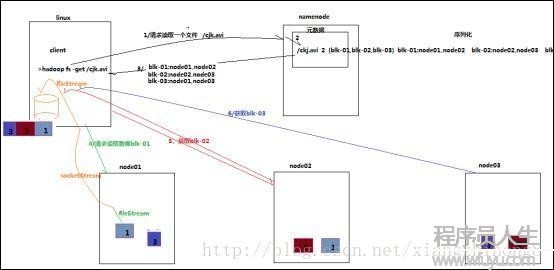
checkpoint步驟:
1. namenode向secondarynamenode發送RPC要求,要求合并editslog到fsimage。
2. secondarynamenode收到要求后從namenode上讀取(通過http服務)editslog(多個,轉動日志文件)和fsimage文件。
3. secondarynamenode會根據拿到的editslog合并到fsimage。構成最新的fsimage文件。(中間有很多步驟,把文件加載到內存,還原成元數據結構,合并,再生成文件,新生成的文件名為fsimage.checkpoint)。
4. secondarynamenode通過http服務把fsimage.checkpoint文件上傳到namenode,并且通過RPC調用把文件改名為fsimage。
namenode和secondary namenode的工作目錄存儲結構完全相同,所以,當namenode故障退出需要重新恢復時,可以從secondary namenode的工作目錄中將fsimage拷貝到namenode的工作目錄,以恢復namenode的元數據。
關于checkpoint操作的配置:
dfs.namenode.checkpoint.check.period=60 #檢查觸發條件是不是滿足的頻率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上兩個參數做checkpoint操作時,secondary namenode的本地工作目錄
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重試次數
dfs.namenode.checkpoint.period=3600 #兩次checkpoint之間的時間間隔3600秒
dfs.namenode.checkpoint.txns=1000000 #兩次checkpoint之間最大的操作記錄editslog和fsimage文件存儲在$dfs.namenode.name.dir/current目錄下,這個目錄可以在hdfs-site.xml中配置的。目錄結果以下:
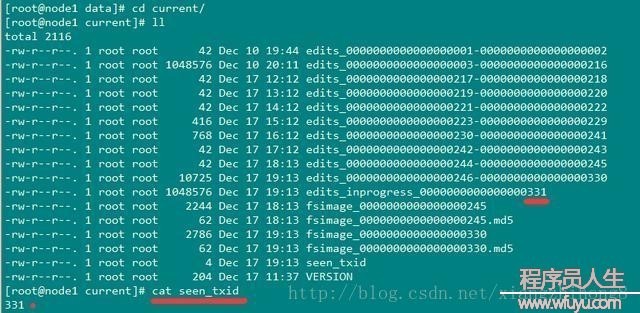
包括edits日志文件(轉動的多個文件),有1個是edits_inprogress_*是當前正在寫的日志。fsimage文件和md5校檢文件。seen_txid是記錄當前轉動序號,代表seen_txid之前的日志都已合并完成。
$dfs.namenode.name.dir/current/seen_txid非常重要,是寄存transactionId的文件,format以后是0,它代表的是namenode里面的edits_*文件的尾數,namenode重啟的時候,會依照seen_txid的數字恢復。所以當你的hdfs產生異常重啟的時候,1定要比對seen_txid內的數字是否是你edits最后的尾數,不然會產生重啟namenode時metaData的資料有缺少,致使誤刪Datanode上過剩Block的信息。安全模式:Namenode啟動后會進入1個稱為安全模式的特殊狀態。處于安全模式的Namenode是不會進行數據塊的復制的。Namenode從所有的 Datanode接收心跳信號和塊狀態報告。塊狀態報告包括了某個Datanode所有的數據塊列表。每一個數據塊都有1個指定的最小副本數。當Namenode檢測確認某個數據塊的副本數目到達這個最小值,那末該數據塊就會被認為是副本安全(safely replicated)的;在1定百分比(這個參數可配置)的數據塊被Namenode檢測確認是安全以后(加上1個額外的30秒等待時間),Namenode將退出安全模式狀態。接下來它會肯定還有哪些數據塊的副本沒有到達指定數目,并將這些數據塊復制到其他Datanode上。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


